Into AI
Diffusion LLMs, Explained Simply
Dr. Ashish Bamania
Apr 23, 2026
Diffusion LLMs, Explained Simply
Source: Into AI · Author: Dr. Ashish Bamania · Date: 2026-04-23 · Original article

⚠️ Note: This post is paywalled on Substack. The summary below covers only the freely accessible introduction (the setup of why diffusion LLMs are interesting, and the mechanics of diffusion borrowed from image models). The deeper sections — “How to apply Diffusion to text?” and beyond — are behind a paid subscription and not included here.
The problem: today's chatbots think one word at a time
Almost every LLM-based chatbot you've used (ChatGPT, Claude, Gemini, etc.) generates its reply token by token, sequentially. A token is roughly a word or a chunk of a word — the unit the model emits at each step.
This is slow. And for a computer engineer, “make it faster” is basically a permanent itch.
The reason for the slowness is structural, not lazy engineering. The Transformer architecture that powers these chatbots is an autoregressive model. Autoregressive just means the next output depends on all the previous outputs. At every single step, the model is answering this one question:
Given all the previous tokens so far, what is the probability distribution of the next token over the entire vocabulary?
That objective has a name: next-token prediction.
A concrete walk-through
Suppose the prompt is "The cat".
- The model looks at
"The cat"and produces a probability distribution over its whole vocabulary — every possible next token gets a probability. Maybe"sat"gets 0.42,"is"gets 0.18,"jumped"gets 0.07, and so on for thousands of tokens. - It picks one — typically the highest-probability one (this strategy is called greedy decoding).
- That picked token gets appended to the prompt: now the input is
"The cat sat". - Repeat. Forever. Until the model decides to stop.
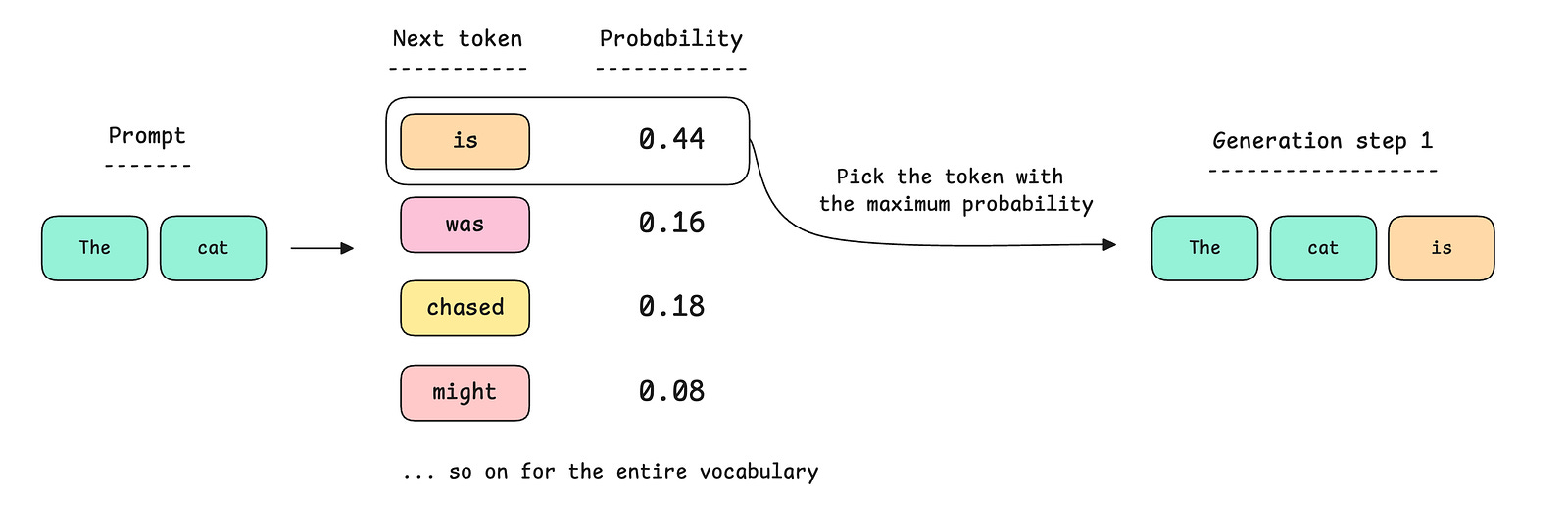
The bottleneck should now be obvious: token N+1 cannot be computed until token N exists. You can throw all the GPUs in the world at it and you still can't generate the 100th token before the 99th. It's an inherently serial dance.
So a natural question pops up:
Is sequential generation the only way?
What if we could generate all the tokens at once, in parallel?
It turns out you can. That's what Diffusion LLMs do — using a process called diffusion (the name is borrowed wholesale from physics).
What “diffusion” means in physics
In real-world physics, diffusion is what happens when you drop ink in water. Particles in a region of high concentration spread out into regions of low concentration until everything is evenly mixed — an equilibrium of pure randomness. Smell spreading across a room, sugar dissolving in tea: same idea.
Image-generation models (think Stable Diffusion, DALL·E, Midjourney) borrowed this idea and turned it into a training recipe with two phases:
1. Forward diffusion — destroying the data
Start with a real image. Then, in many small timesteps, add a tiny bit of Gaussian noise to the pixels each step. (Gaussian noise just means random values drawn from a bell curve — “fuzz” mathematically.)
Repeat enough times and your crisp photo of a cat becomes pure static — indistinguishable from random noise. You've literally diffused the signal away.
2. Reverse diffusion — learning to undo the damage
Now train a neural network to predict the noise that was added at each timestep. If the network can predict the noise, it can subtract it — i.e., it learns to denoise.
Once trained, you can hand the network pure random noise and it will iteratively clean it up, step by step, into a brand-new, never-before-seen image. That's how diffusion-based image models generate.
Both phases are governed by a noise schedule — a recipe specifying how much noise gets added (forward) or removed (reverse) at each timestep. Add it too fast and the model can't learn the structure; too slow and training is wastefully long.

The crucial intuition for LLMs
Notice what diffusion gets you that autoregression doesn't: the model edits the entire output at once. There's no “first token, then second token” — at every denoising step, every pixel of the image gets refined together. Parallel, not serial.
Now imagine doing the same thing but with text: start with a sentence of pure “noise” tokens, and have the model gradually refine all the tokens together in a few denoising passes until a coherent reply appears. Potentially much faster than emitting one token at a time.
The catch: text isn't continuous
There's an immediate technical wrinkle the article flags before the paywall hits:
Pixel values are continuous numbers (e.g. brightness from 0.0 to 1.0). You can add a small bit of Gaussian noise to a pixel and get a slightly noisier pixel — still a valid value. But tokens are discrete: there's no “halfway between the word cat and the word dog.” You can't just add 0.3 of Gaussian noise to the token
"cat"— that has no meaning.
So the central design question for any Diffusion LLM is: how do you define a noise process for discrete tokens? What does it even mean to “corrupt” a sentence a little bit, in a way the model can learn to reverse?
That's exactly the question the rest of the article promises to answer — and it's where the paywall begins.
What's behind the paywall (not summarized here)
The remaining sections, judging by their headers, cover:
- How to apply Diffusion to text? — presumably the standard tricks: replacing tokens with a special
[MASK]token at varying rates (masked diffusion), or working in a continuous embedding space rather than on the discrete tokens themselves. - Likely follow-ups on training objectives, sampling steps, and comparisons to autoregressive LLMs in speed and quality.
If you want those details, you'll need a paid subscription to Into AI.
Takeaways from the free portion
- Why care: Today's chatbots are slow because their architecture forces them to generate one token at a time. Diffusion is a fundamentally different generation paradigm that produces all tokens in parallel, refined over a few denoising passes.
- The mental model: Diffusion = train a network to undo a gradual noising process. Image models do this on pixels; Diffusion LLMs try to do it on text.
- The hard part: Adapting the continuous-noise trick from images to discrete tokens is non-trivial — and is the technical heart of what makes Diffusion LLMs interesting.
Author
Dr. Ashish Bamania
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m