Simon Willison's Newsletter
GPT-5.5, ChatGPT Images 2.0, Qwen3.6-27B — and a very confusing day for Claude Code pricing
Simon Willison
Apr 24, 2026
GPT-5.5, ChatGPT Images 2.0, Qwen3.6-27B — and a very confusing day for Claude Code pricing
Source: Simon Willison's Newsletter · Author: Simon Willison · Date: 2026-04-24 · Original post
This week's edition is a tour of fresh frontier-model news: a new GPT, a new image model, a new open-weight Qwen, plus the kind of pricing-page drama that makes the AI industry feel like a soap opera.
1. A pelican for GPT-5.5 — via the semi-official Codex "backdoor"
OpenAI shipped GPT-5.5 (and a more expensive GPT-5.5 Pro). It's available inside OpenAI's Codex coding tool and rolling out to paying ChatGPT users — but not yet in the API. OpenAI says API deployments need extra safety work and will follow "soon."
That's awkward for Simon, because his running benchmark — "generate an SVG of a pelican riding a bicycle" — only works cleanly through an API. Hidden system prompts inside ChatGPT or Codex muddy the comparison. So he went looking for a back door.
What's the "backdoor"?
Big AI providers sell two things:
- API access — pay per token, expensive, used by developers.
- Monthly subscriptions (ChatGPT Plus, Claude Pro/Max) — a flat fee, often a much better deal per dollar.
Tools like OpenClaw and Pi (agent "harnesses" that drive a model in a loop to do real work) figured out how to plug into those subscriptions instead of the metered API — saving users a lot of money. Anthropic recently blocked OpenClaw from doing this against Claude. OpenAI, sensing a PR win (and having just hired OpenClaw's creator Peter Steinberger), publicly said: come on in, you can use our subscriptions through the same mechanism Codex CLI uses.
The relevant endpoint is /backend-api/codex/responses. OpenAI's Romain Huet had already tweeted that they want people to use Codex (and the ChatGPT subscription that powers it) "wherever they like" — JetBrains, Xcode, OpenCode, Pi, even Claude Code. Codex CLI and the Codex app server are open source.
llm-openai-via-codex
Armed with that blessing, Simon had Claude Code reverse-engineer OpenAI's openai/codex repo — figuring out where it stores auth tokens — and produced llm-openai-via-codex, a plugin for his LLM tool that quietly piggybacks on your existing Codex subscription:
llm install llm-openai-via-codex
llm -m openai-codex/gpt-5.5 'Generate an SVG of a pelican riding a bicycle'
All standard LLM features work: image attachments, chat mode, logging, tool use.
The pelicans

The default-effort run was disappointing — Simon thinks GPT-5.4 has done better. So he cranked the knob: -o reasoning_effort xhigh. Result, after nearly four minutes:

Concrete contrast: the default run used 39 reasoning tokens; the xhigh run used 9,322 and produced totally different (CSS-gradient-heavy) SVG code. Reasoning effort isn't a small dial — it changes the strategy the model picks.
Pricing notes
- GPT-5.5: $5 / 1M input, $30 / 1M output — double GPT-5.4 ($2.5 / $15).
- GPT-5.5 Pro: $30 / $180.
- GPT-5.4 stays available. Simon's framing: GPT-5.4 is to GPT-5.5 as Claude Sonnet is to Claude Opus — a cheaper, still-capable sibling.
Ethan Mollick's verdict (linked): GPT-5.5 is excellent at some things, surprisingly weak at others — the "jagged frontier" of capability remains.
2. Where's the raccoon with the ham radio? (ChatGPT Images 2.0)
OpenAI released gpt-image-2. On the livestream Sam Altman claimed the leap from gpt-image-1 to gpt-image-2 was as big as GPT-3 → GPT-5. Simon stress-tests that with one prompt:
Do a where's Waldo style image but it's where is the raccoon holding a ham radio
(Where's Waldo / Where's Wally is the genre of busy puzzle-illustrations where you hunt for a tiny character.)
Baseline: gpt-image-1

Even Claude Opus 4.7 (with new high-res vision) couldn't confidently find a raccoon — though, charmingly, it tried. Lesson learned: testing image gen on Where's-Waldo-style outputs is infuriating, because you can never be sure whether the model failed or your eyes did.
Google Nano Banana 2 (via Gemini)

Cute — and the W6HAM callsign pun is a nice touch — but the raccoon isn't really hiding. Nano Banana Pro did much worse: a giant raccoon in the middle with an ugly white border. Worst result of the bunch.
gpt-image-2
Simon used his openai_image.py script — a thin wrapper around the OpenAI Python client. Trick: the official client doesn't yet validate gpt-image-2 as a known model ID, but it doesn't reject unknown IDs either, so you can pass it through.
Default settings: still no findable raccoon. But cranking --quality high --size 3840x2160 (the new max resolution) produced a 17 MB PNG with this:

That image used 13,342 output tokens at $30/M = ~40¢. Image generation is now priced like very expensive text generation: every image is a quietly running token meter.
Takeaway
For complex illustrations that combine lots of detail with readable text, gpt-image-2 currently takes the crown over Gemini's Nano Banana family. But:
You can't trust these models to evaluate their own puzzles. Asked to "draw a red circle around the raccoon" in an image that contained none, ChatGPT obligingly drew a circle around an empty patch — confidently hallucinating a raccoon that wasn't there.
A nice reminder that vision models, like text models, will fabricate to satisfy a request.
3. Is Claude Code going to cost $100/month? Probably not — it's all very confusing
Anthropic silently updated claude.com/pricing: the Claude Code checkbox disappeared from the $20/month Pro plan and showed up only on Max ($100) and Max 20x ($200). No announcement. No blog post. The Internet Archive captured the before-and-after.
Reddit, Hacker News, and Twitter caught fire. Anthropic's Head of Growth, Amol Avasare, tweeted that this was "a small test on ~2% of new prosumer signups" and that existing subscribers weren't affected. Simon (and many others) didn't buy it — everyone was seeing the new grid.
Hours later, Anthropic reverted the pricing page. Then a second tweet clarified: the experiment is still running, just no longer reflected on the public-facing landing page or docs. So, allegedly, only ~2% of new signups still see the change.
Why Simon thinks this matters
Even if the change never ships, the damage is real:
- Sticker shock. $20 vs $100/month is a 5× jump. That's not a marginal difference, especially outside high-salary countries.
- Trust. A pricing change announced via an employee tweet is not how serious products communicate. Simon "wasted a solid hour" trying to figure out what was happening.
- Strategic risk. Should anyone bet long-term on Claude Code if Anthropic might 5× the floor price?
- Educational accessibility. Simon writes a lot about Claude Code (105+ posts), and runs tutorials at events like NICAR for journalists. He's not going to teach a $100/month tool to that audience.
He notes the absurdity that Claude Cowork — effectively rebranded Claude Code — remains on the $20 plan. ("Claude Code wearing a less threatening hat.")
OpenAI's Codex lead Thibault Sottiaux pounced on the gift, publicly committing that Codex stays available on Free and Plus ($20). That kind of contrast is exactly what Anthropic just handed their main coding-agent competitor.
Simon's bottom line: he personally pays $200/month for Claude Max and considers it worth it. But for the tools he teaches and recommends, accessibility matters. If Codex is free and Claude Code starts at $100, his recommendation has to follow the audience.
He suspects what happened: someone inside Anthropic pitched gating Claude Code to Max, "testing culture" said test all ideas just in case, and they shipped the test without modeling the brand cost. Even if reverted, that calculation seems wrong.
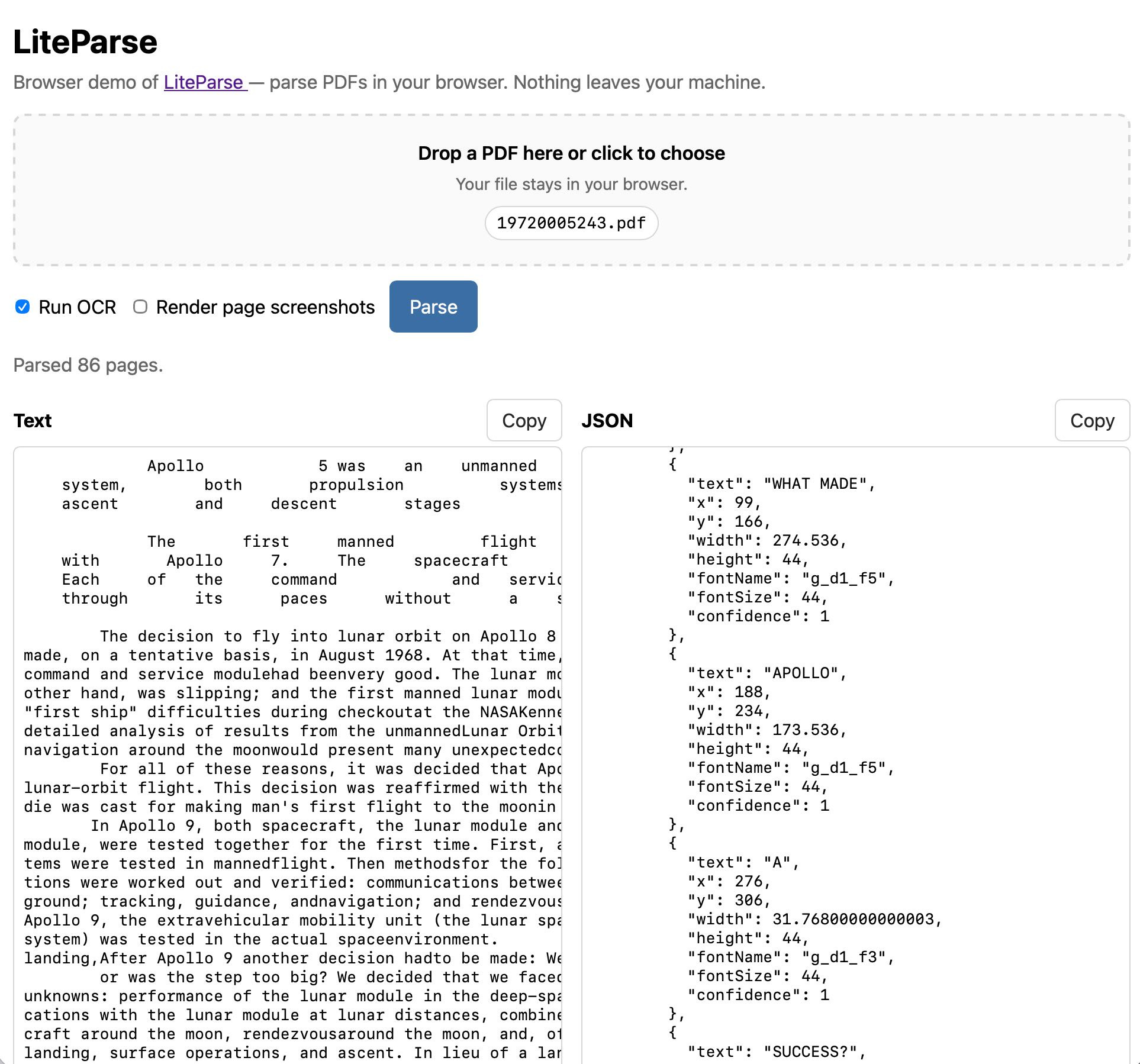
4. Extract PDF text in your browser with LiteParse for the web
LlamaIndex's open-source LiteParse is a Node.js CLI tool that does something genuinely hard: pulling text out of PDFs in the right reading order.
Why this is hard
PDFs don't have a "text" — they have a soup of glyphs scattered at coordinates. A two-column page rendered naively gives you alternating lines from both columns. LiteParse calls its solution "spatial text parsing": heuristics that detect multi-column layouts, group text blocks, and emit them in a sensible linear flow. It uses no AI; it falls back to Tesseract OCR for scanned image-based PDFs.
LiteParse's docs also describe Visual Citations with Bounding Boxes: when answering a question from a PDF, you can return a cropped, highlighted screenshot of the source region. That's a nice trust-building UX for RAG-style Q&A — the reader can verify the source visually, not just "trust the LLM."
Simon's contribution: the same thing, fully in the browser
LiteParse's dependencies (PDF.js, Tesseract.js) are already browser-compatible. Nobody had wired them up, so Simon did. Visit https://simonw.github.io/liteparse/ to drop in a PDF — nothing leaves your browser.
How he built it (a case study in modern AI-assisted coding)
This section is gold for anyone curious how a working engineer actually uses these tools. The whole project — from idea to deployed GitHub Pages app — took 59 minutes in Claude Code.
The workflow:
- Phone-based exploration. On his iPhone, in regular Claude chat, he asked it to clone the repo and run it against a random PDF. Claude can clone GitHub repos and install npm/PyPI packages in its sandbox now. Good for "do I even want to invest more time?"-level investigation.
- Switch to laptop. Forked the repo, made a
webbranch, dropped Claude's earlier exploratory answer intonotes.md. - Plan first, code second. Asked Claude Code to write
plan.mdbefore writing any app code. He prefers a plan-as-artifact over Claude's "planning mode" because he can edit it. When Claude proposed deferring page screenshots ("canvas-encode swap to v2"), Simon simply said "update the plan to include the canvas-encode swap" and they re-aligned before any code was written. - Said "build it" and walked away. While Claude Code worked, Simon did Duolingo and tinkered with other projects, queueing up follow-up prompts. He shares many of them — small examples of how he steers an autonomous agent:
When you implement this use playwright and red/green TDD, plan that toolet's use PDF.js's own renderer(it had wandered off to pdfium)small commits along the way— he believes (unproven hunch) this helps the agent take problems one at a time, and definitely makes review easier- Pasted screenshots of UI glitches with prompts like "style the file input so long filenames don't break things on Firefox" — visual feedback works surprisingly well
- Used a separate Claude Code session in the same directory to figure out how to run the in-progress version locally — turned out to be
npx vite, which gave him live reload while the main agent kept editing files. - Deployed via GitHub Pages. A fresh Claude Code instance set up GitHub Actions to test on push and deploy on green. Simon loves this combo — zero-cost public hosting plus build pipelines, configured by an agent.
- Cross-checked the work using a different model. To guard against Claude silently faking features or marking critical bits as TODO, he fired up OpenAI Codex with GPT-5.5 and asked it: "describe the difference between how the node.js CLI tool runs and how the web/ version runs." The plausible answer convinced him no major shortcuts had been taken.
Is this even "vibe coding" anymore?
Simon is strict about the term: vibe coding (per his own original definition) means using AI to write code and not reading or caring about the code at all. By that test, this LiteParse port qualifies — he hasn't read a single line and had to look up whether it ended up as JavaScript or TypeScript.
Yet it doesn't feel like risky vibe coding to him, and the reasoning is worth absorbing:
- Tiny blast radius. It's a static page on GitHub Pages — it works for your PDF or it doesn't. No backend, no DB, no auth.
- No private data leaves the browser — verified by glancing at the network panel — so a security audit is unnecessary.
- Engineering judgment was still required. Recognizing that the path forward was "port it to run in the browser" — not just "make Claude write some code" — was the actual high-leverage decision. The model executed; the human picked the target.
- He'll attach his name to it. That's his bar for "fine as it is": is he comfortable recommending it?
He hasn't opened a PR upstream — instead he opened an issue offering the work as a starting point if the LiteParse maintainers want it.
5. Changes in the system prompt between Claude Opus 4.6 and 4.7
Anthropic is the only major lab that publishes the system prompts behind their consumer chat product (the hidden instructions that shape model behavior before any user message). Their archive now goes back to Claude 3 (July 2024).
To make diffs browsable, Simon had Claude Code split Anthropic's system-prompt page into one Markdown file per model and back-date fake git commits to the publication dates. That gave him a browsable git history of Claude system prompts.
Highlights from the Opus 4.6 → 4.7 diff:
- Naming. "Developer platform" → "Claude Platform."
- New Claude tools referenced in the prompt: Claude in Chrome (browser agent), Claude in Excel (spreadsheet agent), and Claude in Powerpoint (slides agent — newly mentioned). Claude Cowork can use all of these as tools.
- Massively expanded child safety section, wrapped in a
<critical_child_safety_instructions>tag. Notable: "Once Claude refuses a request for reasons of child safety, all subsequent requests in the same conversation must be approached with extreme caution." - Less pushy. New instruction telling Claude to respect when users say they're done — don't try to elicit another turn.
- New
<acting_vs_clarifying>section. Instead of asking clarifying questions when minor details are ambiguous, Claude should act now using a reasonable interpretation — and if a tool can resolve the ambiguity (search, location lookup, calendar), it should call the tool rather than making the user do the lookup. This codifies a major shift toward agentic behavior. "Once Claude starts on a task, Claude sees it through to a complete answer rather than stopping partway." - Tool-search behavior. Claude must call
tool_search(a new mechanism that surfaces deferred tools) before saying "I don't have access to X." Capability denials are only valid aftertool_searchconfirms no matching tool exists. Big implication: the chat agent now has many more tools than it knows about by default; they're loaded on demand. - Less verbose responses. New language: keep responses focused; even necessary disclaimers should be brief.
- Removed. A section telling Claude to avoid
*emotes*and the words "genuinely," "honestly," and "straightforward" — apparently the new model no longer needs that nudge. - New disordered-eating safety section. No specific numbers, targets, or step-by-step plans for nutrition/diet/exercise once disordered eating is suspected — even when the intent is to help — because precise numbers can themselves be triggers.
- Anti-screenshot-attack guard in
<evenhandedness>: if asked for a one-word yes/no on a contested topic or person, Claude can refuse the short form and explain why a nuanced answer is more appropriate. This is a direct response to viral "gotcha" screenshots. - Trump-presidency reminder removed. Opus 4.6 had explicit text telling Claude that Donald Trump is the current president, inaugurated Jan 20, 2025 — needed because the model's training cutoff plus older knowledge of Trump's false 2020-victory claims could otherwise lead it to deny he was president. Opus 4.7's training cutoff is now January 2026, so the workaround is gone.
Listing Claude's actual tools
The published prompt doesn't include the full tool descriptions — arguably the more useful documentation. Simon got around this by asking Claude directly: "List all tools you have available with an exact copy of the tool description and parameters." That yielded a list including bash_tool, conversation_search, create_file, fetch_sports_data, image_search, places_search, recipe_display_v0, recommend_claude_apps, search_mcp_registry, str_replace, view, weather_fetch, web_fetch, web_search, tool_search, visualize:read_me, visualize:show_widget, and others. The list of tools hasn't changed since 4.6 — but their descriptions and the surrounding orchestration instructions clearly have.
6. Briefly: links, quotes, and one big open-weight release
Qwen3.6-27B — flagship-level coding in a 27B dense model
Qwen claims their new Qwen3.6-27B dense model beats the previous-generation flagship Qwen3.5-397B-A17B (a 397B-total / 17B-active mixture-of-experts) on every major coding benchmark. The size difference is the headline:
- Qwen3.5-397B-A17B on Hugging Face: 807 GB.
- Qwen3.6-27B: 55.6 GB.
That's not just a smaller model — it's a smaller model that outperforms its much larger predecessor. The compression of capability into less weight continues.
Simon ran it locally on his Mac using the 16.8 GB Q4_K_M Unsloth quant with llama-server (installed via brew install llama.cpp). Pelican-on-bicycle output:

Performance on his hardware: ~25 tokens/sec generation, 4,444 tokens to produce that pelican (~3 minutes). Excellent local coding-grade output is now feasible on a 16 GB-class GGUF.
Claude Token Counter, now with model comparisons
Anthropic's Opus 4.7 ships an updated tokenizer. The same input now maps to roughly 1.0–1.35× more tokens than Opus 4.6, depending on content. Simon's Claude Token Counter tool now compares counts across models. Pricing per token didn't change ($5 / $25 per million in/out for Opus) — but the inflation means real-world cost is about 40% higher for the same text.
For images, the multiplier looks dramatic at first — a 3.7 MB PNG hit 3.01× the tokens — but that's almost entirely because Opus 4.7 supports much higher input resolutions (up to ~3.75 megapixels, more than 3× prior Claude models). For a smaller 682×318 image, both models used essentially the same number of tokens. For a 30-page text-heavy PDF, the multiplier was a tame 1.08×.
"Headless everything for personal AI"
Matt Webb predicts that personal AI agents will drive a resurgence of headless services — APIs first, GUIs maybe never. Marc Benioff seems to agree: he announced "Salesforce Headless 360: No Browser Required! Our API is the UI." If this trend lands, per-seat SaaS pricing — which assumes humans clicking around — may not survive contact with agents calling APIs directly. Simon connects this to the early-2010s API-first wave; Brandur Leach has a piece arguing APIs are about to become the deciding factor between otherwise-similar SaaS products.
GitHub Copilot Individual plan changes
On the same day as the Claude Code pricing kerfuffle, GitHub announced: tighter usage limits, paused signups for individual plans (!), Claude Opus 4.7 restricted to the $39/month Pro+ tier, and older Opus models dropped entirely. Their reasoning is honest: agentic workflows burn an order of magnitude more compute than 6 months ago, and Copilot was uniquely per-request (not per-token), meaning agents that consume more tokens per request cut directly into their margins. The new limits are token-based per session and per week. Simon's complaint: "GitHub Copilot" is now 15+ products under one brand — the announcement doesn't clearly say which ones are affected.
Claude Code postmortem
Anthropic confirmed the steady stream of "Claude Code feels worse" complaints over the last two months were real bugs in the harness, not model regressions. The standout:
On March 26 they shipped a change to clear Claude's older "thinking" from sessions idle over an hour, to reduce resume latency. A bug caused this to fire every turn for the rest of the session — so the assistant felt forgetful and repetitive.
Simon points out he often has 10+ "stale" Claude Code sessions he returns to over hours or days, and probably spends more prompting time in those than in fresh ones. Lesson: the harness around the model is itself a complex distributed system, and bugs in it can look exactly like a model getting dumber.
honker — Postgres NOTIFY/LISTEN for SQLite
A new SQLite extension by Russell Romney implementing Postgres-style pub/sub queues and Kafka-style durable streams inside SQLite. Implements the transactional outbox pattern — items only get queued if the surrounding transaction commits — which is essential for "send this email when the order is saved" correctness. (Simon's favorite explanation of the pattern is Brandur Leach's Transactionally Staged Job Drains in Postgres.) Workers can poll the WAL file's stat() every 1 ms for near-real-time wake-up without running a SQL query each tick. Requires WAL mode.
Bluesky's "For You" feed runs on a gaming PC in someone's living room
A guest post on the AT Protocol blog explains how spacecowboy's "For You" feed (used by ~72,000 people) is built. The whole stack: a single Go process using SQLite, on a 16-core, 96 GB RAM, 4 TB NVMe gaming PC in their living room, consuming the Bluesky firehose and storing 90 days of likes (~419 GB SQLite). Public traffic terminates on a $7/month OVH VPS, tunneled to the home server via Tailscale.
Total monthly cost: $30 ($20 electricity + $7 VPS + $3 domains). spacecowboy estimates that this setup could serve recommendations to all ~1 million daily active Bluesky users if they switched to their cheapest known-good algorithm. A spectacular reminder of what one person, SQLite, and consumer hardware can do — and a nice anti-pattern to "you must run this on Kubernetes."
Quote of the week
AI agents are already too human. Not in the romantic sense, not because they love or fear or dream, but in the more banal and frustrating one. The current implementations keep showing their human origin again and again: lack of stringency, lack of patience, lack of focus. Faced with an awkward task, they drift towards the familiar. Faced with hard constraints, they start negotiating with reality.
— Andreas Påhlsson-Notini, Less human AI agents, please
What to take away
- Subscription "backdoors" are now a real distribution channel — OpenAI is leaning in (Codex CLI, open API endpoints) while Anthropic is locking down. This will shape which tools developers build on.
- Image gen pricing is text-gen pricing in disguise. A single high-quality gpt-image-2 image is ~40¢. Plan accordingly.
- Pricing transparency is a trust feature, not a comms detail. Anthropic burned a lot of goodwill in an afternoon over a "test."
- Agentic system prompts are getting more sophisticated — Claude 4.7 prefers acting via tools over asking, knows about deferred tools through
tool_search, and has tighter safety rails (child safety, disordered eating, contested-topic gotchas). - A good 27B open-weight model now matches yesterday's 397B flagship at coding. The local-LLM ceiling keeps rising.
- AI-assisted "vibe coding" is becoming legitimate engineering when the blast radius is small, the data flow is verifiable, and a human still picks the right architectural target.
Author
Simon Willison
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m