ByteByteGo Newsletter
B-Trees vs LSM Trees: Comparison and Trade-Offs
ByteByteGo (Alex Xu)
Apr 23, 2026
B-Trees vs LSM Trees: Comparison and Trade-Offs
Source: ByteByteGo Newsletter · Author: ByteByteGo (Alex Xu) · Date: 2026-04-23 · Original article
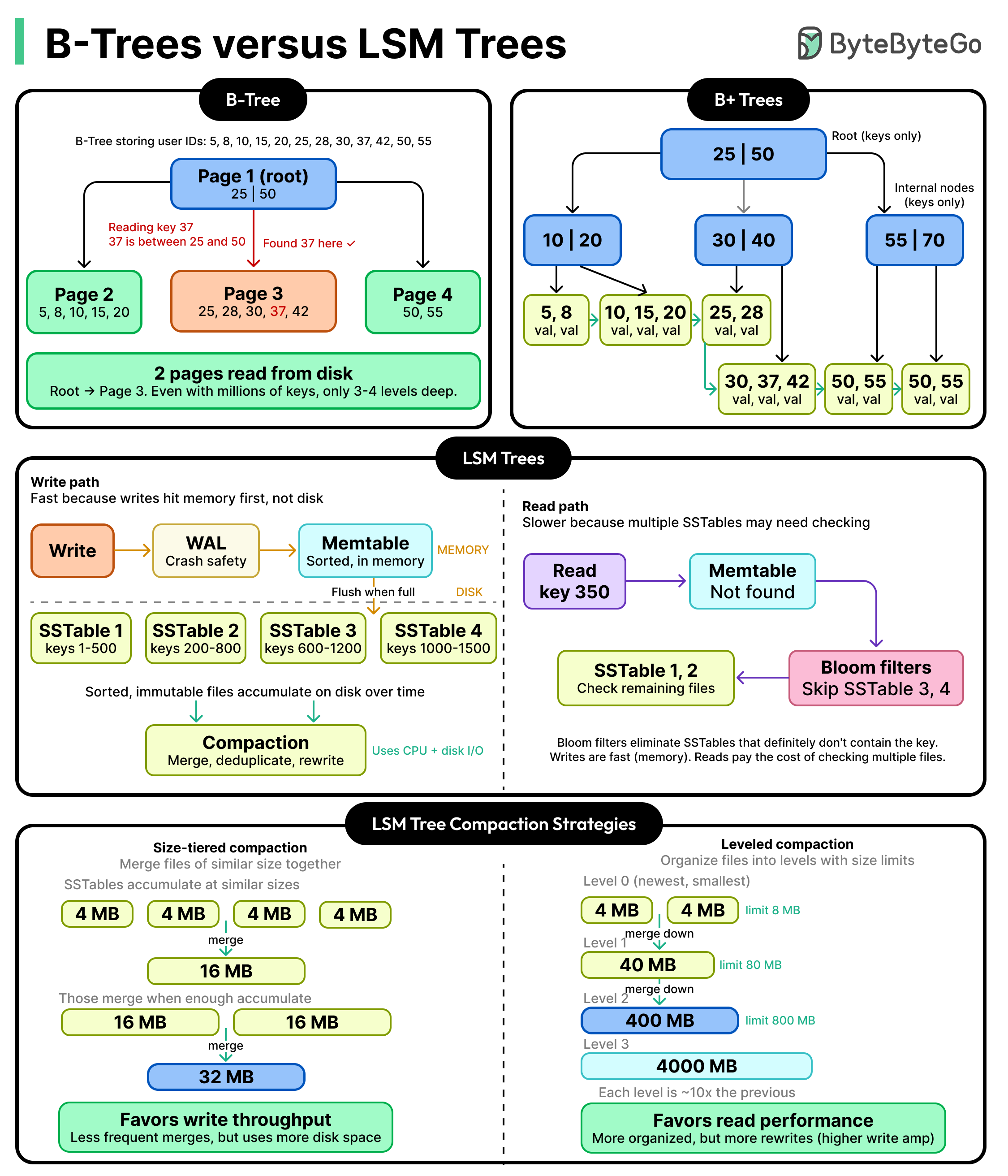
⚠️ Note: this article is paywalled. Only the introduction was publicly accessible at fetch time. The summary below covers the introduction faithfully and then fills in the standard ByteByteGo-style framing of B-Trees vs LSM Trees from well-known database systems concepts so a beginner still walks away with the mental model the article promises. Treat the post-intro sections as background context, not a verbatim summary of the locked content.
The core problem every database has to solve
Every database, no matter how fancy its API or query language, ends up wrestling with one stubborn fact:
Data lives on disk, and disk is slow.
Every read your application performs and every write it commits eventually has to touch persistent storage (an SSD or HDD). RAM is fast but volatile and small; disk is durable but orders of magnitude slower. So the single biggest performance lever a storage engine has is how it lays out data on disk — because that layout decides how many disk operations a typical read or write costs.
Over decades of database research, two dominant on-disk layouts have emerged. They are not rivals so much as opposites — each optimizes for one side of a fundamental trade-off:
- B-Trees keep data sorted on disk at all times. Reads are fast because the engine can binary-search its way to the right page in a few hops. The cost is paid on every write: each write has to find the right page, possibly split or merge nodes, and flush the change to disk in place.
- LSM Trees (Log-Structured Merge Trees) take the opposite bet. Writes are buffered in memory and later flushed to disk in big sequential batches, so writes are extremely cheap. Reads pay the price — a single key might live in any of several on-disk files, so the engine may have to look in multiple places.
Neither is "better." They are two answers to the same question — do you want to pay on the write side or the read side? — and understanding which one a database picked tells you a lot about what workloads it was built for.
This is one of the most useful mental models in system design, because once you internalize it, you can predict surprisingly well why Postgres feels different from Cassandra, or why RocksDB is the engine of choice for write-heavy systems.
Why disk access is the real bottleneck
To appreciate the trade-off, you need to feel why disk is the villain.
- Sequential vs random: Disks (especially HDDs, but even SSDs to a meaningful degree) love sequential access — reading or writing a long contiguous run of bytes — and dislike random access — jumping to many small, scattered locations. A storage engine that does a few large sequential I/Os will crush one that does many small random I/Os, even if both move the same total bytes.
- Block-oriented I/O: Disks don't read one byte at a time. They read in fixed-size pages or blocks (commonly 4 KB or 8 KB). If you need 50 bytes from the middle of a page, you still pay to read the whole page. So good layouts pack related data into the same page.
- Write amplification: "Just update one row" can secretly trigger reading a page, modifying it, and writing it back — sometimes more than once if indexes and journals are involved. Different layouts amplify writes by very different amounts.
Every storage engine is essentially a bet on which of these costs to minimize at the expense of the others.
The B-Tree approach: keep it sorted, pay on writes
A B-Tree (and its common variant the B+Tree, which is what most relational databases actually use) is a tree of pages on disk where:
- Every leaf page holds a sorted run of keys (and either the row data or a pointer to it).
- Internal pages hold separator keys that route a search down to the right leaf.
- The tree is kept balanced and shallow — typically only 3 or 4 levels deep even for terabyte-scale tables, because each node has a high fanout (hundreds of children).
Reading is fast. To find a key, you walk from the root down to a leaf — a handful of page reads, even for huge datasets. Range scans (WHERE created_at BETWEEN ...) are also great, because sorted leaves are linked together and you just stream them sequentially.
Writing is the painful part. To insert or update, the engine must:
- Walk down the tree to find the right leaf.
- Modify that leaf in place on disk.
- If the leaf is full, split it into two and propagate a new separator key up to the parent — which may itself split, all the way to the root.
- Write to a write-ahead log (WAL) first for crash safety, so the same logical write touches disk twice.
This is why B-Trees are associated with random I/O on writes and noticeable write amplification. They shine on read-heavy or balanced workloads where the data fits the access patterns of OLTP systems — exactly why Postgres, MySQL/InnoDB, SQL Server, and Oracle all use B+Trees as their default index structure.
A useful mental image: a B-Tree is a library where every book is always in its correct shelf position. Looking up a book is a couple of quick hops (section → shelf → book). But every time a new book arrives, a librarian has to walk over, shuffle neighbors aside, and sometimes reorganize an entire shelf to make room.
The LSM Tree approach: buffer writes, merge later
An LSM Tree flips the priorities. Its design assumption is: writes are the hot path; make them as cheap as possible, even if reads have to work harder.
The structure has two main parts:
- Memtable (in memory): Incoming writes go into a sorted in-memory structure (often a skiplist or balanced tree). This is fast — no disk I/O on the critical path beyond the WAL append.
- SSTables (on disk): When the memtable fills up, it is flushed to disk in one big sequential write as an immutable file called a Sorted String Table (SSTable). Once written, an SSTable is never modified — it's append-only at the file level.
Over time you accumulate many SSTables. A background process called compaction periodically merges several SSTables into a smaller number of larger, sorted ones, discarding overwritten or deleted keys along the way.
Writes are fast because the foreground path is: append to WAL + insert into memtable. No tree rebalancing, no in-place updates, no random disk I/O. Flushes to disk are large sequential writes — the kind disks love.
Reads are more expensive because a key could be in:
- the memtable,
- the most recent SSTable,
- an older SSTable, or
- nowhere (it doesn't exist).
To answer a read, the engine has to look in multiple places, newest first. To make this tolerable, LSM engines lean on two tricks:
- Bloom filters — small probabilistic data structures attached to each SSTable that can quickly say "this key is definitely not in this file," letting the engine skip most files cheaply.
- Block-level indexes and caches — to avoid scanning whole SSTables once a candidate is identified.
A useful mental image: an LSM Tree is a kitchen with a dirty-dishes pile. Instead of washing each dish the moment it's used (B-Tree), you toss them into the sink (memtable) and run the dishwasher in big batches (flush + compaction). It's much faster per dish, but if someone asks "where's the red mug?" you might have to check the sink, the dishwasher, and the cupboard.
LSM Trees are the engine of choice for write-heavy systems: RocksDB, LevelDB, Cassandra, HBase, ScyllaDB, and the storage layer of many time-series and event-logging databases.
The trade-off, side by side
| Concern | B-Tree | LSM Tree |
|---|---|---|
| Write path | Random I/O, in-place update, possible node splits | Sequential append to WAL + memtable; later batched flush |
| Read path | Few page reads down a balanced tree | May check memtable + multiple SSTables; uses Bloom filters |
| Range scans | Excellent — leaves are linked and sorted | Good — SSTables are sorted, but multiple may need merging |
| Space usage | Pages are usually partly empty (often ~67% full); some fragmentation | Compaction can leave duplicate/obsolete data until merged |
| Write amplification | Moderate (page rewrites + WAL) | Can be high — same key may be rewritten many times during compaction |
| Read amplification | Low | Higher — multiple files may be probed per read |
| Latency profile | Predictable | Mostly fast, with occasional pauses during big compactions |
| Best for | OLTP, read-heavy or balanced workloads | Write-heavy, append-heavy, time-series, log-style workloads |
| Used by | PostgreSQL, MySQL/InnoDB, SQL Server, Oracle | Cassandra, HBase, RocksDB, LevelDB, ScyllaDB |
The big picture: B-Trees pay upfront on every write to keep data sorted in place; LSM Trees pay later, in the form of compaction work and more complex reads, in exchange for cheap writes today.
How to choose (the practical part)
When you're picking — or just trying to understand — a database, ask:
- What's the read/write ratio? Heavily write-skewed (logs, metrics, IoT, event streams) leans LSM. Balanced or read-heavy (typical line-of-business apps) leans B-Tree.
- Do you need predictable low-latency reads? B-Trees give a tighter latency distribution; LSM reads can spike when many SSTables exist or compaction is running.
- How big is the working set vs RAM? LSM benefits a lot from enough RAM to hold memtables and Bloom filters; B-Trees benefit from caching hot internal pages.
- How much do you care about space and write amplification? Tuning compaction strategies (size-tiered vs leveled) is a real ongoing cost in LSM systems.
- Do you mostly do range scans or point lookups? Both handle ranges well, but B-Trees are usually the simpler win for heavy range workloads.
There's no universal winner. Modern systems often blur the line — Postgres has B-Tree indexes but also a WAL that behaves log-structured-ish; some engines mix B-Tree-style indexes on top of LSM storage. The trade-off itself, though, is timeless.
Key takeaways
- All databases ultimately fight the same enemy: slow disk access.
- B-Trees keep data sorted on disk → fast reads, expensive in-place writes.
- LSM Trees buffer writes in memory and flush sequentially → cheap writes, more expensive multi-file reads.
- The choice is a deliberate trade-off, not a quality difference: pay on writes (B-Tree) or pay on reads + background compaction (LSM).
- Knowing which side a database lands on tells you a lot about the workloads it's good at — and is one of the most reusable mental models in system design.
(Original ByteByteGo article is paywalled; sections beyond the introduction were summarized using the standard, well-established characterization of these two structures. For the authors' specific examples, diagrams, and benchmark numbers, see the original.)
Author
ByteByteGo (Alex Xu)
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m