Programming Digest #674
Floating Point From Scratch — and Why It Still Scares Engineers
Jakub (curator)
Apr 26, 2026
Floating Point From Scratch — and Why It Still Scares Engineers
Source: Programming Digest #674 · Author: Jakub (curator) · Date: 2026-04-26 · Original issue

This week's Programming Digest leads with a deep, almost confessional 41‑minute essay by hardware engineer Julia Desmazes about rebuilding floating point from the math up — and then putting her own floating‑point unit (FPU) onto real silicon. The rest of the issue rounds out with sub‑500ms voice agents, a Bryan Cantrill rant on why LLMs aren't lazy enough, a one‑line git branch cleanup from leaked CIA dev docs, and Addy Osmani on "agent harness engineering." The floating‑point piece is the centerpiece, so most of this summary is dedicated to it.
🐉 Floating Point From Scratch — Julia Desmazes (~41 min)
"I have a confession to make: floating point scares me."
Julia tried to implement floating‑point arithmetic half a decade ago and was, in her words, completely defeated. This article is the rematch. She decides she will not just use floats — she will rebuild the representation, write the adder in C, design the hardware in Verilog, optimize it, and tape it out on a real 130nm chip. Twice.
The mental model: what a float actually is
A normal IEEE‑754 floating‑point number is:
$$(-1)^S \times 2^{E-b} \times \left(1 + T \cdot 2^{1-p}\right)$$
Where $S$ is the sign bit, $E$ is the biased exponent stored in the bits, $T$ is the trailing significand (a.k.a. mantissa), $b$ is a per‑format bias (e.g. 127 for float32), and $p$ is the precision in bits. For float32: 1 sign bit, 8 exponent bits, 23 significand bits, $b=127$, $p=24$.
The "+1" in front of the mantissa is the hidden bit: a leading 1 that is implied, never stored, and gives you one extra bit of precision for free. This trick only works for normal numbers — and that crack is where most of the weirdness leaks in.
The seven things you didn't want to know
Julia walks through every place where the spec stops being intuitive. Each one matters because it shapes both compiler behavior and silicon cost.
1. There are two zeros. Because the sign bit is a real, separate bit, +0.0 and −0.0 are distinct bit patterns. That makes a "subtract and check if all bits are zero" equality implementation subtly wrong, and forces a small lookup table of rules about which zero is produced when (e.g. X − X = +0.0).
2. NaN is not one thing. "Not a Number" comes in two flavors: quiet NaNs (qNaN) — what bad math (like sqrt(-1), 0/0, or +∞ − ∞) produces — and signaling NaNs (sNaN) which raise an invalid‑operation exception the moment they appear as an operand. NaNs are contagious: any arithmetic with a NaN yields a NaN, because there's no defensible answer to "what plus garbage equals?". In memory, NaN means all exponent bits set to 1 plus at least one significand bit set; the implementer is free to encode meaning into which significand bits are set.
3. Infinities are not numbers. They are limits. +∞ and −∞ have all exponent bits set to 1 and all significand bits zero (that's how they're distinguished from NaNs). The spec defines specific operations on them; subtracting them from each other yields NaN.
4. Subnormals (a.k.a. denormals) exist for "gradual underflow." Below the smallest normal number there's a gap to zero. Without subnormals, two distinct floats $x \ne y$ can still have $x - y = 0$, which destroys numerical stability and can crash code like 1.0 / (x - y). Subnormals fill that gap by setting the hidden bit to 0 instead of 1, giving you a runway of progressively less precise small values down to zero. Example in float16: without subnormals, 0.0000916 − 0.0000763 = 0; with subnormals, you get 0.0000153. The cost: subnormals were the most controversial part of IEEE 754 during its drafting, and early FPUs used to trap on subnormals and handle them in software — making code that hit them suddenly crawl.
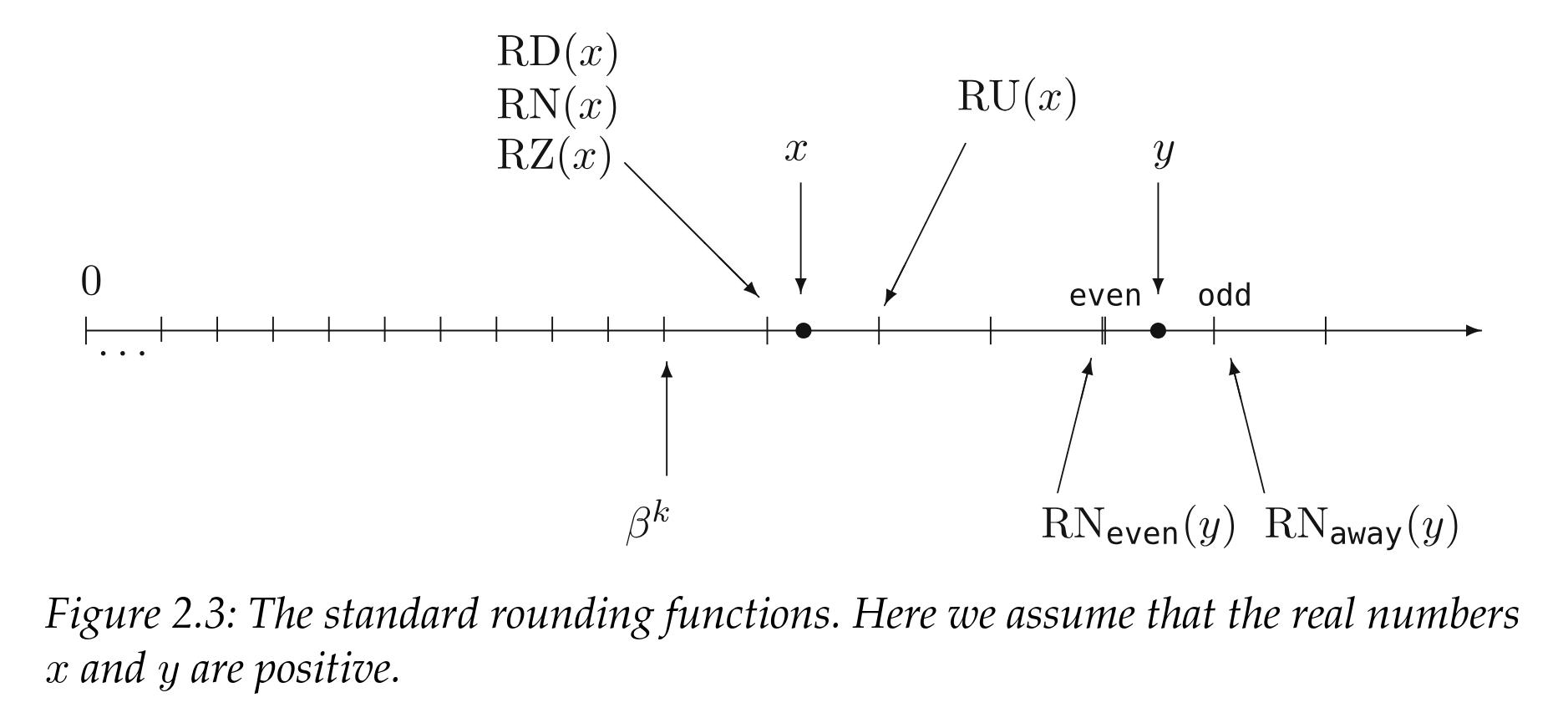
5. Five rounding modes. When the exact answer doesn't fit in your format, the spec defines five ways to round: RD (round down toward −∞), RU (round up toward +∞), RZ (round toward zero — i.e. truncate magnitude), and round‑to‑nearest with two tie‑breakers — RN_even (pick the result with mantissa LSB = 0; this is the default and what FE_TONEAREST selects in C++) and RN_away (pick the value further from zero on a tie). Example: 15359 is not representable in float16; the neighbors are 15352 and 15360. With RD or RZ you get 15352; with RU or RN_even you get 15360.
6. Rounding modes change overflow. With RU, 65504 + 1 in float16 rounds up to +∞. With RD it rounds the negative side to −∞. But RZ clamps — it rounds toward zero, so it can never produce ±∞. Julia foreshadows that this property will save her thousands of transistors later.
7. NaN comparisons are "unordered." The IEEE spec adds a fourth comparison outcome on top of less/equal/greater: unordered, which fires whenever a NaN is involved. Every NaN compares unordered with everything, including itself. The practical fallout: x != x is true when x is NaN, and the algebraic identity not(x < y) ⇔ (x >= y) — the law of trichotomy — silently breaks. You cannot un‑see this once you've seen it.
Building an adder in C (illustrative)
To ground the theory, Julia codes a bfloat16 adder in C. The high‑level recipe — and the same shape any FPU follows — is:
- Handle special inputs (zeros, NaN, infinity) up front via lookup‑style logic.
- Order the operands so that
|src0| ≥ |src1|, and flip signs so the larger one is positive. This collapses the cases. - Align mantissas. Compute
shf = exp0 − exp1and right‑shift the smaller mantissa byshfbits so both numbers share an exponent. (Both mantissas are placed with their hidden bit at a known offset — bit 31 in her code — to leave room for shifts.) - Add or subtract the aligned mantissas depending on the effective sign.
- Renormalize. If the result overflowed the mantissa width by one bit, right‑shift by 1 and bump the exponent. If it lost leading bits (massive cancellation in subtraction), find the highest set bit, left‑shift to put it back at the hidden‑bit position, and decrement the exponent by the shift count. If the exponent goes non‑positive, you've underflowed — collapse to zero (no subnormal support in her design).
- Reattach the sign and return.
That whole dance is what a single fadd instruction does in one cycle on your CPU.
From C to silicon: the ASIC reality check
Software is "from scratch‑ish." Julia goes deeper: build the FPU out of logic gates and tape it out. A few constraints to internalize before reading the design:
- Hardware is built from standard cells — pre‑laid‑out transistor groups for things like AND/OR/XOR. Each cell takes a fixed area on the chip; more transistors = more area = more cost.
- More area means longer wires between cells, which means longer signal propagation delay. Your clock period must be longer than your slowest signal path, so wire and gate delay directly cap your maximum frequency.
- The two metrics that matter, then, are area and timing (Fmax). Julia's stated goal: lowest area, highest frequency — best bang per buck.
Picking a format: bfloat16 wins
Floats are not one thing. Industry options include float16 (5/10), float32 (8/23), float64 (11/52), Pixar's PXR24 (8/15), Nvidia's TF32 (a 19‑bit format, 8/10), and Google's bfloat16 (8/7). Julia is targeting a custom matrix‑multiply systolic array (the same shape as ML accelerators), and her chip is I/O bottlenecked, so a minifloat is a must.
The hardware angle decides it: significand multiplication doesn't scale linearly. An 8‑bit bfloat16 significand multiplier is roughly half the cost of an 11‑bit float16 significand multiplier. AI workloads are tolerant of precision loss but love range, so trading mantissa bits for exponent bits is a free win.
bfloat16 also has a delightful property: no formal spec. That's both a curse (everyone implements it differently — see xkcd 927) and a blessing (you can drop everything you don't need).
She drops a lot:
- Only RZ rounding.
RZtruncates and clamps on overflow instead of rounding to ±∞. That kills the need for a final 16‑bit add on the critical path, and as long as you don't accept ∞ as an input, you'll never produce ∞ as output. - No infinities, no NaNs allowed as input. Because addition/multiplication only organically produce NaN when an ∞ is involved, banning ∞ as input lets you also throw out NaN handling entirely.
- No subnormals. Anything that would underflow gets clamped to ±0.0. The hardware savings beat the 126 extra representable values.
Final spec: bfloat16, RZ‑only, no specials, no subnormals. A wonderfully lean piece of silicon.
Adder architecture: the dual‑path trick
A naive adder runs every step on a single sequential path — small area, terrible timing. Since the 1980s, high‑performance FPUs have used a dual‑path adder based on one observation: the two expensive things — massive cancellation (which forces a leading‑zero count and big exponent decrement) and large mantissa shifting (which happens when the operands' exponents differ a lot) — are mutually exclusive. Cancellation only happens when (a) the exponents differ by less than 2 and (b) the operation is effectively a subtraction.
So you split:
- Close path: exponent difference < 2 AND effective subtraction. Cheap shifts; expensive leading‑zero count.
- Far path: everything else. Expensive shifts; no cancellation to worry about.
You pay a small amount of duplicated logic for a large drop in critical‑path depth.
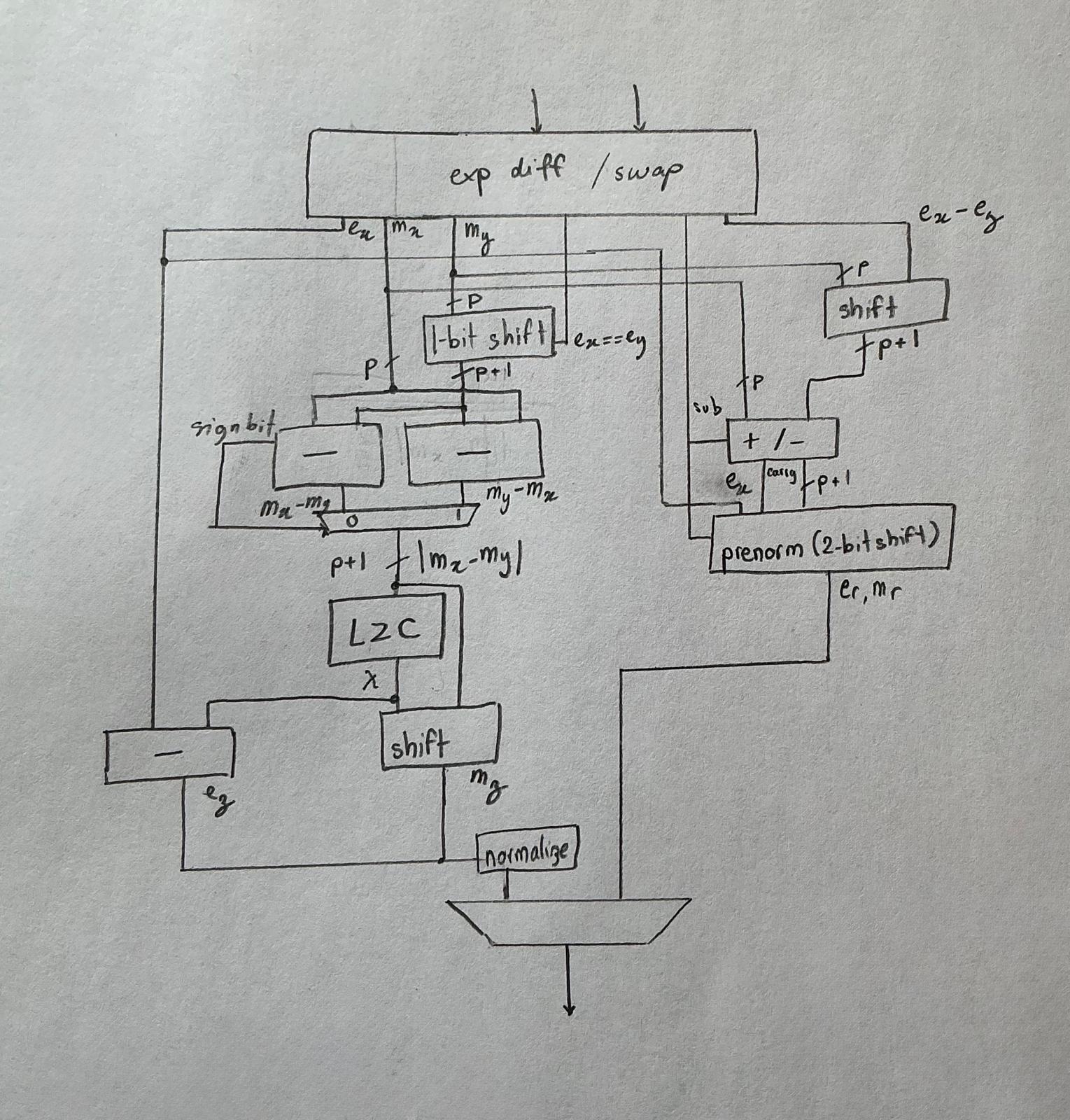
Then she takes scissors to the standard schematic: the rounding‑up logic disappears (RZ doesn't round up), the exception logic disappears (no NaN/∞), and the subnormal handling shrinks to a "detect and clamp to zero" block on the close path.
Theory meets reality: verification
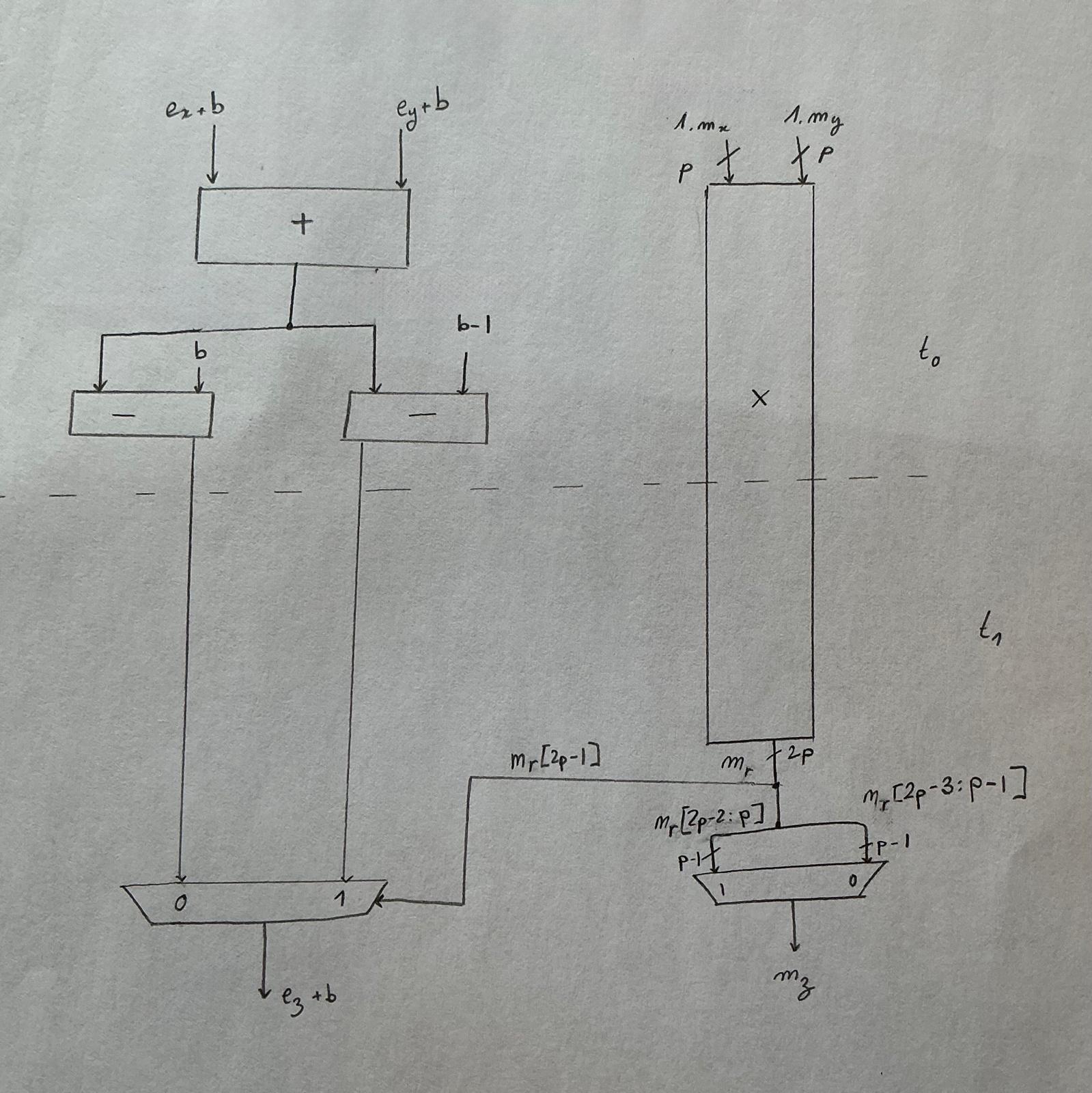
You can't test an FPU with 100 random inputs. Floating point is full of corner cases you don't know exist — a "you don't know what you don't know" problem. Modern verification often uses formal methods, but Julia goes brute force: test all $2^{32}$ input pairs (4+ billion combinations) with Verilator, the fastest open‑source simulator, plus DPI‑C calls into a "golden model" written against C++23's new std::bfloat16_t in <stdfloat>.
That's where she got betrayed by C++.
Looking at the disassembly of bfloat16_t arithmetic, the compiler calls __extendbfsf2 and __truncsfbf2. In other words: bfloat16_t is not computed natively — it's promoted to float32, computed there, then truncated back. The 2022 standards proposal P1467R9 says so explicitly: bfloat16 is "binary32 with 16 bits of precision truncated."
The practical consequence: float32 has internal precision $p=24$, while real bfloat16 has $p=8$. If both inputs differ in exponent by an amount inside that gap, the float32‑emulated path rounds differently than dedicated bfloat16 hardware, even with the same rounding mode. The error stays within 1 ulp (unit in the last place — the gap between adjacent representable floats), which sounds small but means the golden model and the silicon disagree on bit‑for‑bit equality. Julia ends up tolerating up to 1‑ulp relative error in her test rig and notes that C++ isn't really wrong — emulating bfloat16 on the FPU is hugely faster than doing it in software, and bfloat16 has no spec to violate.
Implementation gotchas worth stealing
Two stories from the actual tapeout that any RTL/synthesis user can take to the bank:
Yosys is smarter than you. Julia had built a tree‑based leading‑zero counter (LZC) — the textbook elegant design, but unreadable Verilog. A friend suggested replacing it with a dumb 9‑case casez priority encoder and letting the synthesizer figure it out. To her surprise, Yosys synthesized the priority‑mux version into 19 cells, only 3 logic levels deep on the critical path — slightly faster than the tree, dramatically more readable, and thus easier to maintain. Lesson: trust your modern synthesizer; readable RTL often wins.
Single‑cycle bfloat16 add+multiply at 100MHz on 130nm. Julia targeted the IHP sg13g2 130nm node via Tiny Tapeout's ihp26a shuttle and crammed the entire bfloat16 add and multiply into a single cycle at 100 MHz, even though her chip is bottlenecked at 75 MHz by GPIO output speed. Just because.
The "uselessly fast" multiplier. A second shuttle popped up on a sister node (sg13cmos5l) with a 24‑hour announcement‑to‑close window. To race a friend, she custom‑built an 8‑bit unsigned Booth radix‑4 multiplier from scratch (a classic technique that halves partial products by encoding two bits at a time), pipelined it across two cycles by inserting a flop in the middle of the partial‑product compression tree, and clocked it at 454.545 MHz in a single Tiny Tapeout tile. At 3 a.m.
The takeaway
After two tapeouts, Julia revises her opening claim. The list of "people who really understand floating point" used to be (1) spec authors, (2) math PhDs, (3) FPU designers. Now that she is number 3, she removes herself from the list — she now just knows how deep the rabbit hole goes. The piece's deeper lesson is that being able to use a thing is not understanding it, and that the gap between IEEE theory, your compiler's actual codegen, and the silicon underneath is wider than most software engineers ever notice.
The rest of the issue
Voice features that sound human and start fast — sponsored by Async
Async pitches a streaming TTS / voice‑cloning API with audio starting in 166ms, 15+ language support, REST + WebSocket, Twilio/LiveKit/Pipecat integrations, from $0.50/hr. Top‑3 on Hugging Face's TTS Arena.
How I built a sub‑500ms latency voice agent from scratch — Nick Tikhonov (~14 min)
Nick walks through building a custom voice agent that responds in ~400ms, beating off‑the‑shelf tooling. The hard part of voice isn't transcription or synthesis individually — it's turn‑taking and coordination between speech recognition, the LLM, and TTS, all under a tight latency budget. By picking faster models, streaming aggressively between stages, and rethinking system design, his stack feels noticeably more human than existing tools.
The peril of laziness lost — Bryan Cantrill (~5 min)
Cantrill argues good software depends on engineer laziness — the urge to build clean abstractions now so future work is cheaper. LLMs lack this virtue entirely, because effort costs them nothing: they happily pile on more code with zero pressure to simplify. Counter‑intuitively, this makes human constraints more important when LLMs are in the loop, not less. The right framing: LLMs as tools steered by engineers who still care about systems being smaller and cleaner.
Cleaning up merged git branches — Spencer Dixon (~2 min)
A 2017 WikiLeaks dump of CIA internal documents included some genuinely useful everyday dev tips. The standout: a one‑liner that lists all merged git branches and deletes them in one shot, skipping your current branch and main. Saved as a shell alias, it turns "cleaning up a cluttered branch list" into a single word.
Agent harness engineering — Addy Osmani (~17 min)
Osmani's frame: an agent isn't the model — it's the model plus a harness of prompts, tools, memory, feedback loops, and guardrails around it. Harness engineering is the discipline of building that surrounding system so the agent works reliably in the real world. When something goes wrong, you don't blame the model; you fix the harness so the same error stops recurring. In practice, harness design — feedback loops, retry/repair logic, tool boundaries — often matters more for production performance than which underlying model you picked.
Most popular last issue
IAM: Everything you need to know — Lukas Niessen.
Author
Jakub (curator)
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m