ByteByteGo Newsletter
EP212: Data Warehouse vs Data Lake vs Data Mesh
ByteByteGo
Apr 25, 2026
EP212: Data Warehouse vs Data Lake vs Data Mesh
Source: ByteByteGo Newsletter • Author: ByteByteGo • Date: Apr 25, 2026 • Original
This is a weekly "system design refresher" issue that bundles several short topics. The headline piece compares three ways to organize data at company scale, and the rest of the issue covers API design, real‑time update patterns, and the SLI/SLO/SLA vocabulary. Below is a teaching‑oriented walkthrough of each section.
1. Data Warehouse vs Data Lake vs Data Mesh
Storing data is the easy part. Deciding where and how to organize it is the real challenge.
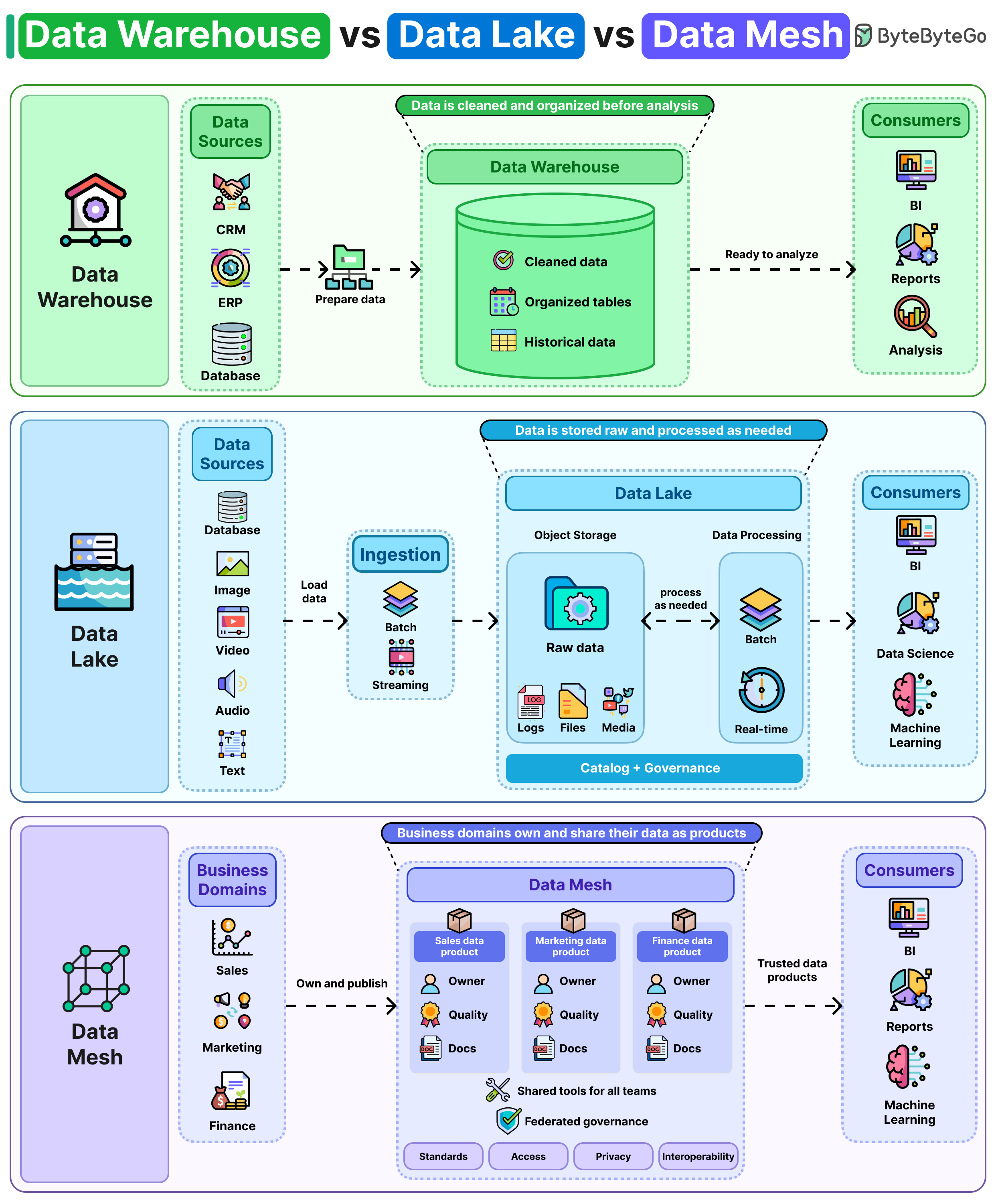
Data Warehouse — clean first, store later
A data warehouse is the traditional approach. Before any data lands in it, you transform it into a predefined schema (tables with fixed columns and types). This is sometimes called schema‑on‑write: you decide the shape up front, then write conforming rows.
- Why it's nice: Because everything is already cleaned and structured, queries run fast and reports stay consistent. Two analysts asking "what was Q3 revenue?" get the same answer.
- Why it hurts: Adding a new data source is slow. You have to model it, fit it into the existing schema, and update pipelines before anyone can use it. Schemas resist change.
Think: BI dashboards, finance reports, executive metrics.
Data Lake — store everything raw, figure it out later
A data lake takes the opposite stance. It dumps everything in raw form: relational rows, JSON logs, images, video, clickstreams, whatever. You apply structure only when you need to read it (schema‑on‑read).
- Why it's nice: Maximum flexibility. New sources can land immediately. Data scientists love this for ML, where you often need raw, unfiltered signals.
- Why it hurts: Without strict rules around naming, formatting, and ownership, a lake silently rots into a "data swamp" — duplicates, stale tables, and undocumented files nobody dares delete. (A reader's comment captures this perfectly: joining a company whose lake was the "single source of truth" and finding four customer tables, two named identically but defining "active customer" differently.)
Think: ML training data, log archives, exploratory analytics.
Data Mesh — distribute ownership to the teams that know the data
Warehouse and lake are both centralized architectures: one platform team owns the data for everyone. Data mesh flips that. Each business domain owns and publishes its own data as a product:
- Sales publishes sales data.
- Finance publishes finance data.
- Marketing publishes marketing data.
Shared standards (naming conventions, schemas, SLAs, discoverability) keep these domain‑owned datasets compatible so other teams can consume them without a translator.
- Why it's nice: Scales with the org. The team closest to the data — the people who actually understand what "active customer" means — owns its quality and definitions. Removes the central data team as a bottleneck.
- Why it hurts: Every domain team now needs the people, tooling, and discipline to run their data like a product: quality, documentation, access control, on‑call. That's a hard cultural and staffing bar.
In practice: pick more than one
Most companies don't choose one. A common combination:
- Warehouse for dashboards and consistent reporting.
- Lake for ML and exploratory workloads.
- Mesh principles layered on top once the org grows enough that a single central team can't keep up.
A reader summed up the deeper truth: this conversation usually starts as an architecture decision and ends as a people problem. The technology works. The hard part is getting thirty engineers across six teams to agree on what "revenue" means.
2. API Concepts Every Software Engineer Should Know
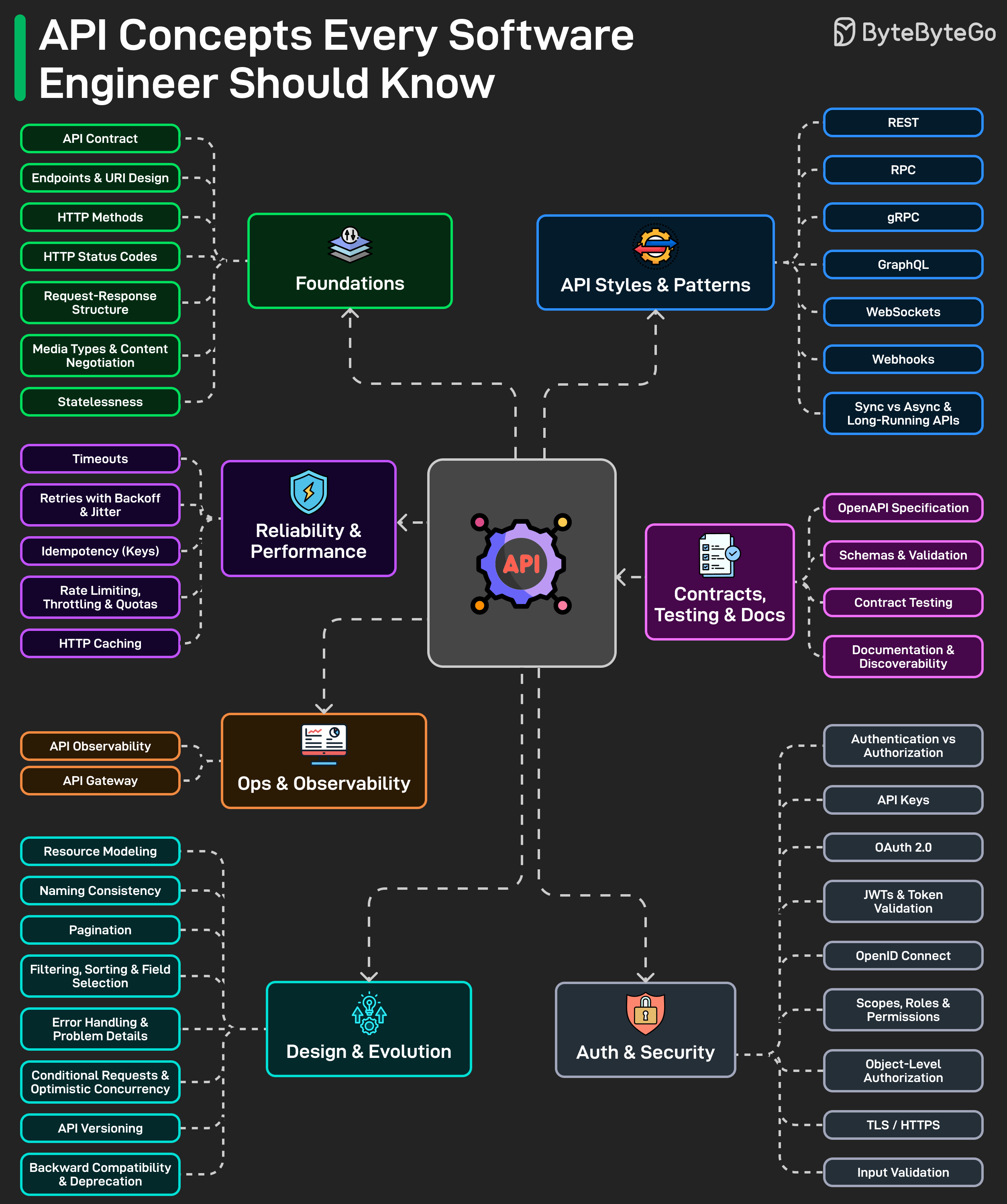
Calling an API is easy. Designing one others rely on is where it gets hard. The piece groups the things to think about into layers:
- HTTP fundamentals. Methods, status codes, request/response shapes. Get these wrong and the API feels confusing and inconsistent before you've even reached business logic.
- Style choice — REST, GraphQL, gRPC, webhooks, WebSockets. Each fits different shapes of problem (resource CRUD, flexible client‑driven queries, low‑latency RPC between services, server‑initiated events, full‑duplex streams). The skill is matching style to use case, not picking a favorite.
- Design decisions that quietly decide quality: naming, pagination, versioning, error response format, backward compatibility. These get ignored early and dominate the maintenance burden later.
- Security: API keys, OAuth, JWTs, scopes, permissions. Easy to name‑drop, hard to wire up correctly; mistakes here are the expensive kind.
- Reliability: timeouts, retries, idempotency, rate limits, caching. These look optional until the system is under pressure, at which point they're load‑bearing.
- The supporting work: clear docs, machine‑readable specs (OpenAPI etc.), observability, contract testing. This is what lets other teams trust the API instead of guessing how it works.
Open question to readers: what's the most overlooked API concept in your experience?
3. Polling vs Long Polling vs Webhooks vs SSE
Four ways for a client to learn that something happened on the server. Each makes a different tradeoff between simplicity, efficiency, and latency.
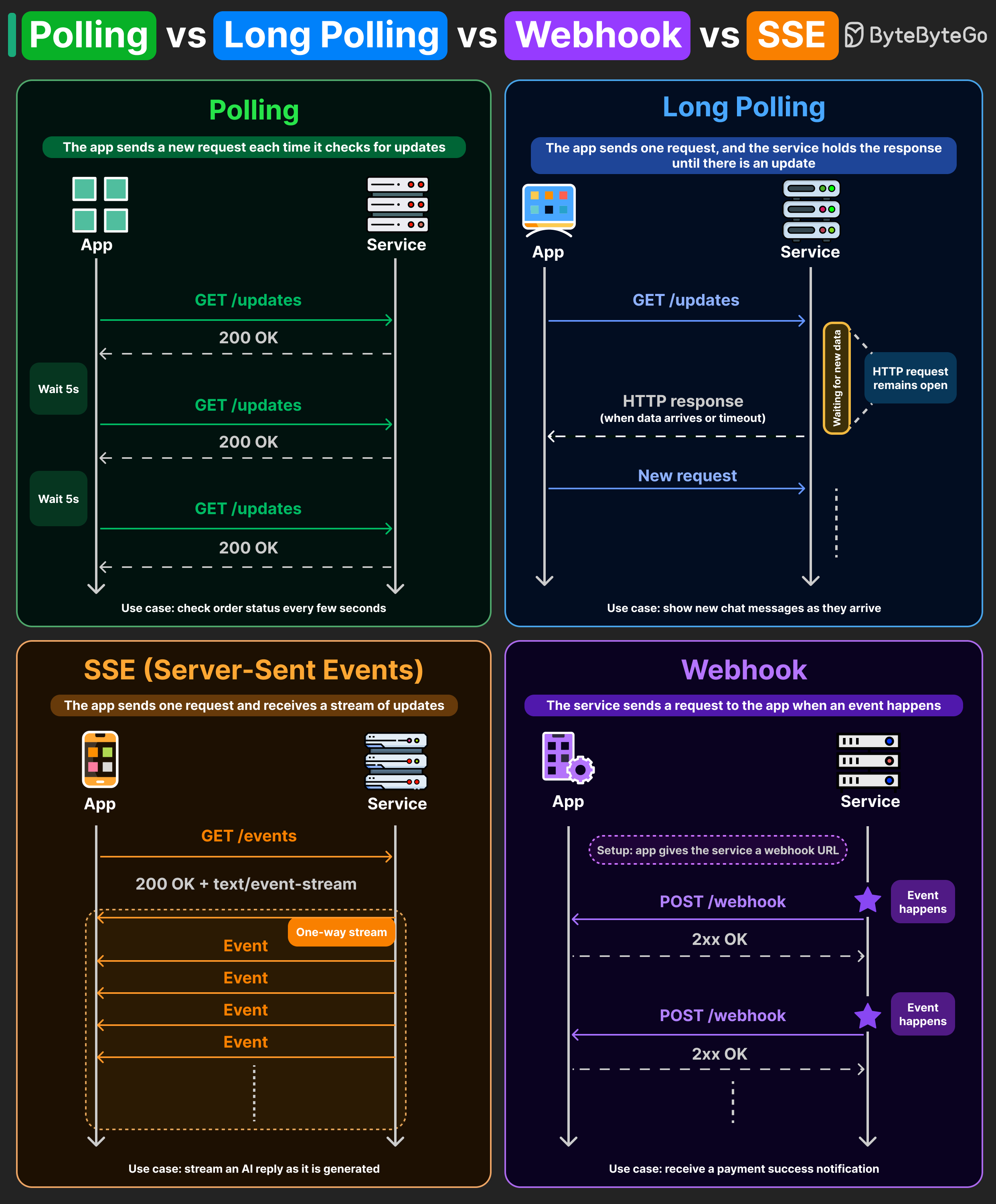
Polling
The client asks "anything new?" every few seconds. The server replies immediately, even when there's nothing.
- Tradeoff: Most responses are empty — wasted bandwidth and CPU on both sides.
- When it's fine: When a small delay is acceptable and simplicity matters. An order‑status page is the classic example.
Long polling
The client sends a request, but the server holds the connection open until either new data appears or a timeout fires. Then the client immediately reconnects.
- Tradeoff: Far fewer empty responses than polling, and updates feel near real‑time. But you're tying up server connections waiting.
- Where you've seen it: Older chat apps used this to deliver messages quickly without a custom protocol.
Server‑Sent Events (SSE)
The client opens one persistent HTTP connection, and the server streams events down it as they're produced. One‑way (server → client), built on plain HTTP, lightweight.
- Where you've seen it: That LLM response that types out token‑by‑token in your browser? Most of those are SSE — each chunk is one event over the same open connection.
Webhooks
Inverted model: instead of the client asking, the server calls the client. The client registers a callback URL, and the server sends an HTTP POST to that URL when an event happens.
- Tradeoff: No polling, no long‑lived connections from the client side. But the client must run a publicly reachable HTTP endpoint and handle retries, signature verification, and duplicates.
- Where you've seen it: Stripe uses webhooks for payment confirmations; GitHub uses them for push events.
Mix and match
Real systems usually combine these. A single product might use polling for order status, SSE to stream AI responses, and webhooks for payment confirmations — each pattern where it fits best.
4. SLA vs SLO vs SLI
Three terms that sound similar, get used interchangeably, and mean genuinely different things. The trick is to read them in order: measure → target → promise.
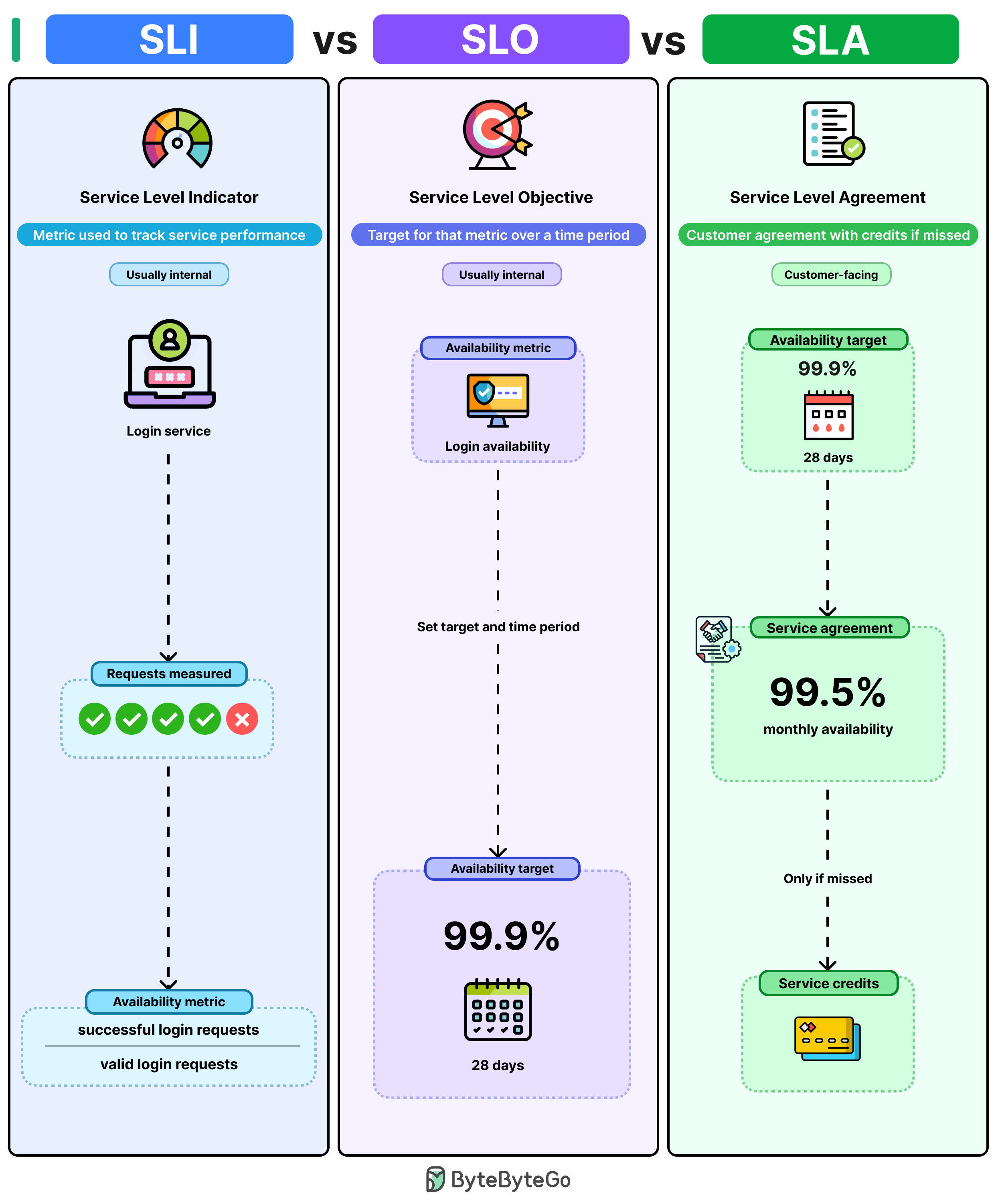
- SLI — Service Level Indicator (the measurement). A concrete metric describing how the service is performing right now. For a login service: successful login requests ÷ total valid login requests.
- SLO — Service Level Objective (the internal target). A goal you set on top of an SLI. Example: "login availability stays above 99.9% over a rolling 28‑day window." When you start missing the SLO, that's your internal alarm — fix it before customers notice.
- SLA — Service Level Agreement (the external promise). A contractual guarantee to customers, usually set looser than the SLO (e.g. 99.5% monthly). Breach it and you owe service credits.
Why the SLA is set lower than the SLO: it gives you headroom. If your SLO and SLA are both 99.9%, the moment you dip below 99.9% you've simultaneously missed your internal goal and breached your contract — no buffer to catch and fix the problem.
Quick mental model:
- SLI tells you where you stand.
- SLO tells you where you should be.
- SLA tells customers what they can expect.
Open question to readers: how do you decide what the right SLO target is when launching a new service?
5. Other items in the issue (briefly)
- Coding Agents Explained: How Claude Code, Codex & Cursor Actually Work — a linked YouTube video, no written content in the post.
- Build with Claude Code — Course Direction Survey — ByteByteGo is shaping a new course and asking engineers/leaders to fill out a 3‑minute survey.
Takeaways for engineers
- Warehouse, lake, and mesh aren't competitors — they're tools for different jobs and life‑stages of a company. Most mature orgs run all three.
- The hardest data architecture problems aren't technical; they're organizational (whose definition of "customer" wins?).
- Pick the right update pattern (polling/long‑polling/SSE/webhooks) per use case rather than standardizing on one.
- Use SLI/SLO/SLA as a layered system: measure honestly, target ambitiously, promise conservatively.
Author
ByteByteGo
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m