Into AI
This Week In AI Research (12–18 April 2026): Ten Papers, Plain English
Dr. Ashish Bamania
Apr 22, 2026
This Week In AI Research (12–18 April 2026): Ten Papers, Plain English
Source: Into AI · Author: Dr. Ashish Bamania · Date: 22 Apr 2026 · Original article

This week's roundup spans the full stack of modern AI: how a popular coding agent is actually built, two big advances in robotics, a giant new multimodal model from Alibaba, two thought-provoking papers about how vision-language models and LLMs really reason, a self-evolving agent framework, a new audio-video generator, an AI scientist for wearable health data, and a system that builds explorable 3D worlds. Below, each one is explained from first principles for a software engineer.
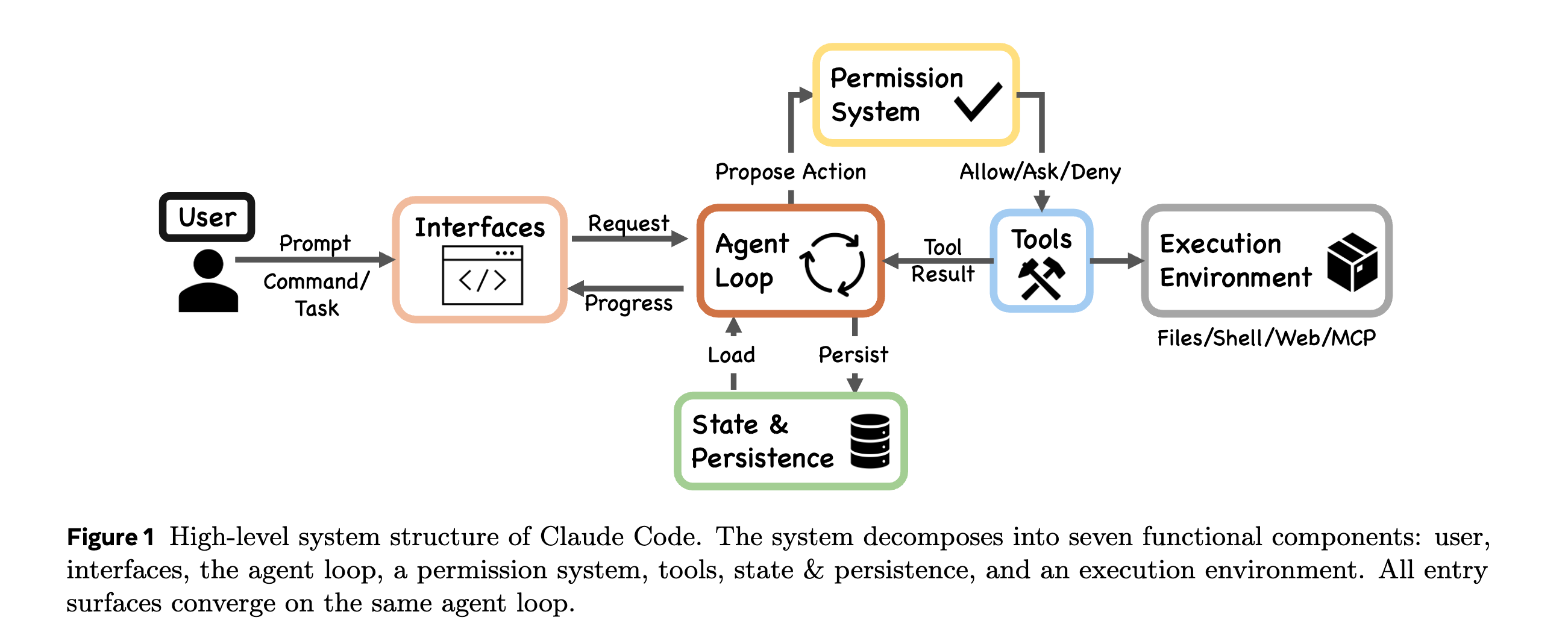
1. Dive into Claude Code — what's actually inside an agentic coding assistant
This paper reverse-engineers Anthropic's Claude Code by reading its publicly available TypeScript source and comparing it against the open-source clone OpenClaw.
The surprising headline: at the center of Claude Code is a tiny while loop — call the model, run any tools the model asked for, feed results back, repeat. That's it. The loop itself is unimpressive; the magic is the scaffolding wrapped around it. Think of the loop as the engine of a car — interesting capabilities come from the chassis, gearbox, brakes, and dashboard built around it.
The paper identifies five such "scaffolding" systems:
- Permission system with seven modes and an ML-based classifier. Rather than one global "allow/deny" toggle, Claude Code has graded permission levels and uses a small machine-learning classifier to judge whether a proposed tool action (e.g. "delete this directory") is risky enough to require user confirmation.
- Five-layer compaction pipeline for context. Long sessions overflow the model's context window. Instead of one summarization step, Claude Code passes the conversation through five progressive stages of compression — keeping recent turns verbatim while older history is increasingly compressed into summaries — so the model still remembers what happened twenty steps ago without paying full token cost.
- Four extensibility mechanisms: MCP, plugins, skills, and hooks. MCP (Model Context Protocol) lets the agent talk to external tools/servers; plugins add commands; skills package domain workflows; hooks fire at lifecycle events. Together they let users extend the agent without forking it.
- Subagent delegation and orchestration. A single agent can spawn specialized sub-agents (e.g. one for searching, one for editing) and coordinate them, which keeps each agent's context focused and cheap.
- Append-oriented session storage. Sessions are stored as an append-only log — closer to a database write-ahead log than a mutable document. Replay is cheap, debugging is easier, and nothing is silently overwritten.
Takeaway for engineers: an "AI agent" is not a clever model. It's a boring loop plus careful infra around permissions, memory, extensibility, and persistence.
2. Gemini Robotics-ER 1.6 — better physical-world reasoning
Google DeepMind's upgrade to its embodied-reasoning model. "ER" stands for embodied reasoning: the model's job is not to chat, but to look at the world through a robot's cameras and decide what to do.
Key improvements:
- Spatial awareness — better at understanding where objects are relative to each other in 3D space.
- Multi-camera scene understanding — can fuse views from several cameras (front, arm-mounted, overhead) into one coherent picture, which is how real robots actually perceive.
- Task completion detection — knowing when a task is done, which sounds trivial but is one of the hardest parts of robotics (otherwise the robot keeps "wiping" a table forever).
- Reading instruments — gauges, thermometers, dials. Useful for inspection robots like Boston Dynamics' Spot patrolling industrial sites.
- Safer physical decisions — recognizing constraints like "don't pick up the hot object" or "don't step on the cable."
Together this nudges general-purpose robots a step closer to operating reliably outside lab demos. Blog post.
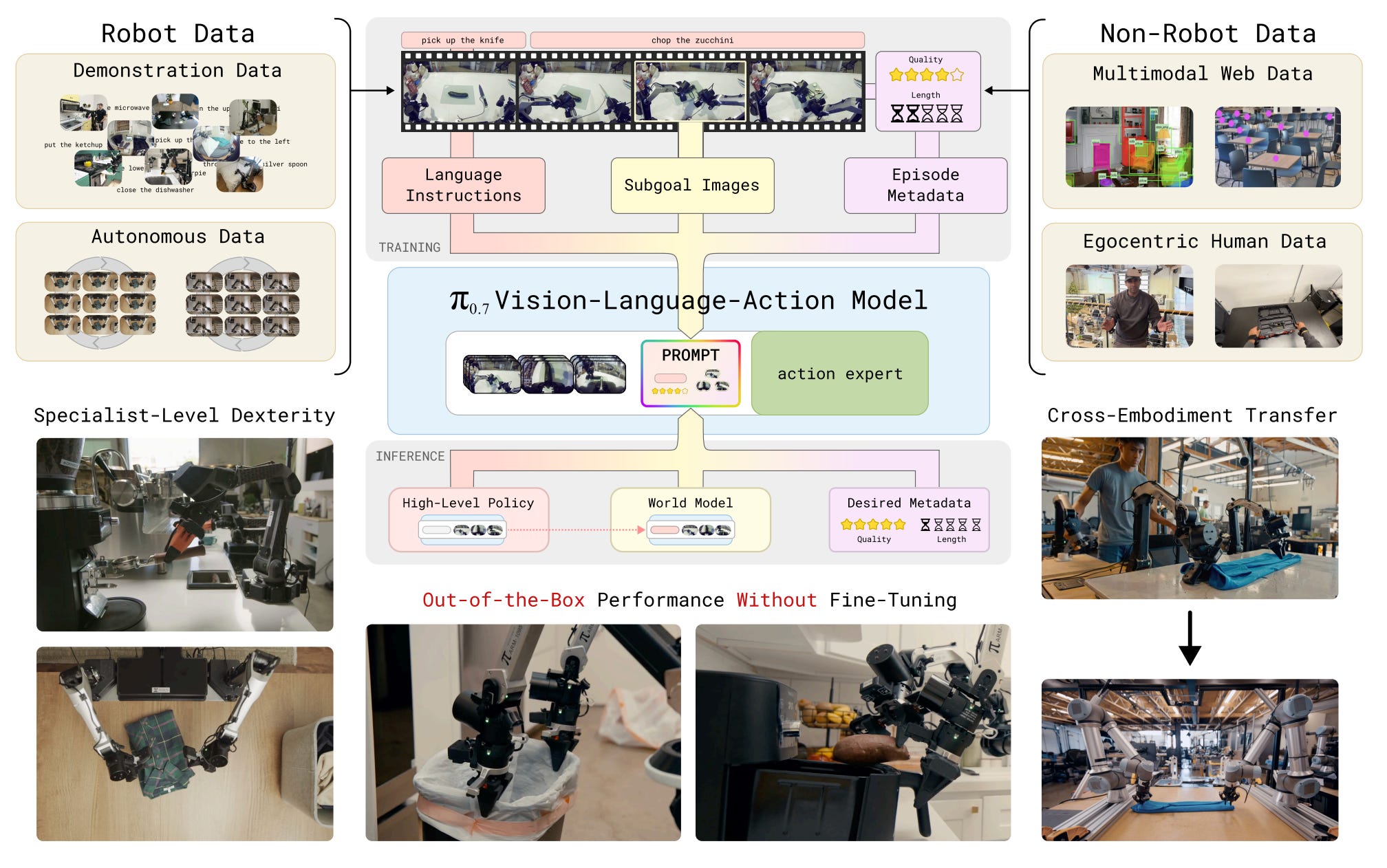
3. π₀.₇ — one robot brain that generalizes across tasks
From Physical Intelligence. The dream in robotics is the equivalent of a "foundation model" for bodies: train once, deploy on any robot doing any task. Today most robot policies are narrow — a model that folds laundry can't pour coffee.
π₀.₇'s core trick is diverse context conditioning during training. Earlier robotic policies were mostly conditioned on a language command ("fold the shirt"). π₀.₇ is also fed:
- Subgoal images — pictures of intermediate states ("here's what the half-folded shirt should look like").
- Task metadata — structured info about the task type.
- Control modes — whether the robot is in fine-manipulation mode, locomotion mode, etc.
- Demonstrations — example trajectories.
By varying which of these are present during training, the model learns to flex its strategy based on whatever context it gets at inference time. It's like teaching a chef using recipes, photos, video clips, and live demos rather than text-only recipes — they end up far more adaptable.
Results: π₀.₇ generalizes to unseen kitchens, can fold laundry on new robot bodies it wasn't trained on, and can run an espresso machine at a level comparable to specialized reinforcement-learning systems trained just for that one task.
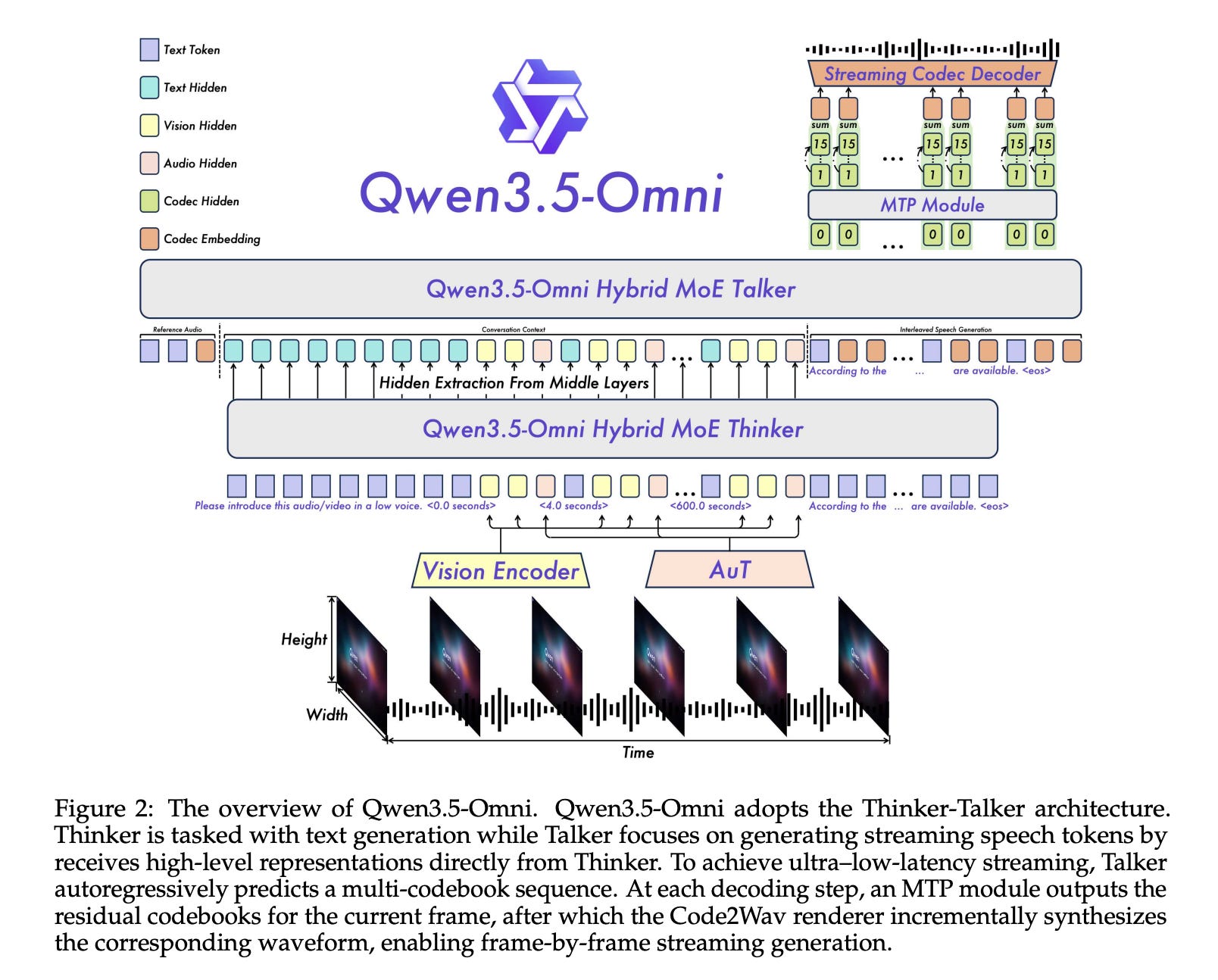
4. Qwen3.5-Omni — Alibaba's any-to-any multimodal model
A single model that takes text, images, audio, and video, and produces text and speech. Hundreds of billions of parameters, 256k-token context window, trained on huge text-image data and 100M+ hours of audio-video.
Several pieces are worth understanding:
- Hybrid Attention Mixture-of-Experts (MoE). MoE means: instead of every parameter participating in every forward pass, the network has many "expert" sub-networks and a router picks a few for each token. That keeps compute manageable on long multimodal sequences. "Hybrid attention" combines different attention patterns (e.g. local vs global) so the model can handle 10+ hours of audio or ~400 seconds of 720p video in one go without quadratic blow-up.
- ARIA — Adaptive Rate Interleave Alignment. Text tokens and speech tokens flow at different natural rates (you say a syllable in ~200 ms; a text token is instantaneous). ARIA aligns the two streams adaptively so the model can converse with low latency and natural prosody, instead of producing robotic, choppy speech.
- 36-language speech, zero-shot voice cloning from short samples, temporal video captioning (describing when things happen, not just what), and scene segmentation.
- "Audio-Visual Vibe Coding" — write code from spoken instructions plus visual references (e.g. a sketch on screen).
The top variant, Qwen3.5-Omni-Plus, leads 215 benchmarks for audio and audio-visual reasoning, beating Gemini 3.1 Pro on several audio tasks and matching it broadly.
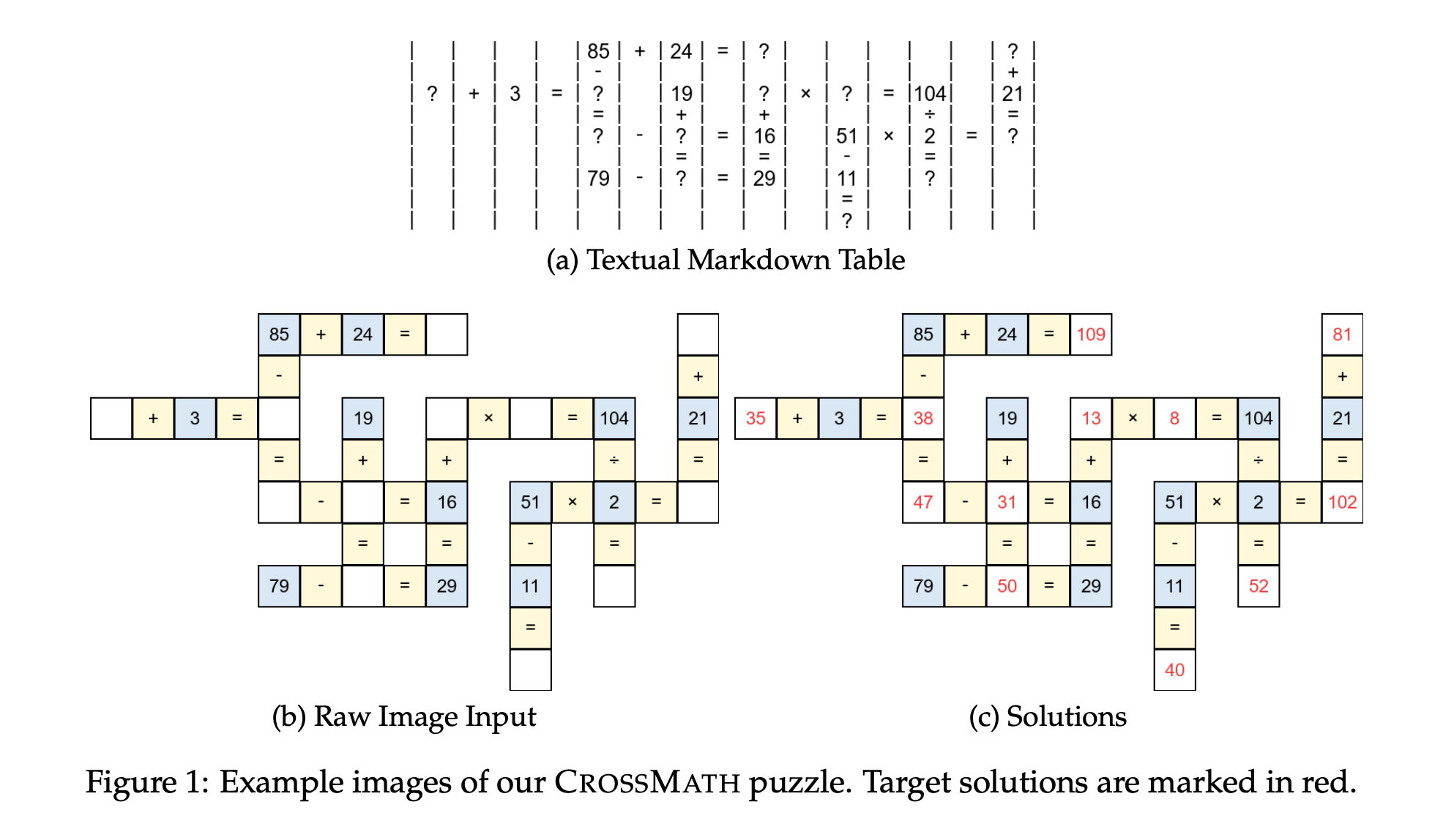
5. Do Vision-Language Models Truly See? — the CrossMath benchmark
A pointed test of how vision-language models (VLMs) actually reason. The authors built CrossMath, where every problem exists in three forms — text-only, image-only, and image+text — all human-verified.
If a VLM truly reasons over the image, then having the image (or image+text) should help. The result is the opposite: top VLMs do best on text-only tasks, and adding the image often hurts performance. The interpretation: today's VLMs are largely thinking through their language pathway and treating the image as a weak hint, not as primary evidence.
Imagine a student who claims to be solving geometry problems by looking at the diagrams, but you discover they're really just reading the problem statement and ignoring the picture — that's the diagnosis here.
Good news: fine-tuning on a curated CrossMath training set materially improved both text and visual reasoning, suggesting the gap is at least partly trainable away rather than a fundamental architectural ceiling.
6. LLM Reasoning Is Latent, Not the Chain of Thought
A position paper that asks: when an LLM gets better at reasoning, where is the reasoning actually happening? Three candidate explanations:
- Hidden internal trajectories — the model reasons in its activations (latent state) and the output text is just a readout.
- Explicit written reasoning — the visible chain-of-thought (CoT) tokens are the reasoning; thinking happens by writing.
- More sequential compute — CoT helps simply because generating more tokens gives the model more forward passes / steps to think, regardless of what those tokens say.
Reviewing recent evidence, the author concludes the strongest support is for (1) the latent-state view: models often reason internally, and the visible CoT is sometimes a post-hoc rationalization rather than a faithful trace. This matters for safety and interpretability — if the printed reasoning isn't the real reasoning, then "let's check the model's chain of thought to verify it's not deceptive" is a flawed safety strategy.
7. Autogenesis — a protocol for self-evolving agents
Today's agentic systems are fragile: they're typically a frozen prompt + frozen toolset + ad-hoc memory. Long-running tasks expose limits in lifecycle management (how do you upgrade an agent that's mid-task?), version tracking, and safe rollback when an "improvement" makes things worse.
The Autogenesis Protocol (AGP) introduces a clean separation:
- What changes — prompts, tools, sub-agents, memory, environments.
- How changes happen — a closed-loop process of propose → evaluate → apply → revert if worse. This is essentially CI/CD for the agent's own internals: the agent suggests a tweak to itself, runs it on benchmarks, and either keeps or reverts based on measured outcomes.
Built on top is the Autogenesis System (AGS), a multi-agent setup that generates and refines its own resources during execution. On planning and tool-use benchmarks, AGS consistently improves over strong static baselines.
The mental model: instead of an agent that runs a fixed program, an agent that edits its own program under safety rails — much like a team that does retros and ships hotfixes, rather than one that ships once and prays.
8. Seedance 2.0 — synchronized audio + video generation
A native multimodal generator that produces video and matching audio together from any combination of text, images, audio, or reference video. Earlier systems generated video first and dubbed audio in a second pass, which often led to lip-sync drift and unrelated soundscapes; Seedance 2.0 generates both jointly so they line up naturally.
It produces 4–15-second clips at 480p or 720p, supports multi-input editing (combine multiple reference videos/images/audio clips), and ships a Seedance 2.0 Fast variant tuned for low-latency use cases like interactive apps.
9. CoDaS — an AI co-data-scientist for wearable health data
CoDaS is a multi-agent system that automates the full data-science workflow for finding biomarkers (measurable signals that correlate with a disease or condition) from wearable-sensor data — sleep, activity, heart rate.
Discovery is structured as an iterative loop:
- Generate hypotheses ("maybe disrupted circadian rhythm correlates with depression").
- Run statistical tests on the data.
- Validate on held-out subsets.
- Cross-check against published literature so it isn't reinventing wheels or chasing spurious correlations.
- Loop in a human reviewer at decision points.
Applied to a study of 9,279 participants, CoDaS surfaced concrete leads — for instance, links between depression and irregular sleep / disrupted circadian rhythms, and between insulin resistance and a fitness index built from step counts plus resting heart rate. The framing is important: it's not replacing the data scientist, it's pairing with one — accelerating the cycle of "wonder → test → verify → write up."
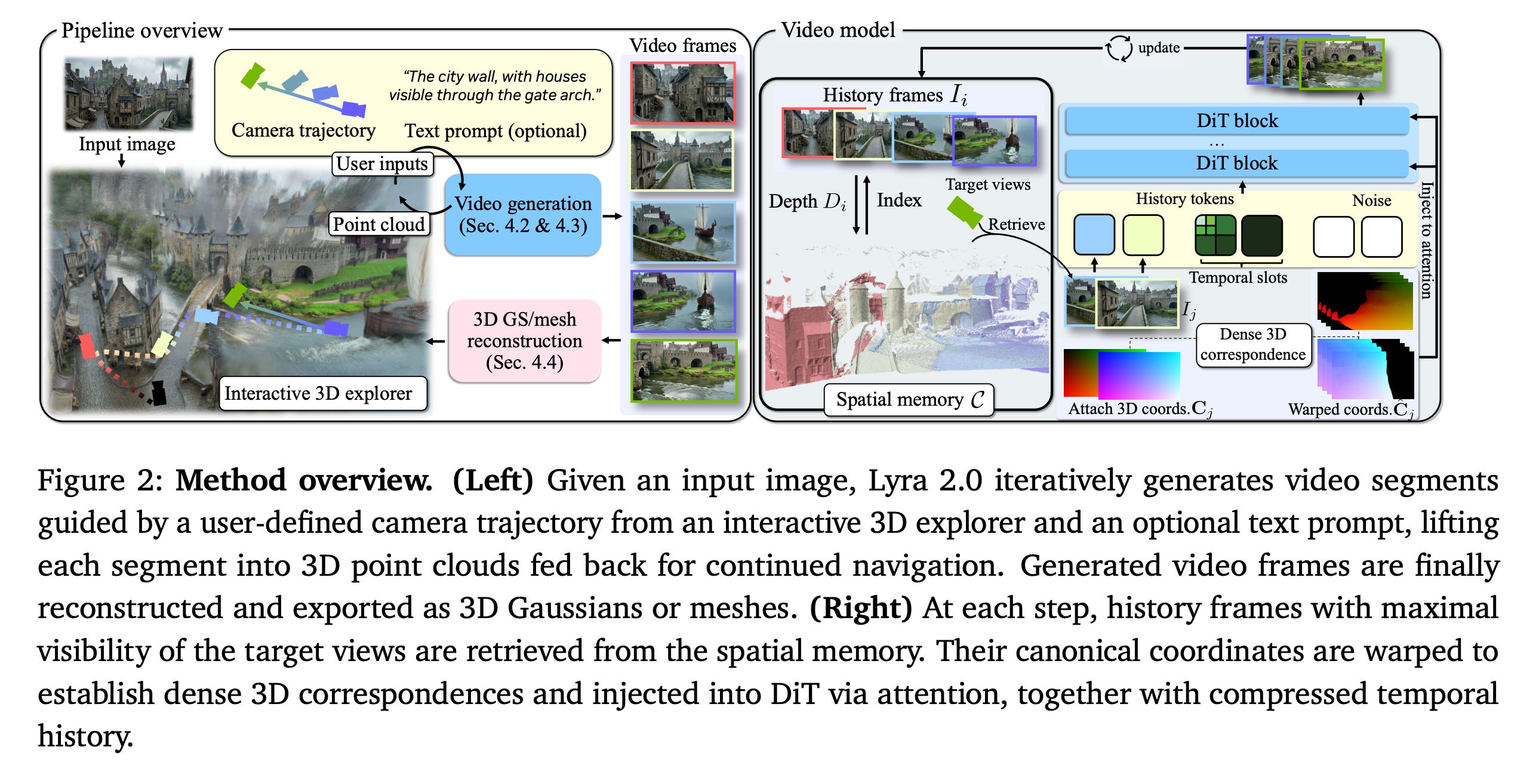
10. Lyra 2.0 — explorable, persistent generative 3D worlds
Lyra 2.0 builds AI-generated 3D environments you can actually walk around in, in real time. It works in two stages: first generate a camera-controlled walkthrough video of the imagined world, then convert that video into a real-time 3D scene.
The hard problem is consistency over long paths. Two failure modes plague video-based world models:
- Spatial forgetting — you turn around and the room you just saw has silently changed (different paintings, different chair).
- Temporal drift — small errors accumulate frame by frame; after a minute, the world has visibly degraded.
Lyra 2.0's fix is twofold:
- Recover 3D geometry as it goes and use that geometry to retrieve relevant past views — so when you turn around, the model is conditioned on what was actually there, not on a fading memory.
- Train the model to repair its own degraded outputs — explicitly showing it bad frames during training and teaching it to clean them up, which keeps long generations from collapsing.
The result: longer, coherent generated worlds usable for gaming, simulation, and training robots in synthetic environments.
Themes for the week
- Agents are infrastructure, not models. Both Claude Code (#1) and Autogenesis (#7) reinforce that the interesting frontier is permissions, memory, lifecycle, and self-update — not the underlying LLM.
- Multimodality is going native. Qwen3.5-Omni (#4) and Seedance 2.0 (#8) generate across modalities in one model rather than stitching modality-specific models together.
- We may be over-trusting what models say they're doing. Both the CrossMath result (#5) and the latent-reasoning paper (#6) suggest that visible reasoning — whether a chain-of-thought or "I looked at the image" — can be misleading.
- Robotics generalization is real. π₀.₇ (#3) and Gemini Robotics-ER 1.6 (#2) move robot foundation models closer to "train once, deploy widely."
- Worlds and sciences as outputs. Lyra 2.0 (#10) generates explorable spaces; CoDaS (#9) generates scientific findings. The output of AI is increasingly not just text, but environments and discoveries.
Author
Dr. Ashish Bamania
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m