ByteByteGo Newsletter
How Amazon Uses LLMs to Recommend Products: Inside COSMO, the Commonsense Knowledge Graph
ByteByteGo
Apr 27, 2026
How Amazon Uses LLMs to Recommend Products: Inside COSMO, the Commonsense Knowledge Graph
Source: ByteByteGo Newsletter · Author: ByteByteGo · Date: April 27, 2026 · Original article
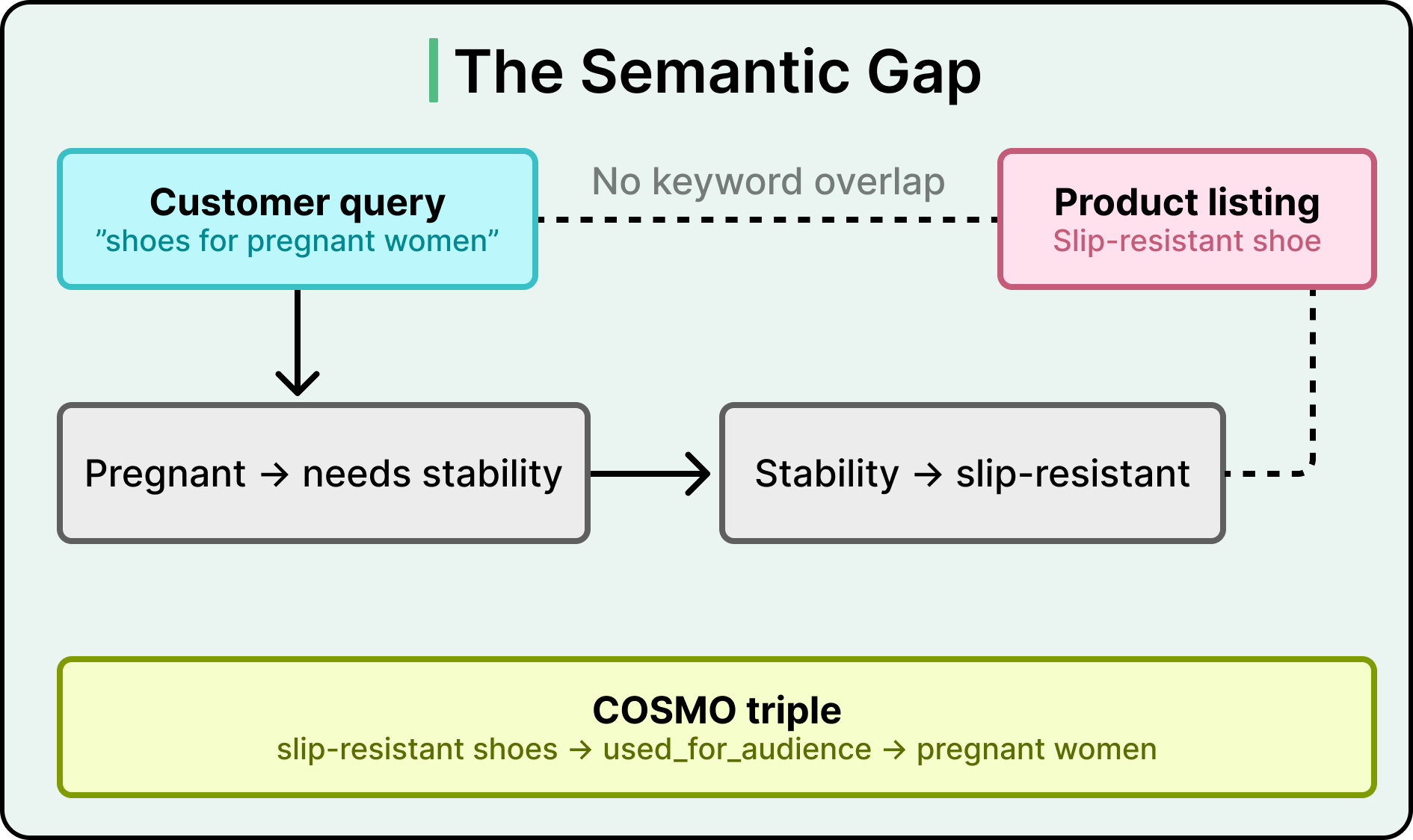
The opening puzzle: a query with no keywords in common with the answer
Search for “shoes for pregnant women” on Amazon and the top results are often slip-resistant shoes — even though the word “pregnant” doesn’t appear anywhere in those product listings. There is zero keyword overlap between query and product. To get this right, the search engine has to reason like a human: pregnant women need stability → stability means slip-resistance → slip-resistant shoes are a good match.
That chain of reasoning is exactly what traditional recommendation systems can’t do. They are good at matching text to text and purchase history to purchase history. But when the user’s real intent only exists in human common sense, those systems hit a wall.
Amazon’s search team called this the semantic gap, and built a system named COSMO — a commonsense knowledge graph generated by LLMs — to close it. This is a walkthrough of how COSMO is built, filtered, served, and what it earned in production.
Disclaimer (from the original): the post is based on publicly shared details from the Amazon Engineering Team.
The gap between what you search and what you mean
Amazon already runs large-scale factual knowledge graphs that store product attributes: brand, color, material, category. These power most of what works well in product search. But factual graphs encode what a product is, not why a human would want it.
Consider “winter clothes.” The implicit intent is warmth. A long-sleeve puffer coat’s catalog page describes material, sizes, sleeve length — but it may never use the word “warmth.” The reasoning step from “winter” to “puffer coat” lives in common sense, which factual graphs were never designed to handle.
The team surveyed prior work and found gaps in all of it:
- Alibaba’s AliCoCo (163K nodes, 91 relations) and AliCG (5M nodes) were extracted from search logs. They capture product concepts but stay focused on attributes and categories — they don’t encode user intent.
- General commonsense bases like ConceptNet (8M nodes, 21M edges) cover everyday reasoning but are built for general purposes, with little grounding in shopping behavior.
- Amazon’s own earlier project, FolkScope, showed commonsense could be mined from shopping data, but only covered 2 product categories and only co-purchase behavior.
So factual product knowledge existed, and general commonsense existed — but structured knowledge of why people buy things, at e-commerce scale, was missing.
Asking the LLM (and why the first answers fell short)
The intuition: LLMs already encode huge amounts of world knowledge. Ask one why a shopper who searched “winter coat” bought a long-sleeve puffer coat, and it can reason that puffer coats provide warmth, and warmth is what the customer wanted. So why not have the LLM produce these explanations at scale, then assemble them into a knowledge graph?
The setup
The team fed millions of user behavior pairs into OPT-175B and OPT-30B, hosted internally on 16 A100 GPUs. They picked OPT over GPT-4 specifically because of a hard data-privacy constraint: customer behavior (which queries led to which purchases) could only be processed on Amazon’s own infrastructure.
Two types of behavior data went in:
- Query–purchase pairs: a search query and the product the customer eventually bought.
- Co-purchase pairs: products bought together in the same session.
Across 18 product categories, they sampled 3.14M co-purchase pairs and 1.87M query–purchase pairs.
Sampling itself was a design decision:
- For products: cover popular browse-node categories, pick top-tier products with high interaction, and use product-type labels (1000+ classes like “umbrella” or “chair”) for finer selection.
- For co-purchase pairs: cross-check product types to remove random co-purchases; drop products that co-occur with too many different product types (a noise signal, not a real intent).
- For search–buy pairs: thresholds on purchase rate and click rate decide what enters the sample.
- Crucially, an in-house query specificity service was used to prioritize broad / ambiguous queries — because that’s where the semantic gap is biggest, and where commonsense knowledge adds the most value.
Prompt design
Rather than naive text continuation, each behavior pair was framed as a question-answering task asking the LLM to produce a numbered list of candidate explanations (not a single response). More candidates = more chances to find a usable one downstream.
The unflattering result
The LLM generated millions of candidates. But:
- Only 35% of search–buy explanations met Amazon’s quality bar for typicality (representative of genuine shopping intent).
- For co-purchase explanations, that number dropped to 9%.
The rest was filler: circular rationales like “customers bought them together because they like them,” or trivially obvious statements like “customers bought an Apple Watch because it is a type of watch.”
The 35% vs. 9% gap is itself a lesson about how LLMs reason. Explaining a query→purchase is constrained because the query already states the intent. But explaining a co-purchase requires identifying a shared reason across two different items, and LLMs default to generic explanations of one item rather than reasoning about the pair.
Discovering the relation types
Amazon also needed a vocabulary for the relationships the LLM was producing. They started with 4 broad seed relations that prior work showed produce diverse outputs: usedFor, capableOf, isA, cause. Then they mined finer-grained relations from the LLM’s own generations by spotting recurring predicate patterns. The most common pattern was “the product is capable of being used [preposition],” where different prepositions implied different relationship types.
That data-driven process produced 15 relation types, including:
used_for_function(“dry face”)used_for_event(“walk the dog”)used_for_audience(“daycare worker”)used_in_location(“bedroom”)used_in_body(“sensitive skin”)used_with(complementary products like “surface cover”)- Person-centric relations like
xIs_a(“pregnant women”) andxWant(“play tennis”)
The ontology was shaped by what the LLM actually emitted, then canonicalized by Amazon’s researchers — not designed top-down by a committee of knowledge engineers.
Building the filter: turning a noisy ore mine into a knowledge graph
The LLM produced a mountain of hypotheses, mostly noise. Amazon’s answer was a multi-stage refinement pipeline, where each stage catches a different type of failure.
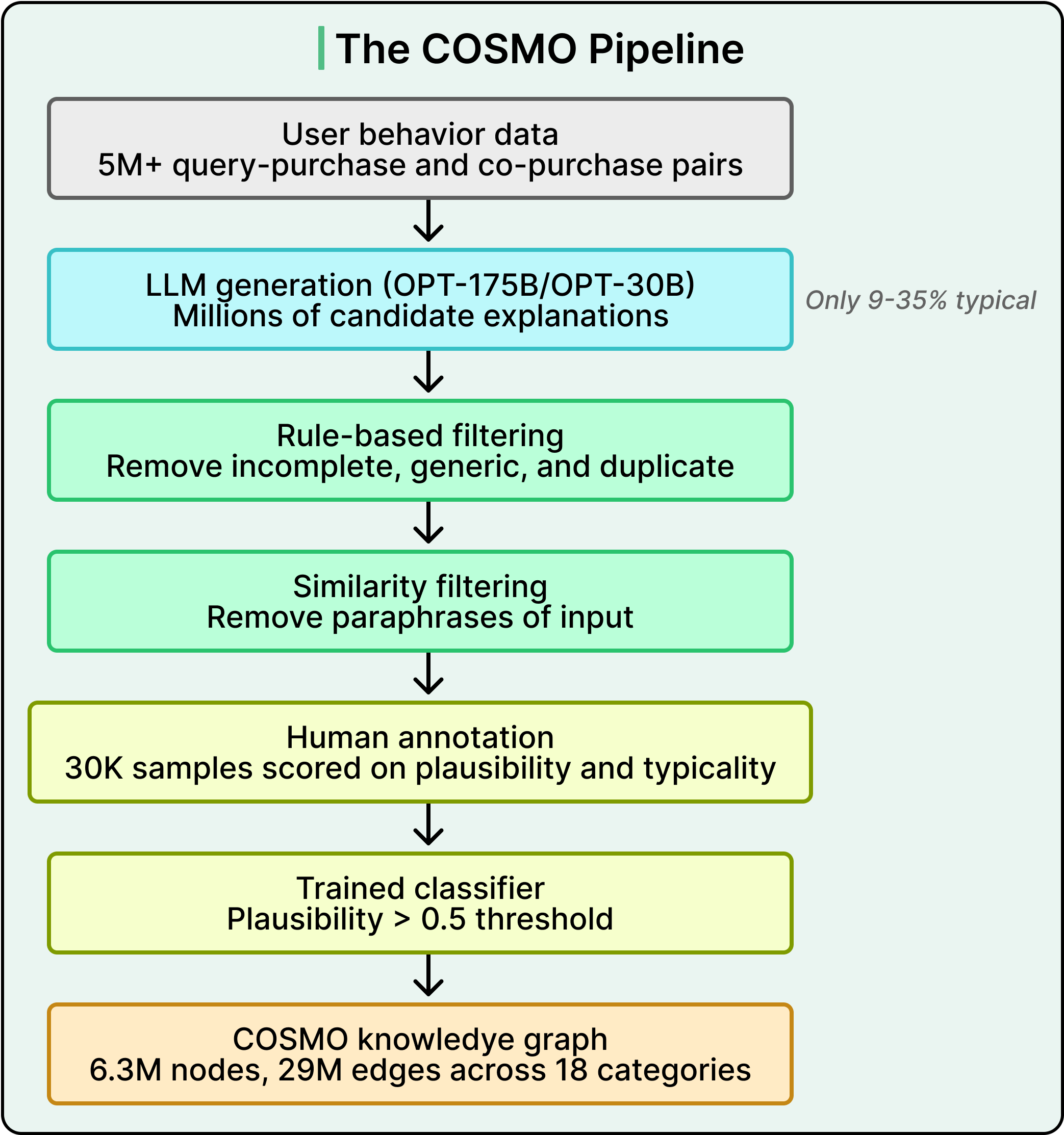
1. Coarse-grained filtering (rule-based)
- Use GPT-2 as a language model to score sentence quality and threshold out incomplete or malformed sentences.
- Discard generations that exactly match (or are near-edits of) the query, the product type, or the product title.
- For generic statements like “used for the same reason” or “used with clothes,” combine frequency and entropy to catch them — generic explanations tend to co-occur with many different products rather than specific ones.
2. Similarity filtering (semantic)
Some LLM outputs look different from the input on the surface but are just paraphrases of the original query or product description.
Amazon used an in-house language model pre-trained on e-commerce text to embed the generated knowledge, the query, and the product. If the cosine similarity between the generation and the original context was too high, the candidate was filtered out as a syntactic restatement of the input rather than new knowledge.
3. Human-in-the-loop annotation
They sampled 30,000 candidates for human review — 15K from co-purchase, 15K from search–buy, spread across 18 categories. Sampling wasn’t uniform; a weighted formula combined the frequency of a piece of generated knowledge with the popularity of the product/query, deliberately pushing toward diverse, less obvious knowledge that the downstream classifier would later need to generalize.
Annotators evaluated each candidate on two dimensions:
- Plausibility — is the relationship reasonable at all?
- Typicality — does it represent genuine, common shopping behavior?
A canonical example: people buy Apple Watches more typically because they are smartwatches than because they tell the time. Both are plausible; only one is typical.
To reduce annotator cognitive load and disagreement, both dimensions were decomposed into 5 yes/no questions covering completeness, relevance, informativeness, plausibility, and typicality. Two annotators labeled each independently; a third resolved disagreements. A pilot of 2,000 examples showed this decomposition significantly cut disagreement, and audits of 5% of all annotations showed >90% accuracy. Due to data privacy, the work was done by a professional annotation vendor under strict internal audit.
4. Classifier generalization
Finally, Amazon fine-tuned DeBERTa-large (a strong classification model) plus an in-house LM on the 30K annotated samples to predict plausibility and typicality scores for the remaining millions of candidates. Only candidates with plausibility ≥ 0.5 survived.
The output: triples → graph
Every surviving candidate becomes a structured triple: two entities connected by a defined relation. For example:
<co-purchase of camera case and screen protector, capableOf, protecting camera>
This captures the commonsense reason these two products are bought together: they both protect a camera.
Assembled, the triples form a knowledge graph of 6.3M nodes and 29M edges across 18 product categories — built from just 30,000 human judgments. That leverage ratio (30K annotations → 29M edges) is the engineering thesis of the whole project.
COSMO-LM: shrinking the model so it can run in production
The graph captures pre-computed relationships, but Amazon’s search engine sees brand-new queries and products constantly. Running the full pipeline (OPT-175B generation + classifier scoring) for every fresh query–product pair would be financially prohibitive.
The fix: instruction tuning a smaller model.
Using the 30K annotated samples as instruction data, Amazon fine-tuned LLaMA 7B and 13B — the sweet spot between generation quality and inference cost. The result, called COSMO-LM, was trained across 18 product domains, 15 relation types, and 5 distinct tasks:
- Commonsense generation
- Plausibility prediction
- Typicality prediction
- Search relevance prediction
- Co-purchase prediction
That multi-task setup is the clever part: COSMO-LM can both generate new commonsense knowledge and evaluate the quality of its own output, collapsing the original “big LLM + separate classifier” stack into a single, smaller model.
To prevent prompt-format brittleness, training varied templates: the same query–product pair might be prefixed with “search query,” “user input,” or “user searched” across different examples.
Two complementary artifacts in production
- The static knowledge graph (29M pre-computed edges) handles known product relationships.
- COSMO-LM generates fresh commonsense on the fly for new or unseen pairs at much lower inference cost than the OPT-175B pipeline.
A demo for a query like “how to decorate a home” shows COSMO-LM emitting product types — wall art, decorative signage, sticker decal, decorative pillow cover, artificial plant, rug, home mirror, lamp — each annotated with a commonsense explanation of its role in home decoration.
Serving commonsense at Amazon scale
Generating useful knowledge is one challenge. Serving it under Amazon-grade latency is another. The deployment architecture has two main components:
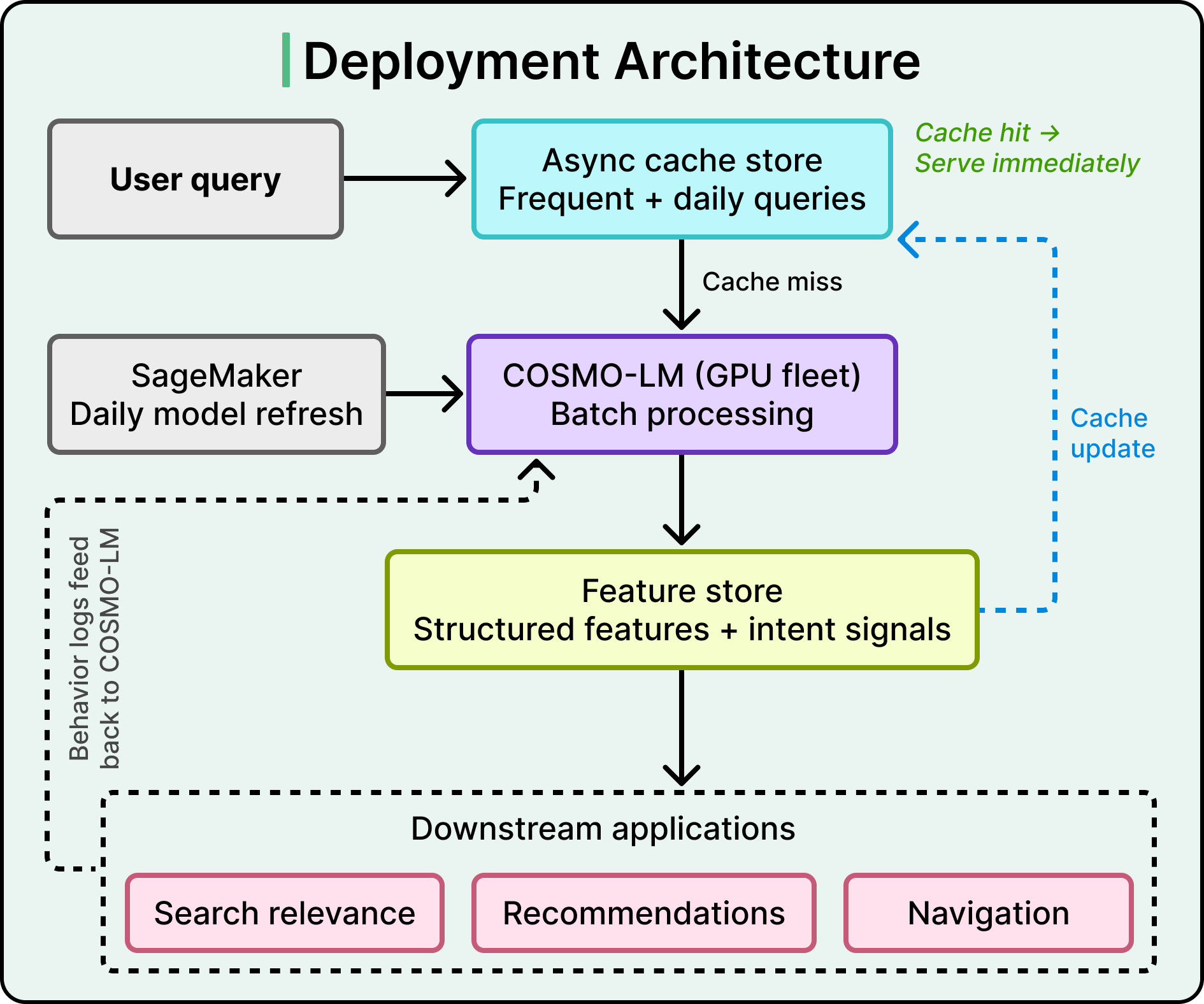
- Feature Store — converts COSMO-LM’s raw text into structured features downstream apps can consume directly: product key-value pairs, semantic subcategory representations, and intent signals.
- Asynchronous Cache Store — a two-tiered cache in the serving layer.
- Tier 1 pre-loads responses for yearly frequent searches, covering the bulk of traffic.
- Tier 2 batch-processes daily requests for newer/rarer queries and updates the cache.
When a query arrives, the system checks the cache first. Hits return immediately. Misses go to batch processing, and the cache updates so the next identical query is fast.
SageMaker manages model deployment and refresh, ingesting customer behavior session logs daily. Structured cache data feeds three downstream systems simultaneously: Search Relevance, Recommendation, and Navigation.
This meets Amazon’s strict latency requirements while keeping storage costs comparable to real-time serving. The tradeoff: COSMO updates daily, so it cannot reflect real-time events like flash sales that fluctuate within hours. Amazon explicitly flags this as a future-work area.
COSMO’s impact in numbers
Search relevance (offline)
On the public ESCI dataset (KDD Cup 2022), a cross-encoder (a model that jointly processes query and product features together, vs. encoding them separately) augmented with COSMO triples hit 73.48% Macro F1 / 90.78% Micro F1 with trainable encoders.
Quick refresher:
- Macro F1 averages performance across categories equally — rare categories matter as much as common ones.
- Micro F1 measures overall accuracy regardless of category.
That cross-encoder result beat the top-1 ensemble model on the KDD Cup leaderboard. With frozen encoders (where the only difference was whether COSMO triples were included as input), the improvement was +60% on Macro F1.
On Amazon’s private datasets across US, Canada, UK, and India, the COSMO-enhanced model beat baselines in every market — strongest gains in India, where the gap between query language and catalog language tends to be widest.
Session-based recommendations
Amazon built COSMO-GNN, extending a graph neural network model (one that learns relationships by treating shopping sessions as connected graphs) with COSMO-generated intent knowledge. It beat all competitive baselines on Hits@10 and NDCG@10 in both clothing and electronics.
The improvement was bigger for electronics (5.82% vs. 4.05% on Hits@10), where users revise their queries more (2.47 unique queries per session vs. 1.36 for clothing). The pattern is intuitive: when users keep reformulating, commonsense knowledge about why they’re searching becomes especially valuable.
Search navigation (in production, real revenue)
This is where COSMO actually earns money. It powers a multi-turn navigation system organizing intent hierarchically. A search for “camping” branches into fine intents like winter camping, beach camping, lakeside camping, which connect to product types (air mattress, winter boots), which are then refined by attributes (4 person).
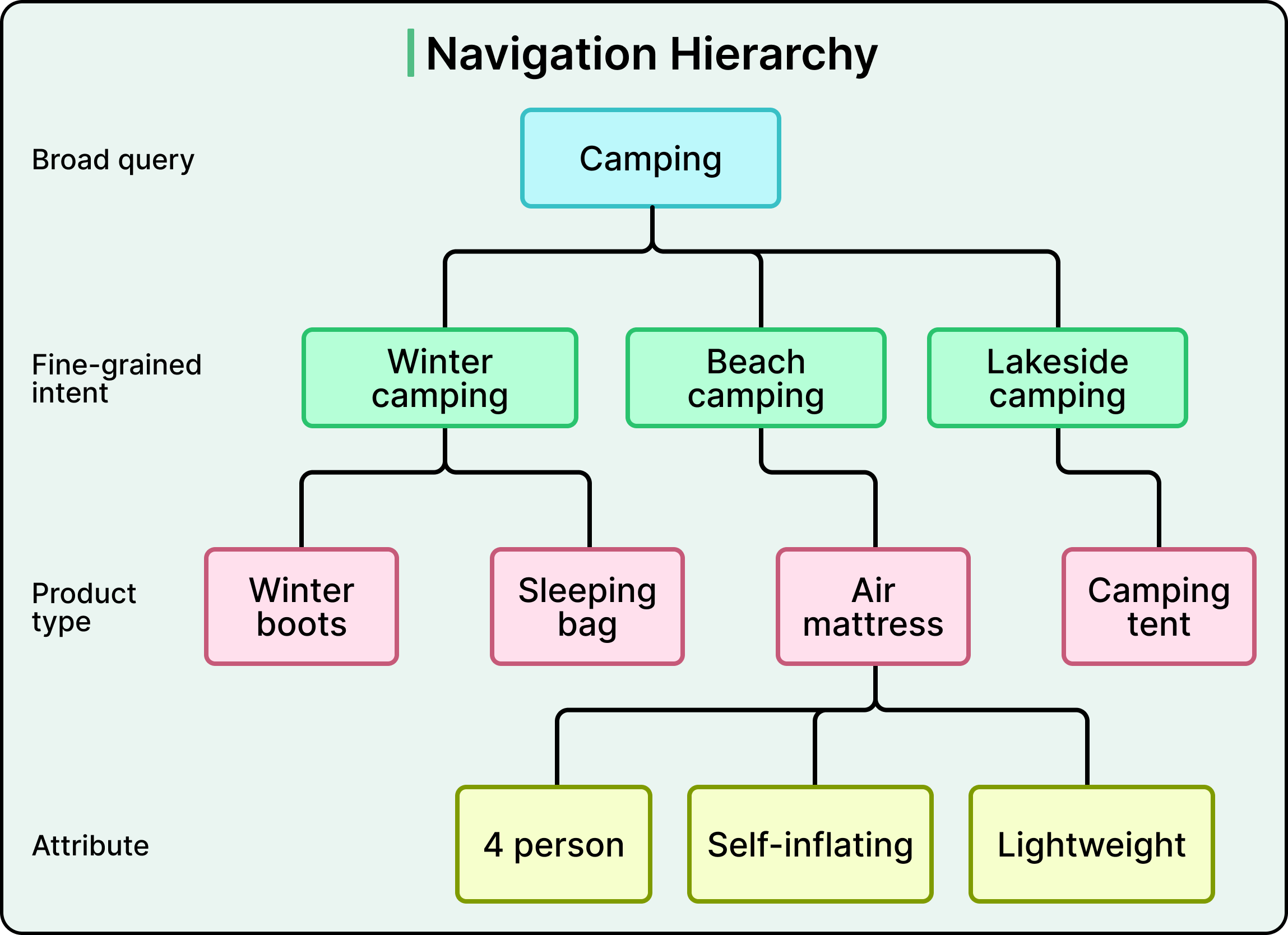
This mirrors a natural discovery process: progressively narrow the search through multiple rounds rather than forcing a perfect query upfront.
Amazon ran A/B tests over several months on roughly 10% of US traffic:
- +0.7% relative product sales in the test segment → hundreds of millions of dollars in additional annual revenue.
- +8% navigation engagement in the same segment.
And these came from a single, relatively small feature on the search page with limited visibility. Amazon has projected that extending COSMO-LM across all traffic for navigation alone could yield revenue gains in the billions.
Conclusion: the leverage ratio is the point
COSMO is Amazon’s first production system that uses an instruction-tuned LLM to construct a knowledge graph and serve it to live applications. It marks a shift from factual product knowledge graphs toward intent-based commonsense knowledge graphs.
The single most important number is the leverage ratio: 30,000 human annotations → 29 million graph edges across 18 product categories. That was only possible because Amazon invested in sampling strategy, annotation design, classifier training, and instruction tuning — instead of trying to brute-force more labels.
The honest limitations
- Daily refresh means COSMO cannot react to real-time dynamics (e.g., flash sales).
- Aggressive filtering (only candidates ≥ 0.5 plausibility survive) leaves coverage gaps, especially for long-tail products and unusual queries.
Amazon explicitly chose precision over recall, on the principle that unreliable commonsense in production is worse than missing commonsense.
The takeaway for engineers
Amazon treated the LLM as a noisy ore mine, not an oracle. The recipe:
- Generate millions of candidate explanations.
- Throw away ~91% of them with rules, embeddings, and a learned classifier.
- Validate a sample with humans, decomposing fuzzy judgments into yes/no questions.
- Use the human signal to train a smaller model that can both generate and evaluate at production cost.
- Cache aggressively, and feed structured features into downstream systems that already exist.
The engineering wasn’t in the generation. It was in the filtration — and in the disciplined infrastructure that turns filtered output into a graph, a serving model, and ultimately a search experience that knows pregnant women want stable shoes.
References
Author
ByteByteGo
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m