Level Up Coding System Design Newsletter
Infrastructure as Code Clearly Explained
Nikki Siapno
Apr 27, 2026
Infrastructure as Code Clearly Explained
Source: Level Up Coding System Design Newsletter · Author: Nikki Siapno · Date: 2026-04-27 · Original article

The opening question
Can you rebuild your entire production environment from scratch today? Not approximately. Not "close enough." Exactly as-is.
If your answer is "no," your infrastructure is held together by tribal knowledge (what's in someone's head), console history (clicks made months ago in the AWS UI), or luck. Infrastructure as Code (IaC) replaces all three with versioned, reviewable text files that can be applied repeatedly with predictable results.
What IaC actually means
IaC is the practice of defining infrastructure in machine-readable files instead of clicking around in cloud consoles or running ad-hoc shell scripts. It splits into two closely related disciplines:
- Provisioning IaC — defines cloud resources: networks (VPCs, subnets), IAM roles, compute instances (EC2, VMs), managed services (RDS, S3 buckets). Tools: Terraform, CloudFormation, Pulumi.
- Configuration IaC — defines the desired state inside machines and services: which packages are installed, which files exist, system settings. Tools: Ansible, Chef, Puppet.
A useful mental model: provisioning creates the building; configuration furnishes and maintains it.
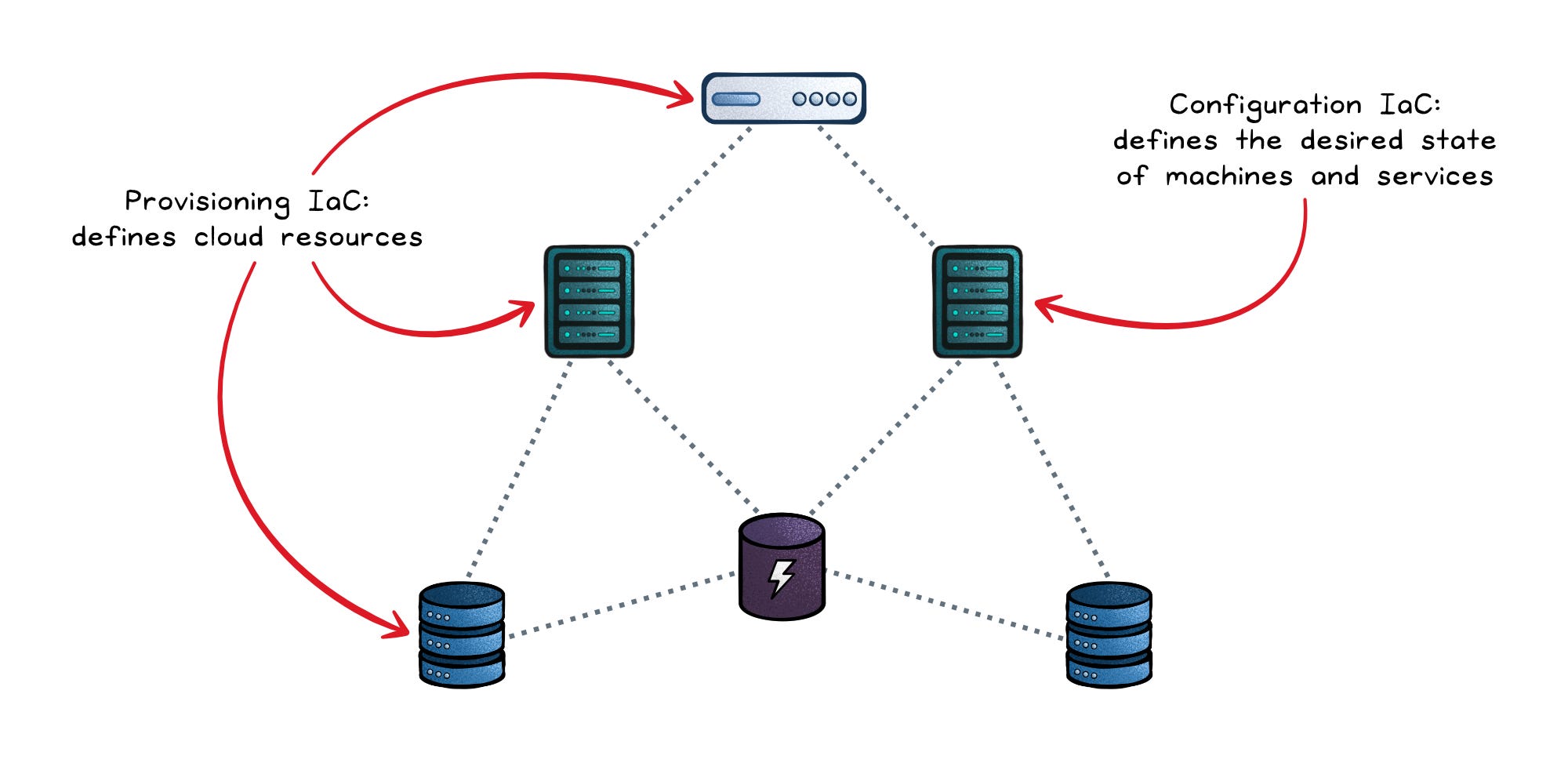
Both share the same core idea: desired state and convergence. You declare what should exist, and the tool figures out the steps to make reality match. Infrastructure stops being something you "set up" once and becomes something you declare, review, and reapply — like code.
Why it matters in practice
The benefits flow directly from treating infra like source code:
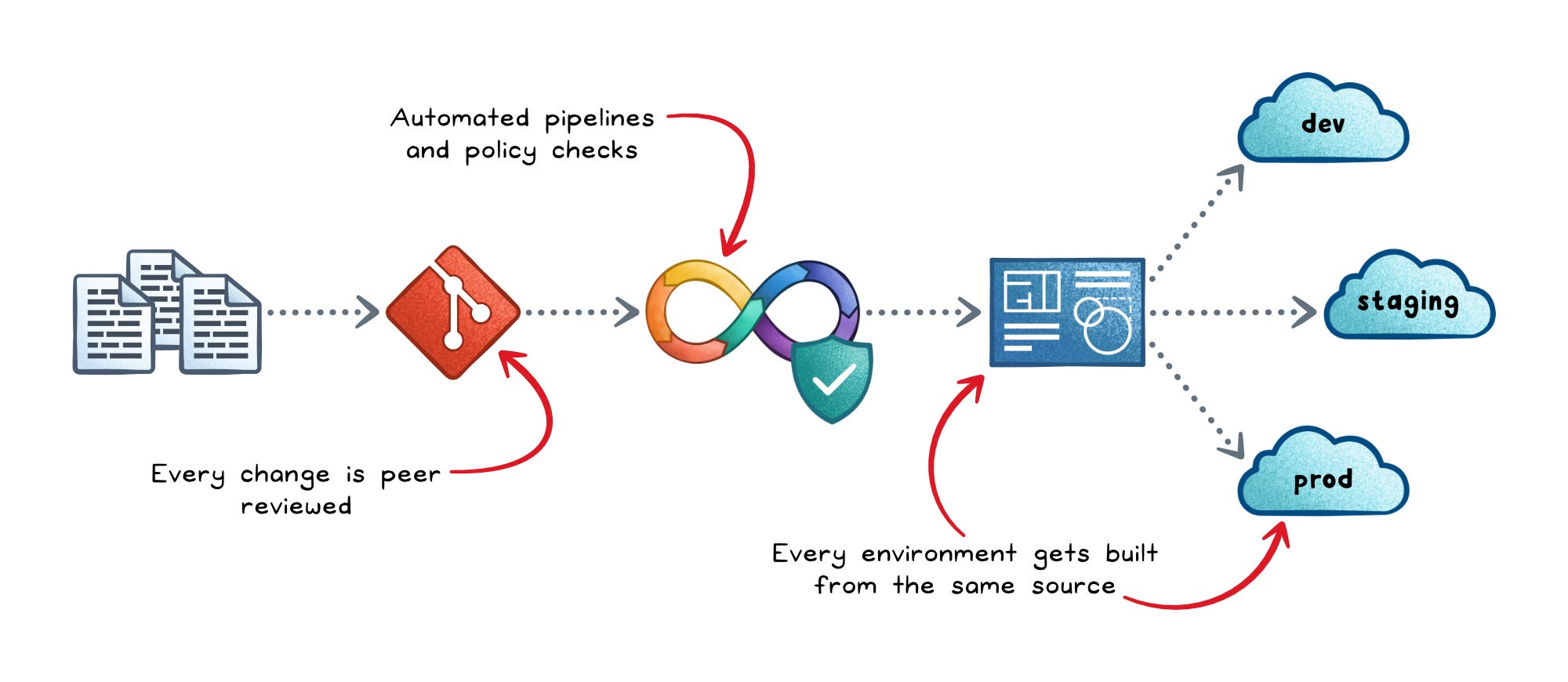
- Reproducibility — every environment (dev, staging, prod) is built from the same source files. The "works on my machine" problem disappears at the infrastructure level too: if staging works, prod will work, because they were built from the same definition.
- Auditability — every change goes through Git and peer review. You can answer "who changed the production security group last Tuesday and why?" by looking at a commit.
- Faster, safer delivery — automated pipelines with preview steps (showing what will change before it changes) replace manual deploys. Teams ship more often and with less risk because the dangerous part — applying changes — is consistent and reviewable.
- Scalable governance — policy checks (e.g., "no public S3 buckets," "all volumes encrypted") run before anything is provisioned. Compliance is enforced automatically, not audited months later.
Without IaC, environments drift: each one accumulates tiny manual tweaks that nobody documents. That invisible divergence is the root cause of a huge class of production incidents — bugs that only appear in prod because prod is subtly different from staging.
Choosing a tool
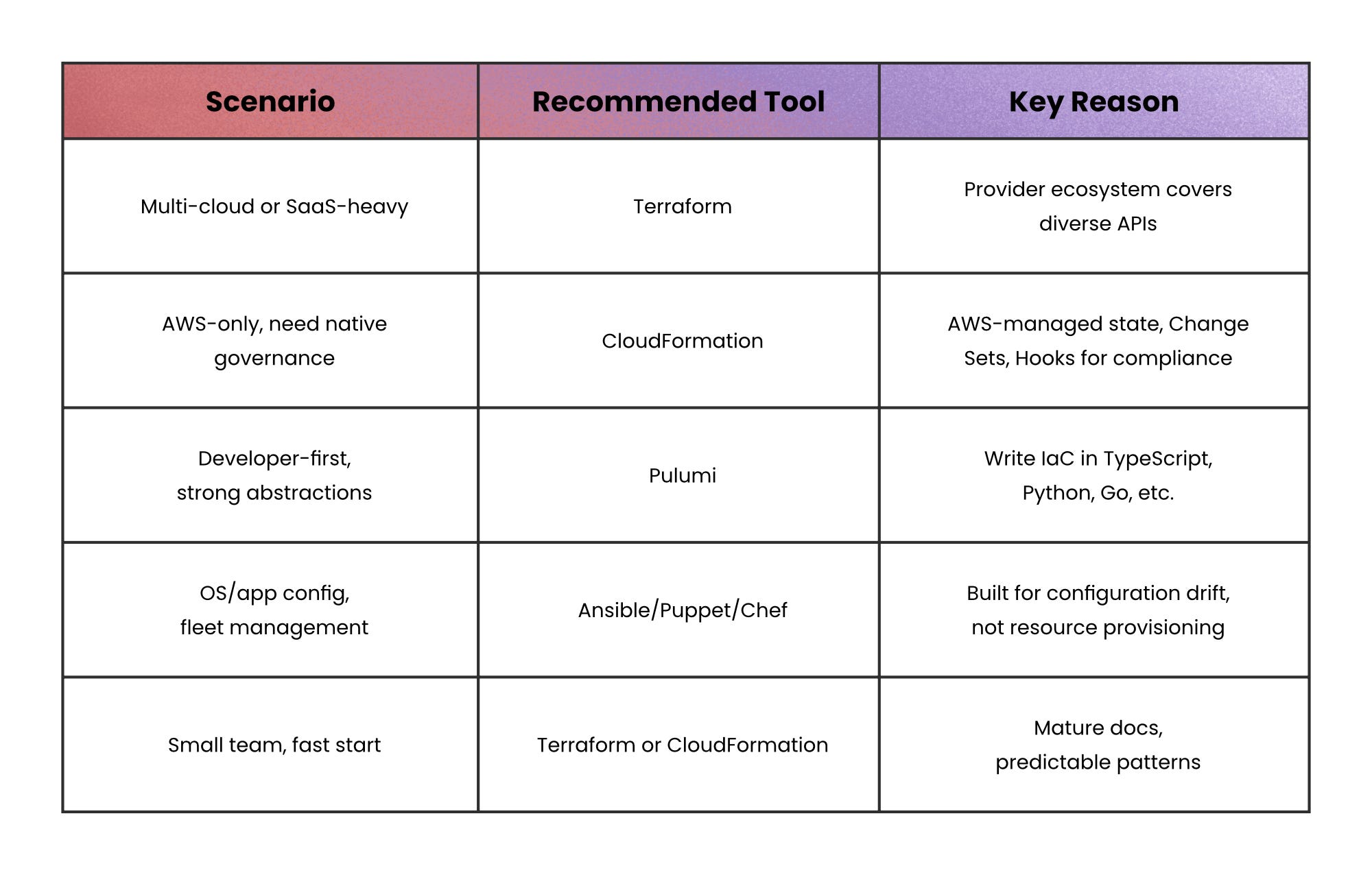
The right tool depends more on your context than on which is "best." A common pattern in larger orgs:
- Terraform or CloudFormation for provisioning cloud resources.
- Ansible for OS hardening, package installation, and app-level configuration on top of those resources.
- Pulumi is an alternative when teams prefer real programming languages (TypeScript, Python, Go) over a domain-specific language like Terraform's HCL.
The IaC workflow that actually works
Most IaC failures don't come from broken syntax — they come from skipping validation, review, or safe rollout. A robust pipeline has 11 stages:
- Developer pushes IaC to Git — Git becomes the single source of truth for networks, databases, IAM, etc.
- CI runs validation — formatting, syntax checks, linting, dependency checks. Catches dumb mistakes before anything else runs.
- Security & policy checks — misconfiguration scanners (e.g., Checkov, tfsec) and policy-as-code (e.g., OPA, Sentinel) catch risky permissions and unsafe defaults early.
- A preview ("plan") is generated — the tool diffs desired state vs current state and shows exactly what will be created, updated, or deleted. This is the single most important safety feature in IaC.
- Peer review and approval — engineers review both the code and the plan. The plan is where you spot accidental deletions, surprise resource replacements, cost spikes, or overly broad IAM grants.
- Apply via deployment pipeline — a trusted CI/CD runner (not a human laptop) executes the change, with controlled credentials.
- Environment-specific config injected — the same code is reused across dev/staging/prod; only variables and state differ.
- Post-deploy checks — smoke tests, connectivity checks, monitoring validation. Confirm the system actually works after the change.
- Environment rollout — promote dev → staging → prod with increasing approval gates.
- State updated — the IaC tool persists what now exists so future runs know what to diff against.
- Continuous drift detection — scheduled jobs check whether real infrastructure still matches the code, and alert when it doesn't.
The simple framing: you declare what you want, the pipeline proves it's safe, and automation makes it real — consistently, every time.
Security risks you can't ignore
IaC failures tend to be systemic: a fast pipeline amplifies a single mistake across the whole fleet quickly. Three risk categories dominate:
1. Secrets exposure
Sensitive data (passwords, API keys, certs) leaking through code, state files, logs, or CI output. Terraform state, in particular, often contains plaintext secrets — committing it to Git is a classic disaster.
Prevent it: use a secret manager (AWS Secrets Manager, Vault), encrypt state at rest, never hardcode secrets, enforce least-privilege access to state and pipelines.
2. Over-privileged automation
CI/CD pipelines often get broad cloud permissions "just to make it work." If that pipeline is compromised, so is everything it can touch.
Prevent it: separate preview roles (read-only, can run plan) from apply roles (can mutate). Scope permissions per environment — the dev runner should never be able to touch prod. Enforce least privilege ruthlessly.
3. Supply chain integrity
IaC pulls in external modules, templates, and provider plugins. If any of those are tampered with, malicious code lands in your infrastructure quietly.
Prevent it: pin versions, verify checksums/signatures, and review third-party modules before adoption. Without pinning, your infra effectively depends on whatever the upstream maintainer pushes today.
When not to use full IaC automation
IaC is almost always worth adopting, but the level of automation should match your team's maturity:
- Apply-on-merge (fully automated) makes sense only when you have strong test coverage, good observability, and practiced runbooks. Without those foundations, automation just moves you in the wrong direction faster.
- For small prototypes or rarely-changed legacy systems, version-controlled templates with manual apply still deliver most of the value: reproducibility, auditability, and reviewable changes — without the operational overhead of a full pipeline.
Pitfalls teams hit first
A few failure patterns show up reliably for teams adopting IaC:
- State mishandling — storing Terraform state locally on a laptop, or worse, committing it to source control. This causes conflicts and leaks secrets. Use a remote backend (S3 + DynamoDB lock, Terraform Cloud) with locking from day one.
- Configuration drift — someone fixes a prod incident via the console at 2am. Now reality and code disagree. Establish a hard norm: no manual change without a follow-up PR. Run drift detection on a schedule so the gap can't go unnoticed.
- Unsafe changes — innocuous-looking template edits can silently force a resource replacement (e.g., changing a database name destroys and recreates the DB). Preview gates and policy-as-code catch these before they hit prod.
- Skipping validation — treating IaC as "just YAML/HCL" and skipping linting/formatting in CI. The debt compounds fast and makes the codebase unmaintainable.
Recap
IaC is not a tool you adopt; it's a discipline you commit to. Terraform, CloudFormation, Pulumi, Ansible — they're all expressions of a single idea: infrastructure should be reproducible, reviewable, and automatable by default.
Practical adoption order:
- Start with version control and validation — get infra into Git with CI checks.
- Add preview gates before you automate applies — never apply without seeing the plan.
- Lock down secrets and pipeline permissions early — least privilege is much harder to retrofit.
When IaC is done well, provisioning a new environment should feel like merging a pull request — not like defusing a bomb.
Author
Nikki Siapno
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m