Simon Willison's Newsletter
Qwen3.6‑35B‑A3B on my laptop drew me a better pelican than Claude Opus 4.7
Simon Willison
Apr 27, 2026
Qwen3.6‑35B‑A3B on my laptop drew me a better pelican than Claude Opus 4.7
Source: Simon Willison's Newsletter · Author: Simon Willison · Date: 2026‑04‑18 · Original post
The headline finding
Two big model releases dropped on the same morning: Qwen3.6‑35B‑A3B from Alibaba (an open‑weights model) and Claude Opus 4.7 from Anthropic (a closed, frontier proprietary model). Simon ran his long‑running joke benchmark — "Generate an SVG of a pelican riding a bicycle" — on both. The 21 GB Qwen model running entirely on his MacBook Pro M5 produced the better picture. Anthropic's flagship, with vastly more compute and budget behind it, did not.
That sentence is roughly the entire point of the post, but the why it matters is the interesting part.
A bit of jargon, in plain English
- Qwen3.6‑35B‑A3B — an open‑weights model from Alibaba. The "A3B" refers to it being a Mixture‑of‑Experts (MoE) model: it has 35B total parameters but only ~3B are "active" per token, which is why a quantized (compressed) version can run on a laptop and still feel snappy.
- Quantized — the model's weights have been compressed from 16‑bit floats down to roughly 4 bits each. Specifically Simon ran
Qwen3.6-35B-A3B-UD-Q4_K_S.gguf(about 20.9 GB) packaged by Unsloth, served through LM Studio (a Mac app that runs local models) via thellm-lmstudioplugin for hisllmCLI. - Claude Opus 4.7 — Anthropic's brand‑new top‑tier proprietary model, only accessible via API. It also supports a
thinking_level: maxmode for "harder thinking" on a problem. - Pelican‑on‑a‑bicycle benchmark — Simon's deliberately silly test: ask the model to produce an SVG (text‑based vector image) of a pelican riding a bicycle. The model has to imagine the geometry, compose SVG primitives, and get bird anatomy roughly right — all without seeing what it's drawing.

The Qwen drawing has a correctly shaped bicycle frame, clouds in the sky, a pelican with a (dorky) pouch, and a chirpy "Pelican on a Bicycle!" caption underneath. It's a complete, charming little vignette.

The Opus 4.7 attempt botches the bicycle frame entirely, drops the clouds, and gives the pelican an underwhelming pouch.
Simon then re‑ran Opus with thinking_level: max (let it think harder) and got this:

Slightly better pelican, but the bicycle frame is wrong in a different way. The verdict stays with Qwen.
"I don't think Qwen are cheating"
A natural suspicion when an open model unexpectedly beats a closed flagship is that the lab trained against the benchmark. Simon has written about that and is generally skeptical that labs do — but this result was suspicious enough that he decided to burn one of his secret backup tests to check. He swapped the prompt to "Generate an SVG of a flamingo riding a unicycle" and gave both models a fresh attempt.
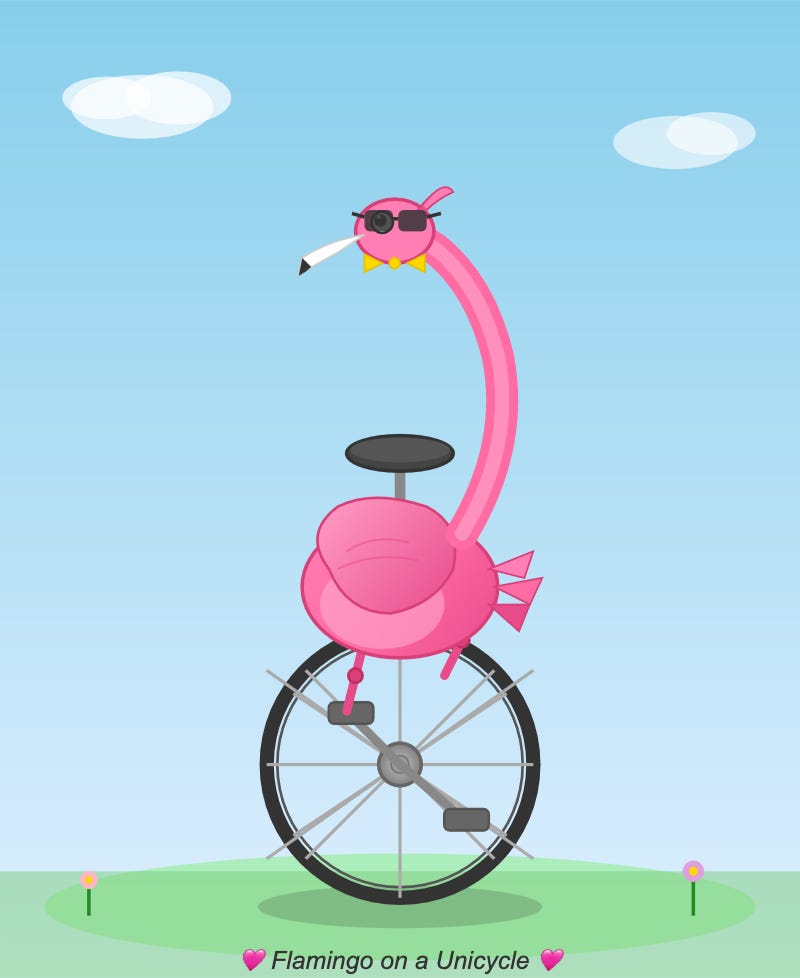
Qwen's flamingo unicycle is full of personality: sunglasses, a bowtie, a cigarette, two heart emoji bracketing the caption. The unicycle spokes are a bit too long, but the overall composition has charisma. Bonus points: the SVG source contains the comment <!-- Sunglasses on flamingo! -->.
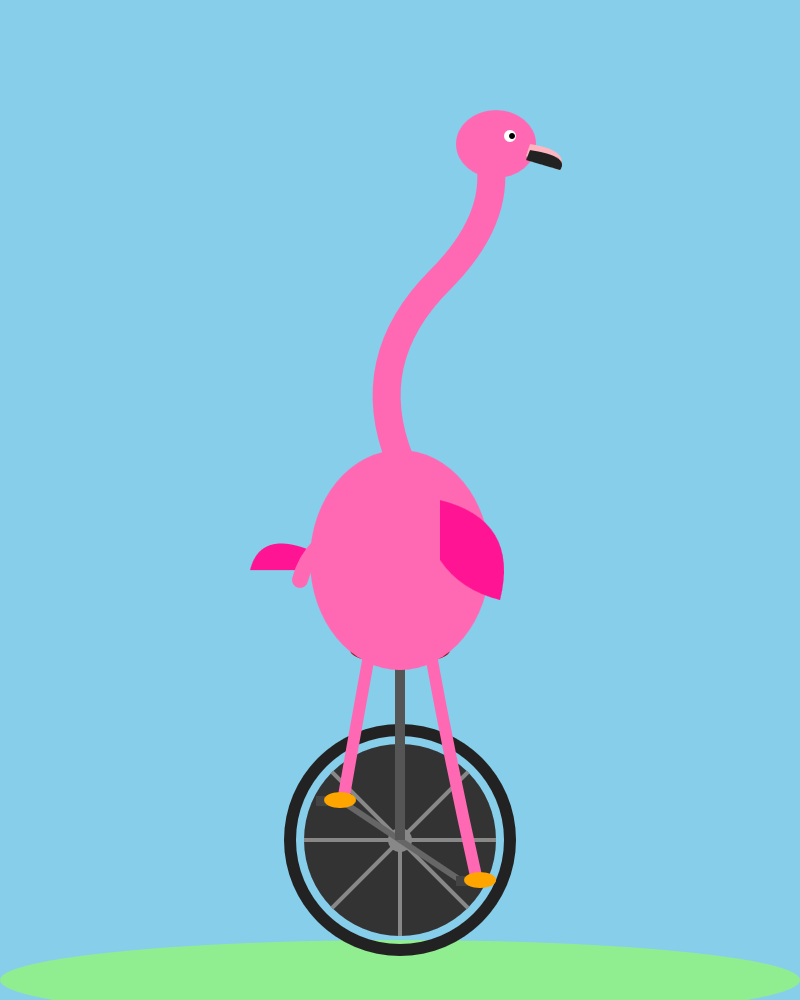
Opus delivers a competent but flavorless vector illustration of a flamingo. Simon awards this round to Qwen as well — and now he's reasonably confident that, on this particular kind of task, Qwen really is just doing better. Not cheating.
What can we learn from this?
Here is the thinking part of the piece, and the bit that's worth slowing down on.
The benchmark was always a joke — but a useful joke
Simon's pelican benchmark started as a way to make fun of how absurd it is to seriously compare these models. The weird thing is that, for a while, it actually tracked something real: the first pelicans from October 2024 were genuinely terrible, and as models got better at general tasks, the pelicans got better too. By the time Gemini 3.1 Pro arrived earlier in 2026, the pelicans were actually usable as illustrations — if you had a pressing professional need for one. So the joke benchmark had become a loose, accidental proxy for general model quality.
Today that proxy snapped. Simon is clear about what that does and does not mean:
- It does not mean Qwen3.6‑35B‑A3B is a more powerful or generally useful model than Opus 4.7. He has "enormous respect for Qwen" but doubts a 21 GB quantized laptop model is broadly stronger than Anthropic's latest proprietary release.
- It does mean that for the very specific task of drawing an SVG pelican on a bicycle, an open‑weights model running on a laptop is, today, the better choice. The pelican benchmark and "general model usefulness" have decoupled.
Why this kind of decoupling makes sense (the bigger context)
Simon connects this to a point Andrej Karpathy made in a tweet Simon quotes at length: AI capability is becoming wildly uneven across access points and domains. The same company can simultaneously ship:
- A free, somewhat orphaned voice‑mode product that fumbles trivial questions (because voice mode runs on much older, weaker models — Simon notes ChatGPT's voice mode reports an April 2024 cutoff, i.e. a GPT‑4o‑era brain), and
- A top‑tier paid coding agent that can autonomously restructure an entire codebase over an hour, or hunt for and exploit security vulnerabilities.
Karpathy's reason: progress is fastest where two conditions both hold — the domain has verifiable rewards (unit tests pass or fail, exploits work or don't), making it easy to train with reinforcement learning; and the domain is commercially valuable in B2B settings, so the biggest share of the team is pointed at it. Drawing whimsical SVGs is neither verifiable nor commercially central, so neither Anthropic nor the open community is optimizing hard for it. Whoever happens to pre‑train on a slightly better mix of internet data wins that day.
The mental model to take away: don't think of "AI capability" as a single number that goes up. Think of it as a jagged landscape where different vendors, model sizes, and even product surfaces (chat vs. voice vs. agent) have very different peaks and valleys. A laptop‑sized model can beat a frontier one on a specific task — that's not a paradox, it's the new normal.
The practical takeaway
If the thing you need is an SVG illustration of a pelican riding a bicycle though, right now Qwen3.6‑35B‑A3B running on a laptop is a better bet than Opus 4.7!
Said less flippantly: it is now genuinely worth keeping a capable local model on your machine, because for some real workloads — especially creative or generative ones where there is no obvious "right answer" to reinforce — it may simply outperform what you can rent from a frontier API. And it costs nothing per query and runs offline.
Also in the newsletter (briefly)
The bulk of the issue is the pelican story above. The rest is Simon's usual run of links, releases, and notes from the past week. A quick tour:
- PyCon US 2026 — the lead item. PyCon US is May 13–19 in Long Beach, with new dedicated AI and Security tracks. Simon is on the PSF board, has been attending PyCon since 2005, and is championing the conference. He'll be an in‑the‑room chair for the AI track and plans to spend time in open spaces (PyCon's unconference‑style sessions) on Datasette and agentic engineering.
asgi-gzip0.3 — a small but instructive bug story. A Datasette instance usingdatasette-gzipwas incorrectly compressingtext/event-streamresponses (Server‑Sent Events). The root cause:asgi-gziphad been extracted from Starlette years ago and a scheduled GitHub Actions workflow that watched Starlette for relevant fixes had silently stopped running, missing Starlette's own fix. Worth filing under "your scheduled jobs may be quietly dead."- Voice mode is weaker than you think — Simon's note expanding on the Karpathy quote above: most users don't realize ChatGPT voice mode is running on an older, weaker model than the chat box on the same site.
- SQLite 3.53.0 — notable bits:
ALTER TABLEcan now add and removeNOT NULLandCHECKconstraints (previously Simon used his ownsqlite-utils transform()helper for this); a newjson_array_insert()function; and significant CLI improvements via a new "Query Results Formatter" library that Simon had Claude Code compile to WebAssembly to make a browser playground. - MLX audio transcription with Gemma 4 E2B — a one‑liner
uv runrecipe to transcribe audio locally on macOS using Google's 10.28 GB Gemma 4 E2B model viamlx-vlm. The transcript he got had charming small errors ("This front here" instead of "This right here") that you can hear are plausible from the audio. - Bryan Cantrill on "the peril of laziness lost" — a quote Simon flags: LLMs lack the human virtue of laziness. Work costs them nothing, so left unchecked they pile abstractions on abstractions and grow systems instead of simplifying them. Human laziness — being unwilling to waste our finite time — is what historically forced us to invent crisp abstractions. It's a tidy framing of a real risk in vibe‑coded codebases.
- Servo on crates.io — Simon explored the new
servocrate (the Rust browser engine, now embeddable as a library) by pointing Claude Code for web at it. The output,servo-shot, is a working CLI tool that takes screenshots of arbitrary pages. Compiling Servo itself to WebAssembly turned out infeasible (heavy threading and SpiderMonkey), but Claude built him a working WASM playground for thehtml5everandmarkup5ever_rcdomcrates so you can paste HTML in the browser and see its parse tree. - Steve Yegge vs. Google on AI adoption — a Yegge tweet claimed Google's internal AI adoption looks like John Deere's: roughly 20% agentic power users / 20% refusers / 60% on Cursor‑level chat tools, with an 18+ month hiring freeze meaning no fresh perspective is arriving. Addy Osmani and Demis Hassabis pushed back hard, claiming 40K+ Googlers use agentic coding weekly and that the post is "completely false." Simon presents both sides without picking one; the interesting signal is the sheer disagreement between very senior people about what AI adoption inside a single company even looks like.
- "Cybersecurity looks like proof of work now" (Drew Breunig) — UK AISI's evaluation of Anthropic's "Claude Mythos" found that the more tokens (and dollars) you spend, the more vulnerabilities the model finds. If that scaling holds, security collapses to a brutal economic race: defenders need to spend more tokens hunting exploits than attackers will spend exploiting them. A non‑obvious corollary: open source libraries get more valuable, because the cost of a thorough AI‑driven security audit is a fixed expense that gets amortized across every downstream user. So the "vibe‑coding makes open source obsolete" thesis gets it backwards.
- OpenAI's GPT‑5.4‑Cyber and "Trusted Access for Cyber" — OpenAI's response to Anthropic's Project Glasswing: a cyber‑permissive variant of GPT‑5.4 plus an identity‑verified access program (photo of a government ID via Persona) for reduced friction. Simon finds the announcement hard to follow and notes the best tools still require an extra Google Form behind the ID check — not exactly the "democratized access" they pitch.
- Datasette PR #2689 — replacing CSRF tokens with
Sec-Fetch-Site— Datasette is adopting the modern header‑based CSRF protection described by Filippo Valsorda and shipped in Go 1.25. Mental model: instead of every form needing a hiddencsrftokenfield that the server signs and re‑validates, the server simply rejects state‑changing requests whoseSec-Fetch-Siteheader indicates a cross‑site origin. Big simplification — all the<input type="hidden" name="csrftoken">lines vanish, and theskip_csrfplugin hook can be removed. Simon is now writing PR descriptions by hand again as a discipline exercise, even though Claude Code did most of the implementation work (cross‑reviewed by GPT‑5.4). - Zig 0.16.0 "Juicy Main" — Zig added a dependency‑injection style
main()signature: declarepub fn main(init: std.process.Init) !voidand the runtime hands you aninitstruct containing a general‑purpose allocator, a defaultIoimplementation, the env var map, and CLI args. Cleaner than reaching out to globals. - Gemini 3.1 Flash TTS — a new prompt‑directable text‑to‑speech model from Google, accessed via the standard Gemini API as
gemini-3.1-flash-tts-preview. The surprising part is the prompting style: their official example for generating a few seconds of audio is a multi‑page "AUDIO PROFILE" document with sections like THE SCENE, DIRECTOR'S NOTES (covering "Vocal Smile," dynamics, pace, accent), SAMPLE CONTEXT, and finally a TRANSCRIPT. Simon swapped "London" for "Newcastle" and then "Exeter, Devon" in the profile and got back convincingly different regional accents on the same lines. He had Gemini 3.1 Pro vibe‑code a small UI for experimenting with it. - Kyle Kingsbury — "meat shields" — a sharp quote from Aphyr's blog: as ML systems take more decisions, organizations will employ humans as accountability sinks — Meta‑style human moderators reviewing automated decisions, lawyers penalized for LLM lies in court, formalized Data Protection Officers, or third‑party subcontractors who can be thrown under the bus when the system misbehaves. A grim but plausible category of future job.
- John Gruber on Apple's app moat — the real Apple moat was never the App Store cut, it was that Apple's platforms had the best apps, which drew users who wanted the best apps. That edge is eroding — not because other platforms are getting better, but because third‑party software on Apple platforms is regressing toward platform‑agnostic mediocrity as developers feel less artistic and financial pull to make idiomatic native apps.
- Datasette 1.0a27 / 1.0a28 /
datasette-export-database/datasette-ports/llm-anthropic0.25 — a clutch of releases. Highlights: 1.0a27 ships the new header‑based CSRF and a newRenameTableEventso plugins likedatasette-comments(which attaches data to tables by name) can react when a table is renamed. 1.0a28 was a quick follow‑up after Simon discovered breakages while upgrading Datasette Cloud — among other fixes it adds adatasette.close()and a pytest plugin that auto‑closes Datasette instances created in fixtures, to stop test suites running out of file descriptors.llm-anthropic0.25 adds theclaude-opus-4.7model withthinking_effort: xhighand newthinking_display/thinking_adaptiveoptions. Most of the 1.0a28 work was implemented with Claude Code driving Opus 4.7. - Tools shipped this week — a tiny GitHub Repo Size tool (GitHub's UI doesn't show repo size, but the API does and it's CORS‑friendly), and a datasette.io news preview UI Simon had Claude build by cloning the
datasette.iorepo, reading itsnews.yaml, and producing an artifact that previews and validates new entries.
The one‑sentence takeaway
The pelican benchmark just decoupled from "general model quality" — and that's not a story about pelicans, it's a story about how AI capability has become a jagged, domain‑specific landscape where a 21 GB laptop model can beat a frontier API for tasks that nobody is specifically training for.
Author
Simon Willison
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m