Level Up Coding System Design Newsletter
Redis Clearly Explained: The Performance Layer That Quietly Holds Modern Systems Together
Nikki Siapno
Apr 21, 2026
Redis Clearly Explained: The Performance Layer That Quietly Holds Modern Systems Together
Source: Level Up Coding System Design Newsletter · Author: Nikki Siapno · Date: Apr 21, 2026 · Original article
Why Redis exists in the first place
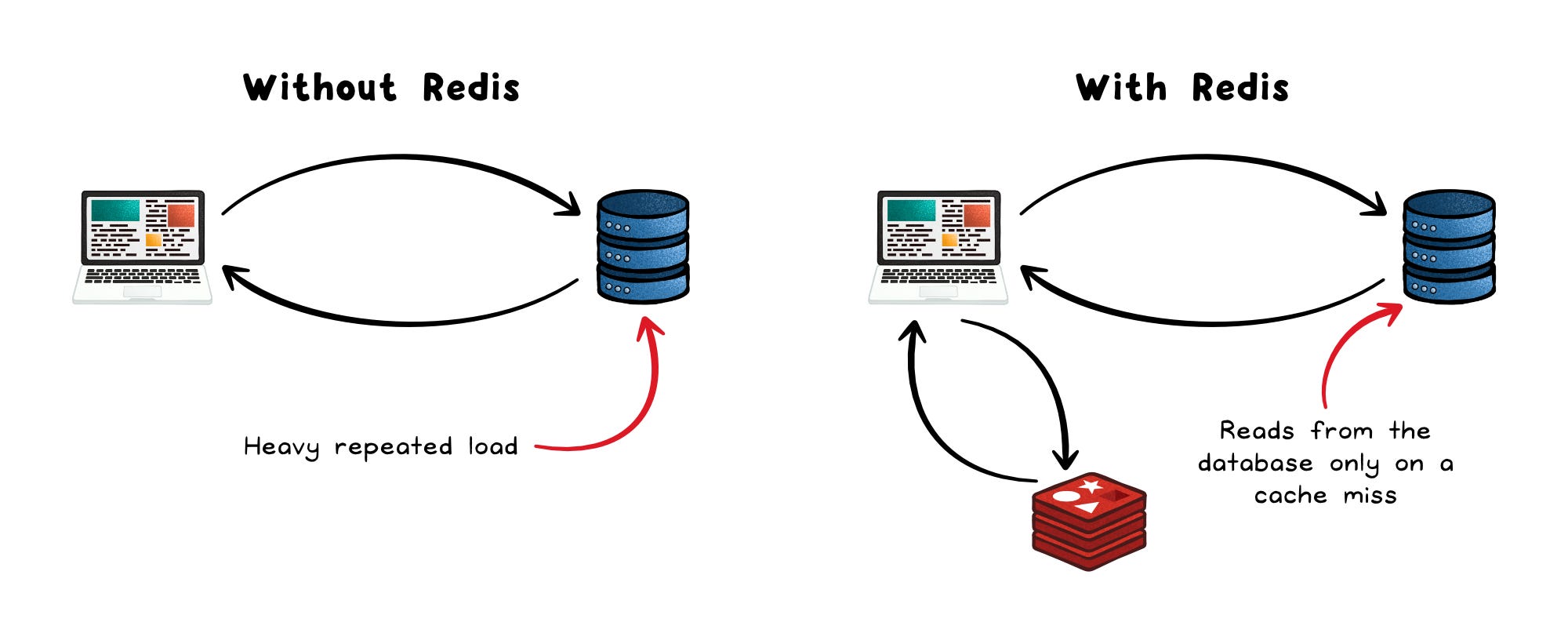
Picture a system where the database is genuinely well-built: queries are optimized, indexes are in place, schemas are clean. And yet, under real production load, things still slow down. Why?
The bottleneck usually isn't the database itself — it's that the application is forcing the database to answer the same questions over and over again, thousands of times per second. Every page load asks "who is this user?", every API call asks "what are the current pricing tiers?", every dashboard re-renders the same top-10 list. Each individual query is fast, but the cumulative weight crushes throughput.
Redis is what shows up at the edge of the system to absorb that pressure. It quietly handles sessions, caches expensive responses, tracks rate limits, and moves messages between services — taking the repetitive, hot-path work off the primary database so that the database can focus on what only it can do.
How Redis works under the hood
At its core, Redis is an in-memory key–value store. Everything lives in RAM, which is why reads and writes happen in microseconds instead of the milliseconds you'd see with a disk-backed database.
But calling it just "key-value" undersells it. The values in Redis aren't limited to plain strings — Redis ships with a rich set of built-in data structures, each with commands that operate directly on the data inside Redis:
- Strings — the simplest value type. Used for counters (e.g., view counts), feature flags, or cached blobs of JSON/HTML.
- Hashes — field-to-value maps inside a single key. Perfect for things like a user profile (
user:42→{name, email, plan}) or session data, where you want to update one field without rewriting the whole object. - Lists — ordered sequences. Used for FIFO queues, recent-activity feeds, or any "log of things in order."
- Sets and Sorted Sets — collections of unique elements. Sorted Sets attach a numeric score to each element, which makes them the natural fit for leaderboards (highest score first) or tag systems (deduplicated tag lists).
Why does this matter? Because instead of pulling raw data into your application and processing it there, Redis lets you compute inside the store. Compare:
- ❌ "Fetch every score from the database, then sort them in Python to find the top 10."
- ✅ "Ask Redis directly: give me the top 10 from this Sorted Set."
The second one is one network round trip and a constant-time-ish operation. The first one is a lot of bytes moving around for nothing.
Execution model: single-threaded on purpose
Redis runs on a single-threaded event loop. Only one command executes at a time.
That sounds like it should be a scalability disaster, but it's actually a deliberate trade-off:
- No locking. No mutexes. No race conditions on shared structures.
- Every individual operation is atomic by construction —
INCR,LPUSH,ZADDeither fully happen or don't, with no partial states. - The work per operation is tiny and predictable, so a single CPU core can chew through enormous throughput before saturating.
In other words, Redis dodges the entire class of bugs that comes with concurrent shared-memory programming, and pays for it with a constraint (one command at a time) that rarely matters because each command is so fast.
Persistence: optional, but you choose how much
A common misconception: "Redis is in-memory, so I'll lose everything on a crash." Not necessarily. Redis offers two persistence modes you can mix and match:
- RDB snapshots — Redis periodically dumps the entire dataset to disk (e.g., every few minutes). Fast and compact, but if Redis dies between snapshots, you lose anything written since the last one.
- AOF (Append-Only File) logs — Every write command is appended to a log file. On restart, Redis replays the log to rebuild state. Much more durable, but adds I/O overhead on every write.
The point is durability is a dial, not a switch. Faster setups (RDB-only, or no persistence at all) risk losing recent writes; safer setups (AOF with frequent fsyncs) cost you some throughput. You pick the spot on the curve that matches what your data is worth.
Where Redis actually shines
Redis isn't a general-purpose database replacement. It's a performance layer that solves a small number of problems extremely well. Four use cases dominate.
1. Caching
This is the most common use of Redis, and the reason most teams adopt it first.
The pattern is simple: the application checks Redis before going to the primary database.
- Cache hit → data returns in microseconds. Done.
- Cache miss → the app queries the primary database, returns the result, and also writes it into Redis so the next request hits the cache.
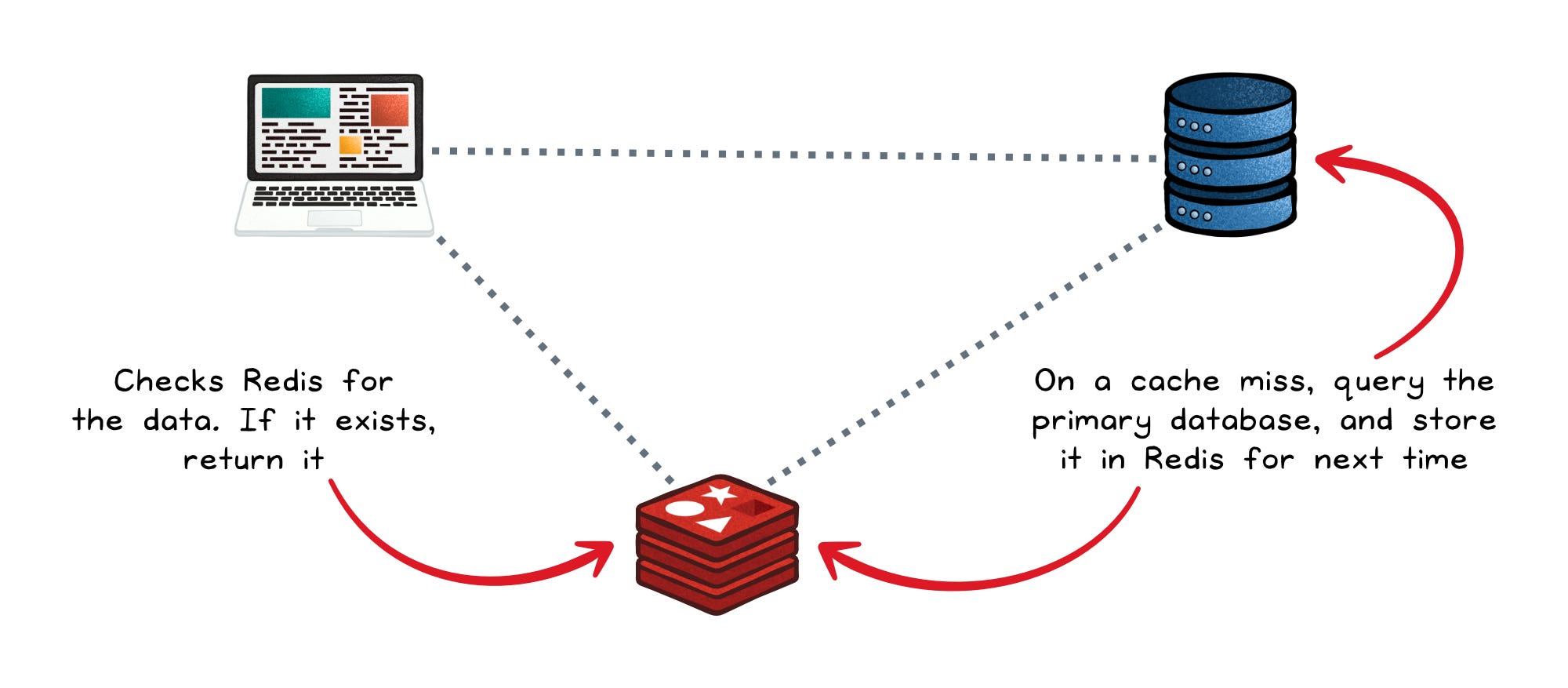
The primary database remains the source of truth. Redis is just sitting on the hot path, intercepting traffic for the data that gets requested again and again.
This pattern works especially well for:
- Expensive query results (think: dashboards aggregating millions of rows).
- API responses from slow upstream services.
- Rendered HTML fragments.
- Any data that is read far more often than it changes.
The wins compound:
- Faster responses — microseconds instead of milliseconds.
- Lower DB load — the database stops re-answering the same question.
- Better scalability — sudden traffic spikes get absorbed by Redis instead of melting your primary store.
A well-placed cache can cut database traffic dramatically — sometimes by an order of magnitude.
2. Session storage
Every authenticated request needs to look up "who is this user, and what are they allowed to do?" — usually keyed by a session token in a cookie. That lookup happens on every single request.
Storing sessions in your main relational database works, but it's wasteful: it puts a high-volume, low-value workload in the same place as your business data. Redis is a much better home because:
- Low latency — session lookup adds microseconds, not milliseconds, to each request.
- TTL (time-to-live) support — you can set a key to expire automatically (e.g., "this session dies in 24 hours"). No cleanup job, no cron, Redis just deletes it.
- High throughput — even at huge user counts, Redis keeps up.
The session store sits close to the application and stays out of the way of the real database.
3. Rate limiting
Rate limiting boils down to: "count how many requests this user/API key has made in the last N minutes, and reject them past some threshold."
Redis makes this almost trivial because of two properties:
- Atomic operations like
INCR(increment a counter). - TTLs on keys (e.g., the counter for
user:123expires after 10 minutes, automatically resetting the window).
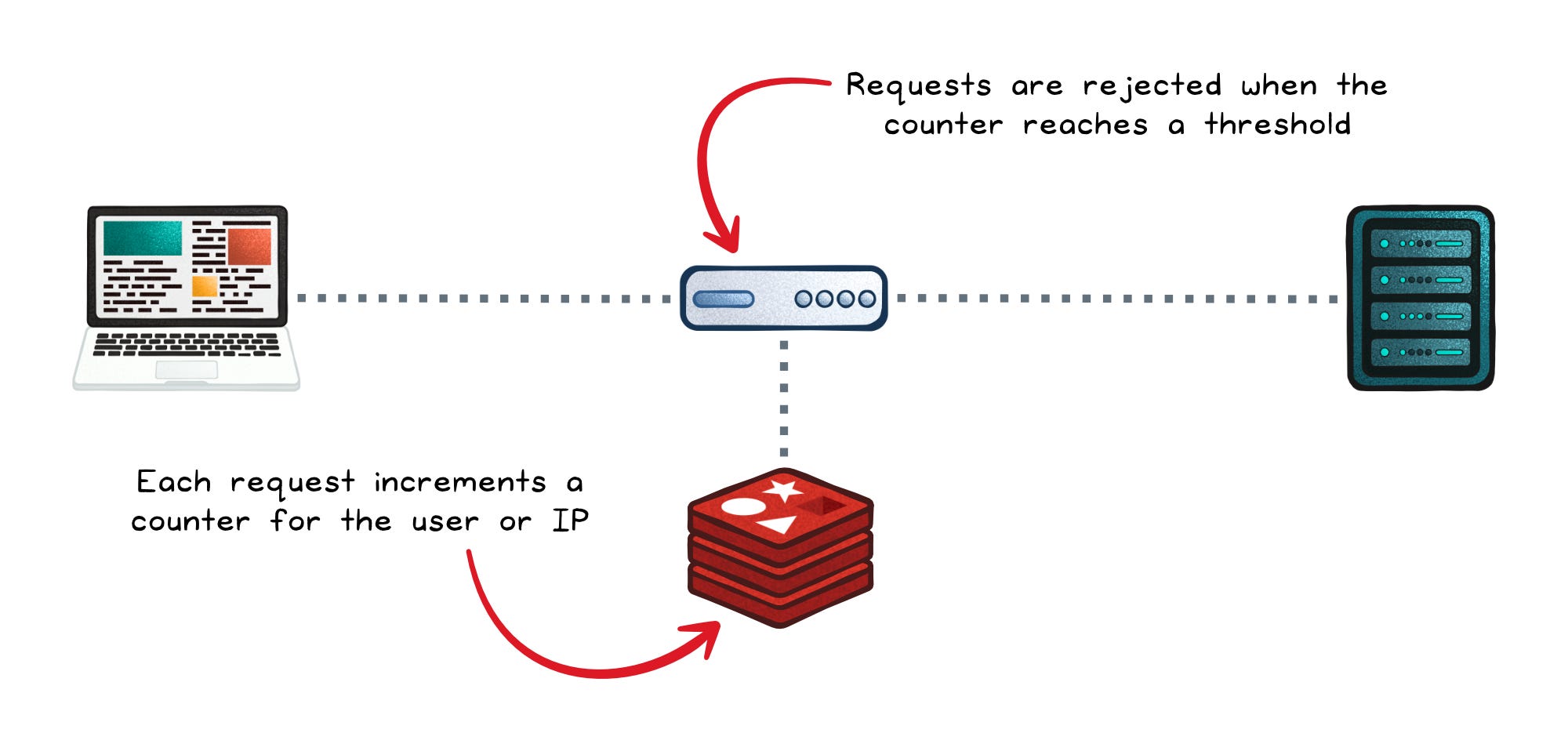
The flow per request:
INCR rate:user:123— atomically increase the counter.- If it's the first time, set the TTL (e.g., 10 minutes).
- If the value exceeds the threshold, reject the request.
Because the whole thing is atomic and in-memory, it adds essentially zero latency to the request path. That's why rate limiters in API gateways are so often built on Redis — you can sit it in front of an entire fleet of services and have a single shared counter that everyone respects.
4. Pub/Sub and queues
Redis ships with a built-in publish/subscribe mechanism. One service publishes a message to a channel; every subscriber listening on that channel receives it in real time. It's a fire-and-forget broadcast, useful for things like cache invalidation events or live UI updates.
For workloads where messages must not be dropped, Redis offers more durable options:
- Lists can act as simple FIFO queues (
LPUSHto enqueue,BRPOPto block-and-dequeue from a worker). - Streams are a more sophisticated, log-like structure with consumer groups (so multiple workers can split up the work) and persistence (messages stick around even after they're read).
This is "good enough" messaging. You won't get the durability guarantees, partitioning, or replay semantics of Kafka, or the routing flexibility of RabbitMQ — but for a lot of internal workloads, Redis Streams cover the need without the operational weight of a dedicated broker.
Benefits vs trade-offs at a glance
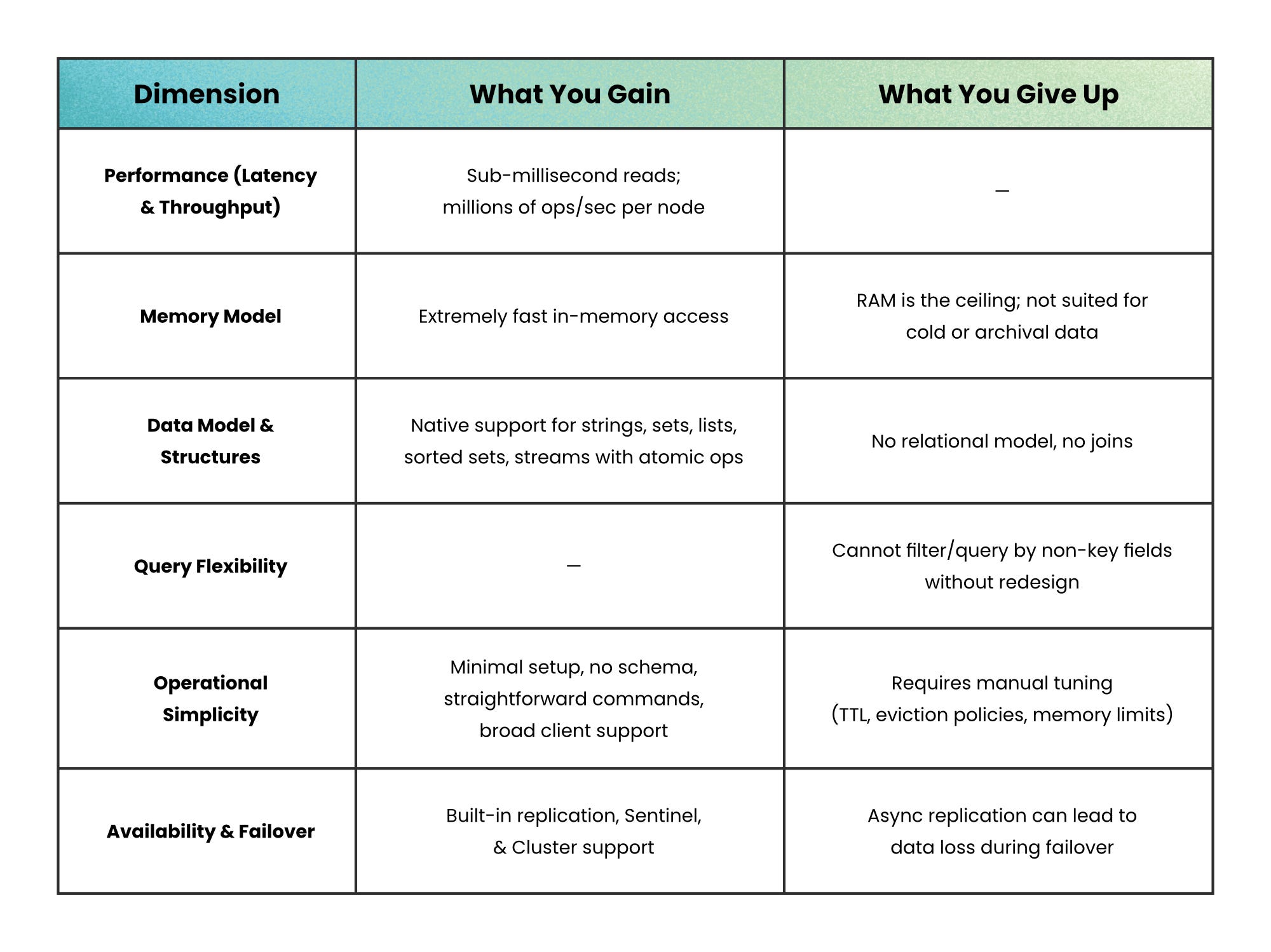
The headline benefits — speed, rich data structures, atomicity, TTLs — come with real costs: RAM is expensive, durability needs to be configured deliberately, and Redis isn't built for complex queries or huge cold datasets.
Where Redis fits in the stack
Redis complements a primary database. It doesn't replace it.
In a typical web app: your relational database (Postgres, MySQL) holds the source of truth. Redis sits in front for caching, sessions, and rate limits.
In a microservices architecture, Redis often plays a second, broader role: a shared fast datastore that multiple services can hit. Concretely:
- A central session store that every frontend service reads from, so a user logged in via one service is recognized by all of them.
- A rate limiter that every API gateway respects in unison, preventing a user from bypassing limits by hitting different entry points.
- A lightweight message broker that connects services without dragging in the operational weight of Kafka or RabbitMQ.
Most teams don't actually run Redis themselves anymore. Cloud providers all offer managed versions: AWS ElastiCache, Azure Cache for Redis, and Google Cloud Memorystore. They handle provisioning, scaling, replication, and failover for you, which makes adding Redis to an existing stack a low-friction decision.
When NOT to use Redis
Redis is a sharp tool, and like any sharp tool it can hurt you if used in the wrong place. Skip Redis when:
- Your dataset is large and cold. RAM is dramatically more expensive per GB than disk. Putting a 10TB archive into Redis would cost a fortune and waste 99% of that memory on data nobody is asking for. The right move is a disk-based store as the primary, and Redis only for the small, hot subset that's actually queried frequently.
- You need complex queries. Redis retrieves by key. It does not scan, it does not join, it does not do "find all users from Region A who purchased Product B in the last 30 days, sorted by spend." That's relational-database territory. Forcing those queries into Redis means rebuilding query engines on top of key lookups — a road that ends badly.
- You need strong durability guarantees. If losing even a few seconds of writes is unacceptable — financial transactions, medical records, audit logs — Redis's persistence model has to be configured very carefully, and even then, a fully ACID-compliant database is the safer default. Use Redis as an accelerator alongside it, not as the system of record.
- Your workload is stateless and simple. If you don't need caching, don't need sessions, and don't need messaging, then adding Redis is just one more thing to deploy, monitor, secure, and pay for. Operational complexity without a proportional benefit.
The takeaway
The clearest mental model: Redis is a performance multiplier, not a database replacement.
It doesn't try to solve everything. It solves a narrow set of problems — caching, sessions, rate limiting, lightweight messaging — extremely well. That focused scope is exactly why it ends up everywhere in modern stacks.
Used correctly, Redis turns slow paths into fast ones and fragile systems into responsive ones. Used blindly — as a database replacement, as a durable store of record, as a place to dump cold data — it becomes an expensive, leaky abstraction that papers over architectural problems instead of solving them.
The skill isn't knowing Redis exists. It's knowing exactly which slice of your system belongs in it.
Author
Nikki Siapno
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m