The Product Compass
Claude Code's Limits Are Generous — The Problem Is Your Setup
Paweł Huryn
Apr 27, 2026
Claude Code's Limits Are Generous — The Problem Is Your Setup
Source: The Product Compass · Author: Paweł Huryn · Date: 2026-04-27 · Original article

Note: This is a partial summary — the article is paywalled, and Section 6 (an upgraded subagents instruction block) is behind the paywall. Sections 1–5 below are based on the freely accessible content.
Paweł's headline result: the same Claude Code workflow that cost him €1,184.95 (~$1,389) one month now runs on a Max 20x plan at €180/mo — and after 5 days he had only used 34% of quota despite 8-hour days plus 10+ scheduled workflows. No model swap, no skipping sessions. The fix was setup, not subscription.
Background: between March 23 and April 23, some Max users burned weekly quotas in 1–2 days. Anthropic shipped 3 bug fixes (v2.1.116+) and reset all subscriber limits (see their April 23 postmortem). Those bugs were on Anthropic's side. Four root causes are still on yours, and that's what the article covers:
- Cache misses
- Context bloat
- Wrong model or effort
- Wrong input format
A fifth section covers how to monitor the number you're trying to move.
1. Cache Misses — The Biggest Lever Almost Nobody Watches
Claude Code uses prompt caching: once a "prefix" of your conversation (system prompt, tool list, model config, early turns) has been processed, Anthropic stores it. Subsequent turns reuse it instead of re-paying to process it.
The pricing math is the whole story:
- Cache read: 0.1× the normal input price (10× cheaper)
- Cache write, 5-min TTL: 1.25× input price
- Cache write, 1-hour TTL: 2× input price
- Cache refresh on a hit: free — every hit resets the TTL at no extra cost
The intuition: if you keep hitting the same cached prefix, it stays warm forever for almost nothing. A long session with steady tool use never has to re-pay for the prefix. But the moment the prefix changes, the cache is invalidated and you eat the full input price plus a write cost on the new prefix.
What changes the prefix? The two things that matter most, per Thariq's "Lessons from Building Claude Code":
- Adding or removing a tool mid-session. Including spinning up an MCP server partway through. Lock your tools at session start.
- Switching models mid-session (
/model). Same blow-up.
Healthy hit rate on the default 5-min TTL is ~90%. On the 1-hour TTL it climbs to ~97–99% — but that's API-only and not priced into Pro/Max/Team subscriptions, so it only matters if you're paying per-token directly.
What to do:
- Protect the prefix: don't add MCP servers mid-session, don't
/modelmid-session. - Watch the hit rate (see §5).
- For long API sessions, consider the 1-hour cache: the 2× write cost is more than paid back by the higher hit rate.

2. Context Bloat
For Opus 4.7, the default context is 1M tokens. That sounds great but is expensive: long sessions sprawl, and auto-compact (Claude's built-in "summarize older context to make room" feature) fires later than it should. Paweł's recommendation: disable 1M context and fall back to 200K, which is enough for almost any real task.
On 200K, auto-compact fires around 155K (~80%) — the behavior Boris Cherny described for the previous Opus. The trick is to compact before auto-fires. Once auto-compact triggers, it pushes you over the line and warms a fresh prefix (cache loss). Compact early instead.
His settings:
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1",
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "80"
}
}
That disables 1M context and pins auto-compact at 80%.
2.1 Five Session Moves

/compactat 50% or after every task. Don't wait for auto./clearbetween unrelated work. New session = fresh prefix, no leftover noise./rewindwhen a turn went sideways. Cheaper than re-prompting around bad context that's now baked in.- Subagents for anything that doesn't need the parent's reasoning (next subsection).
2.2 Subagents Are the Underused Move
A subagent is a child Claude session spawned by the parent with its own context window and (optionally) its own model. The parent gets only the subagent's return value, not the conversation it had to do. Anything bulk-mechanical, scoped research, or parallelizable belongs in a subagent: parent context stays clean, and you can downshift to a cheaper model for the grunt work.
A CLAUDE.md task-delegation block he keeps in every project:
## Subagents v1.0
Spawn subagents to isolate context, parallelize independent work, or offload bulk mechanical tasks. Don't spawn when the parent needs the reasoning, when synthesis requires holding things together, or when spawn overhead dominates.
Pick the cheapest model that can do the subtask well:
- Haiku: bulk mechanical work, no judgment
- Sonnet: scoped research, code exploration, in-scope synthesis
- Opus: subtasks needing real planning or tradeoffs
If a subagent realizes it needs a higher tier than itself, return to the parent.
Parent owns final output and cross-spawn synthesis. User instructions override.
2.3 Skills Can Also Be Invoked as Agents
Claude Code "skills" are markdown files with frontmatter. Add agent: true and model: to the frontmatter and the skill runs in its own subagent context with its own model. Example:
---
name: tldr-pdf
description: Extract a 200-word TL;DR from a PDF without loading the full text into the parent context
agent: true
model: sonnet
---
You receive a path to a PDF.
1. Run `pdftotext "$1" -` to extract the text.
2. Read the output.
3. Return only:
- 5-bullet TL;DR
- 3 quotes worth keeping
- Any URLs cited
Never return the full text. Never expand beyond the structure above.
Result: parent gets 200 words back; the full PDF never enters its context window.
2.4 More Techniques That Pay for Themselves on Long Sessions
- Load lean. Disable unused MCP servers, tools, skills, and plugins. Move rules out of
CLAUDE.mdand into skills, custom tools, or referenced.mdfiles (progressive disclosure — only loaded when needed). - Spec prompts. Write requests like a spec: file paths, components, expected I/O, constraints. Vague prompts burn turns and tokens as Claude wanders.
- Skip the search. When you know which file matters, tag it:
@docs/design.mdor@research.md. Don't make Claude grep for what you can hand it directly. - rtk-ai/rtk. A CLI proxy that strips redundant whitespace and compresses tool output. Authors claim 60–90% reduction on raw tool output; Paweł sees ~20–30% overall token reduction in his workflow.
- juliusbrussee/caveman. Drops conversational filler from responses without affecting the model's actual reasoning. Highest savings show up in chat-style sessions.
3. Wrong Model or Effort
Three separate dials, all of which burn tokens fast if left on the wrong setting.
3.1 Effort
Default reasoning effort burns ~2× the tokens of medium for most tasks. Set it per-prompt — not per-session — so only the prompts that actually need deep thinking get it.
/effort low # quick fixes, mechanical tasks
/effort medium # most prompts (huge savings vs default)
/effort high # demanding reasoning
/effort xhigh # default for agentic coding (4.7)
/effort max # diminishing returns; rarely worth the ~2× xhigh cost
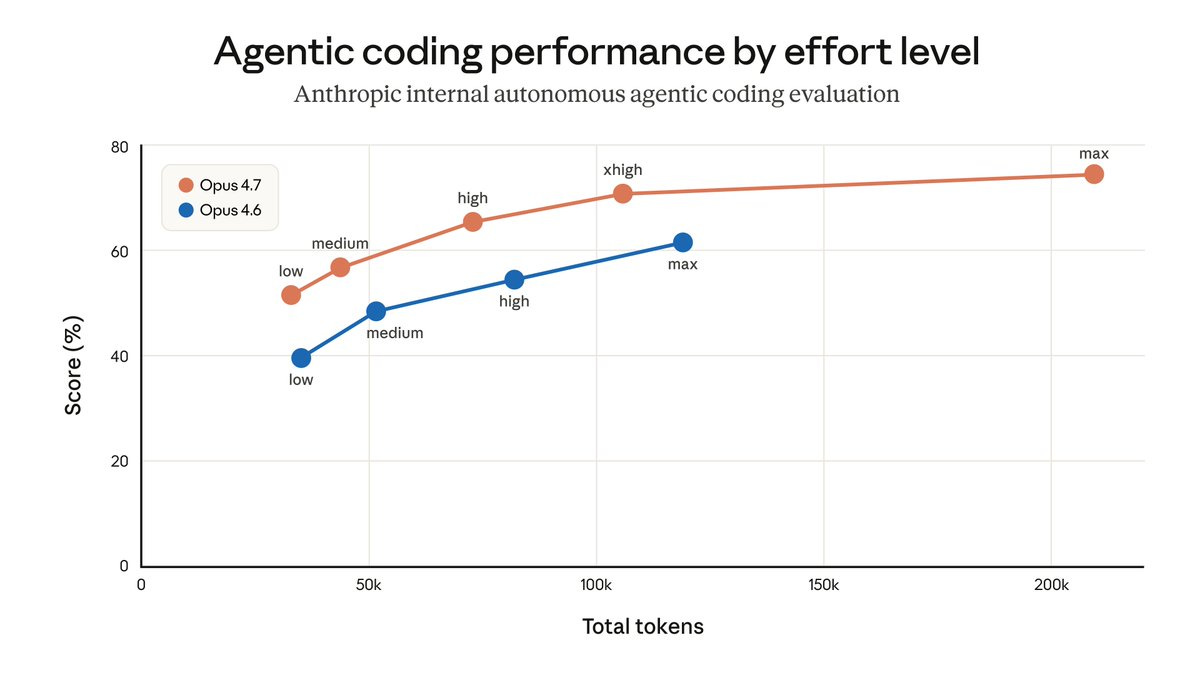
The chart shows performance plateauing well before max while cost keeps climbing — medium is the sweet spot for most prompts, max is rarely worth it.
3.2 Route In (CLAUDE.md)
Pick your session model at start — you can't switch mid-session without nuking the cache (§1). Two patterns:
- Sonnet session. Cheaper, but no Opus available even via delegation. Use when the work is in-scope for Sonnet end-to-end.
- Opus session + delegate. Pay for Opus on the parent (planning, tradeoffs), delegate everything else to cheaper models. His default for mixed work.
Then encode delegation in CLAUDE.md: Haiku for mechanical work, Sonnet for scoped research, Opus for tradeoffs. Note: Opus 4.7 delegates less aggressively than 4.6, so you have to instruct it explicitly (block in §2.2).
3.3 Route Out
Hitting Pro/Max/Team caps but want to keep the Claude Code interface? Point it at OpenRouter or another provider. Example: GLM-5.1 ≈ Opus quality at ~1/12th the cost.
{
"env": {
"ANTHROPIC_BASE_URL": "https://openrouter.ai/api",
"ANTHROPIC_AUTH_TOKEN": "{YOUR-API-KEY}",
"ANTHROPIC_API_KEY": ""
},
"model": "z-ai/glm-5.1"
}
4. Wrong Input Format
Some inputs are token-expensive by default. Three swaps fix most of it.
4.1 Screenshots and Chrome Scraping → agent-browser
vercel-labs/agent-browser drives a real Chrome but returns the accessibility tree (a structured text representation of the page) with element refs (@e1, @e2) instead of rendering and screenshotting. Roughly 90% fewer tokens than "Claude in Chrome" for scraping or page research, because text is dramatically cheaper than image tokens.
npm install -g agent-browser
agent-browser install # downloads Chrome from Chrome for Testing (first run only)
4.2 PDFs → pdftotext, Not Claude's PDF Reader
Claude Code's Read tool loads PDFs as images, which is expensive. Tell Claude to use pdftotext instead. (Works for local PDFs; PDFs attached to chat still need Claude Desktop.) Use Read only when the user explicitly wants charts/images analyzed.
A CLAUDE.md fragment that codifies the §4.1 + §4.2 defaults:
## Preferred Tools
### Data Fetching
1. **WebFetch**: free, text-only, works on public pages that don't block bots.
2. **agent-browser CLI**: free, local Rust CLI + Chrome via CDP. For dynamic pages or auth walls that WebFetch can't handle. Returns the accessibility tree with element refs (@e1, @e2). ~82% fewer tokens than screenshot-based tools. Install: `npm i -g agent-browser && agent-browser install`. Use `snapshot` for AI-friendly DOM state, element refs for interaction.
3. **Notice recurring fetch patterns and propose wrapping them as dedicated tools.** When the same fetch/parse logic comes up more than once, suggest wrapping it as a named tool (e.g. a skill file or a .py script that calls `agent-browser` with the snapshot and extraction steps baked in for that source). Add the entry to `## Dedicated Tools` below and reference it by name on future calls.
### PDF Files
Use 'pdftotext', not the 'Read' tool. Use 'Read' only when the user directly asks to analyze images or charts inside the document. Read loads PDFs as images.
## Dedicated Tools
<!-- List project-specific tools here. For each, link to its skill or script file (e.g. `tools/reddit_fetch.py`). The orchestration logic lives in those files, not here. -->
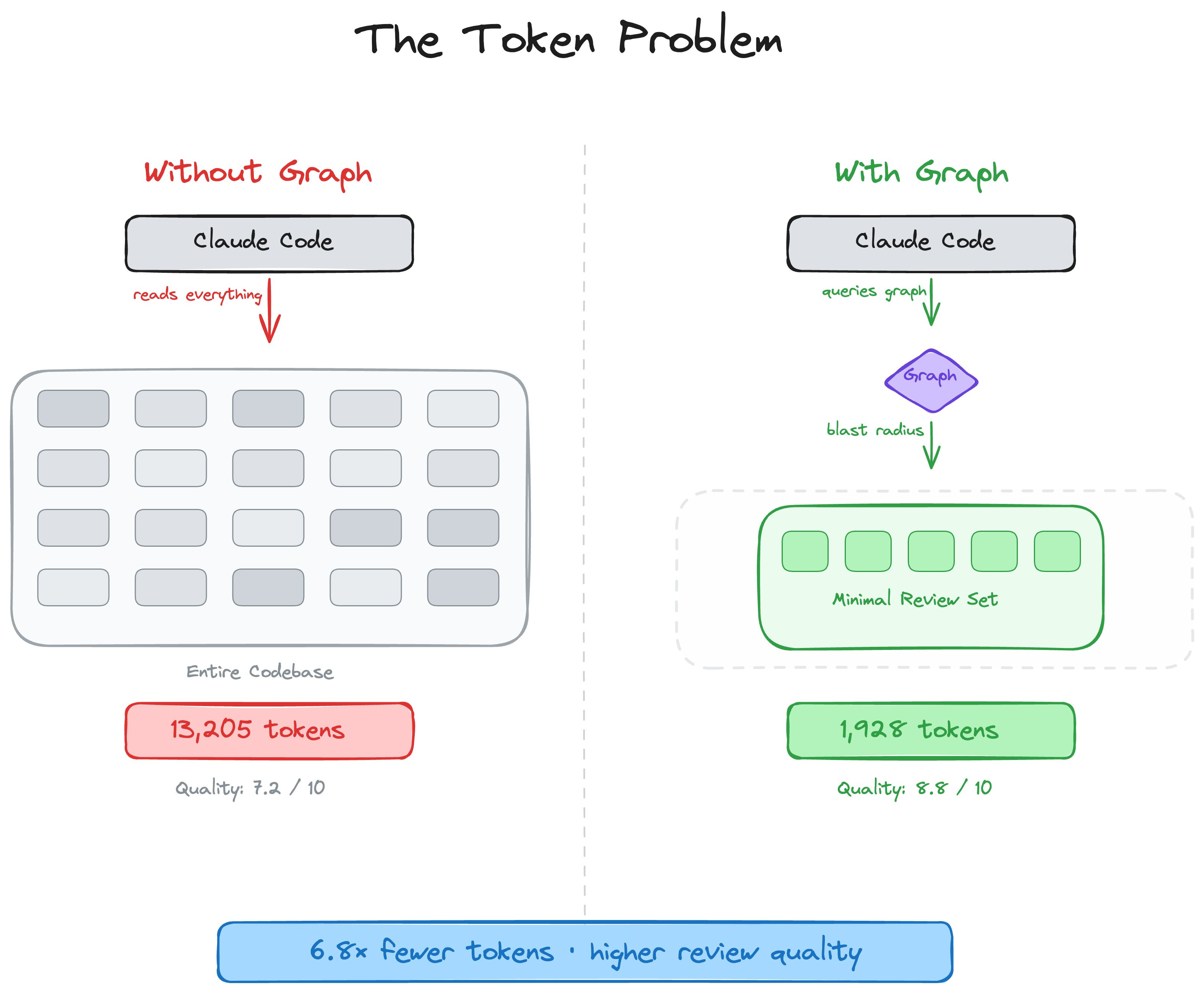
4.3 Large Repos → Code Graph, Not Raw File Reads
AI coding tools tend to re-read your entire codebase on every task. tirth8205/code-review-graph builds a persistent knowledge graph of your code with Tree-sitter, tracks changes incrementally, and exposes precise context to your AI assistant via MCP — so Claude reads only what matters. Claimed: 6.8× fewer tokens on reviews, up to 49× on daily coding tasks. Paweł implemented it on accredia.io and confirms savings on specific tasks (not a flat reduction across all tokens).
5. Watch the Number
You can't fix what you can't see. Three dashboards depending on tier:
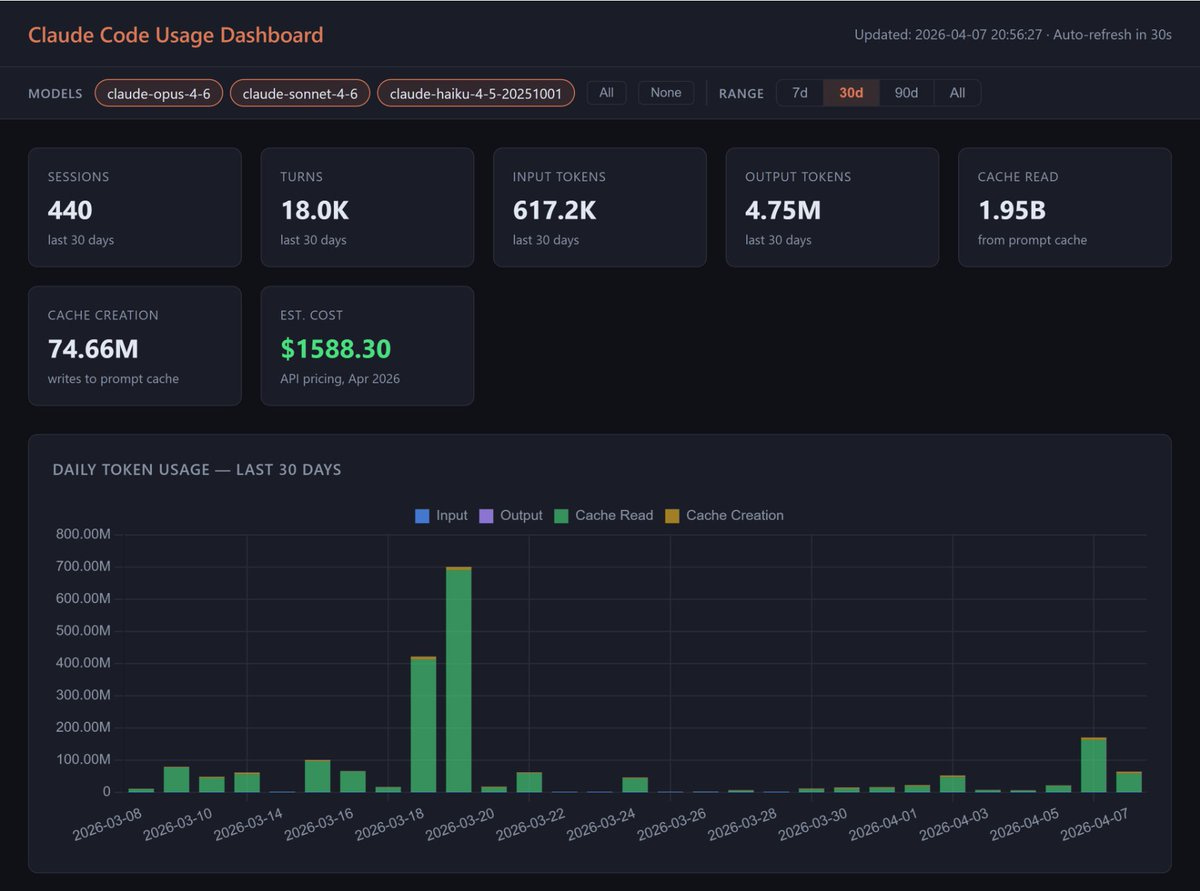
5.1 Historical (Pro / Max / Team)
phuryn/claude-usage: long-term breakdown by session, day, week, all-time. Use it to find where the spend went after the fact.
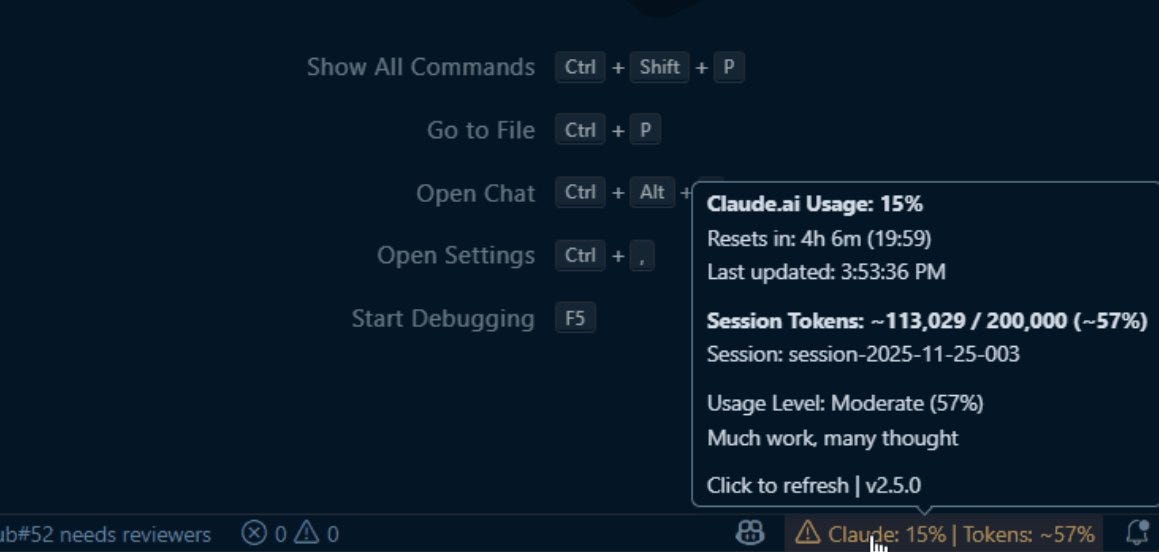
5.2 Real-Time
Gronsten/claude-usage-monitor: current 5-hour window plus active-session tokens, with color thresholds. Tells you how close you are to your cap right now.
5.3 Anthropic's Own Cache Dashboard (API users only)
At platform.claude.com/usage/cache. API only — separate from Pro/Max/Team monitoring. Without visibility into your cache hit rate, you can't fix §1.
6. Upgraded Subagents Instruction Block (paywalled)
Paweł notes that running the v1.0 Subagents block from §2.2 across dozens of sessions surfaced two failure modes:
- Subagents with no strategic context returned compliant-but-useless data, forcing the parent to re-spawn with a better brief and pay twice.
- Unverified data silently propagated into the parent agent.
He shares a v2 block that adds a strategic-context layer to fix both, working across Cowork and Claude Code — but the full block is behind the paywall.
The Mental Model in One Paragraph
Claude Code's per-token cost is dominated by a few choices that multiply each other: a stable prefix keeps the cache cheap (10× discount), a lean context keeps each turn small, the right model and effort dial keeps each token cheap, and the right input format keeps the token count itself small. Tools like agent-browser, pdftotext, code-review-graph, and rtk each attack the input-size axis; subagents and skills-as-agents attack the context axis; /compact, /clear, /rewind, and locked tools/models attack the cache axis; /effort and routing attack the price-per-token axis. Watch your dashboards or none of it sticks.
Author
Paweł Huryn
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m