Lenny's Newsletter
Not all AI agents are created equal — a framework for prioritizing your agent backlog
Unknown Author
Apr 27, 2026
Not all AI agents are created equal — a framework for prioritizing your agent backlog
Source: Lenny's Newsletter · Authors: Hamza Farooq & Jaya Rajwani (guest post, intro by Lenny Rachitsky) · Date: Apr 14, 2026 · Original: https://www.lennysnewsletter.com/p/not-all-ai-agents-are-created-equal

Note: This post is partially paywalled. The summary below covers the freely accessible sections (the framework, Category 1, Category 2, and the opening of Category 3). The detailed Category 3 deep-dive, prioritization criteria, and tool-selection guide for multi-agent networks sit behind the paywall.
The problem: "agent" is an umbrella for very different systems
Every AI leader the authors have talked to (30+ conversations) shows up with roughly the same backlog: a PM assistant, a RAG copilot, a customer-support system, a code-review agent, a voice-enabled shopping assistant — and the same question: "Which one do we build first?"
Teams reach for the familiar impact-vs-effort matrix and immediately hit a wall. Why? Because the things on that spreadsheet aren't comparable:
- One agent takes 6 weeks; another takes 6 months.
- One can be assembled by a PM in n8n; another needs a dedicated ML engineering team.
- One costs $500/month to run; another runs up a six-figure annual LLM bill.
The authors' analogy: you're "comparing apples, oranges, and jet engines on the same spreadsheet." A customer-support assistant and a voice-enabled shopping agent may share the word "agent," but they demand different architectures, teams, infrastructure, and timelines. Until you separate them by kind, any effort/impact estimate is guesswork.
The missing step: categorize before you prioritize
Before "what should we build first?" comes "what type of agent is each idea actually proposing?" The type determines:
- Build complexity
- Required skills and infrastructure
- Timeline
- Operating cost
- How you should measure success
This framing aligns with the broader industry — e.g. the Levels of Autonomy for AI Agents paper and IBM's "Types of AI agents" — and it's how production tools like Claude Code are actually architected.
The framework gives you four things:
- A 5-minute triage to drop every agent idea into one of three architectural buckets.
- A guide for picking the right tool (n8n vs. LangGraph vs. Google ADK).
- Success metrics and ROI frameworks tailored to each bucket.
- Warning signs you've picked the wrong path, and how to switch.
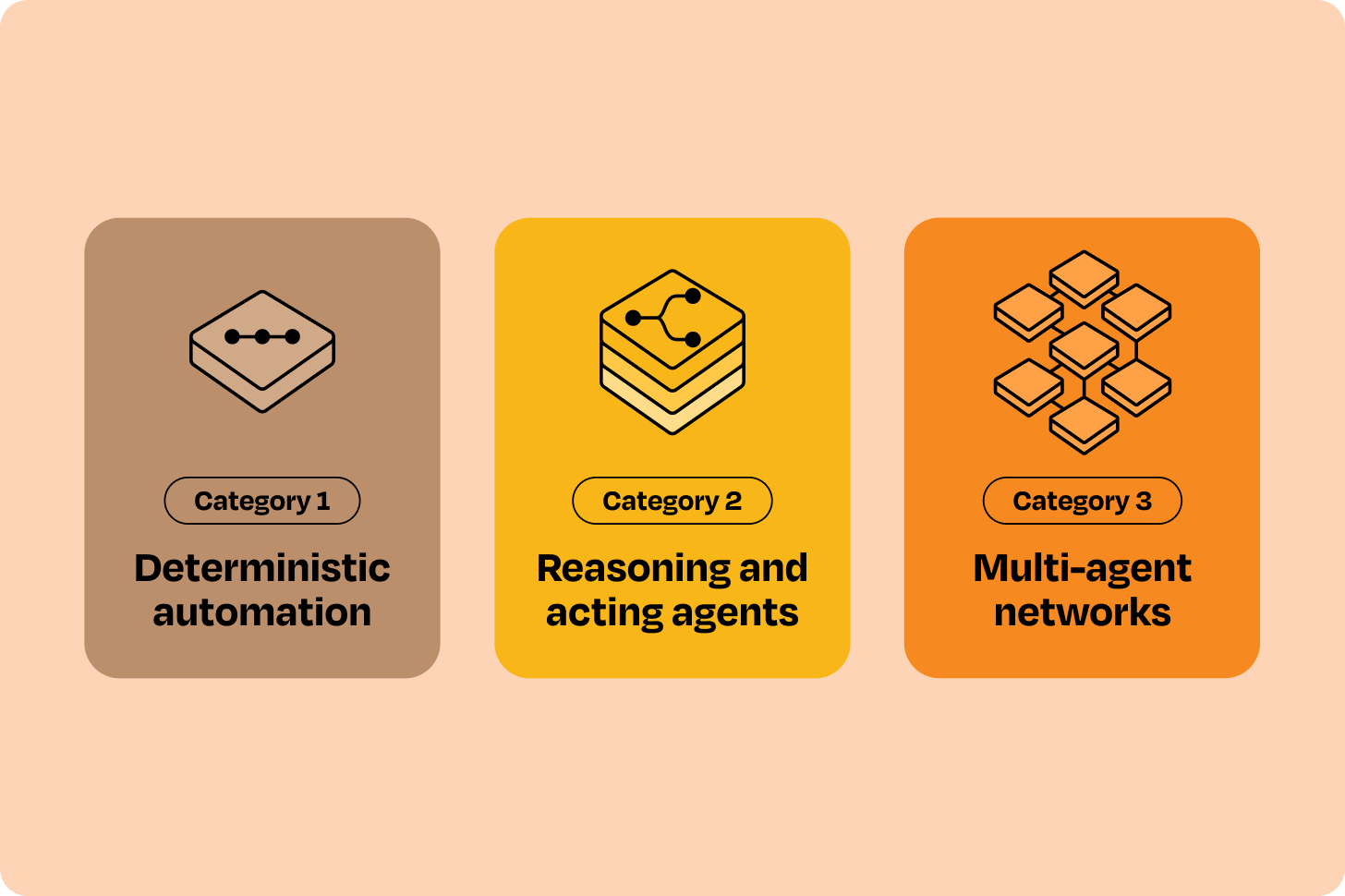
The three categories at a glance
| Category | Who decides what happens next? | Typical tools | Share of agent opportunities |
|---|---|---|---|
| 1. Deterministic automation | You define every step; LLM only fills in content at specific nodes | n8n, Zapier, Make.com, OpenAI AgentKit, Lindy, Gumloop | 60–70% |
| 2. Reasoning & acting (ReAct) | The LLM decides what to do next using tools you provide | LangGraph, CrewAI, AutoGen, Google ADK | 25–30% |
| 3. Multi-agent networks | Multiple specialized agents coordinate with each other | Google ADK, AutoGen | The remainder; rarely the right starting point |
The authors' biggest warning: most teams overengineer, reaching for Category 2 frameworks to solve Category 1 problems — adding cost and complexity for no benefit. Less common but worse: trying to solve Category 2 problems with Category 1 tools, which then breaks in production because the tool isn't robust enough.
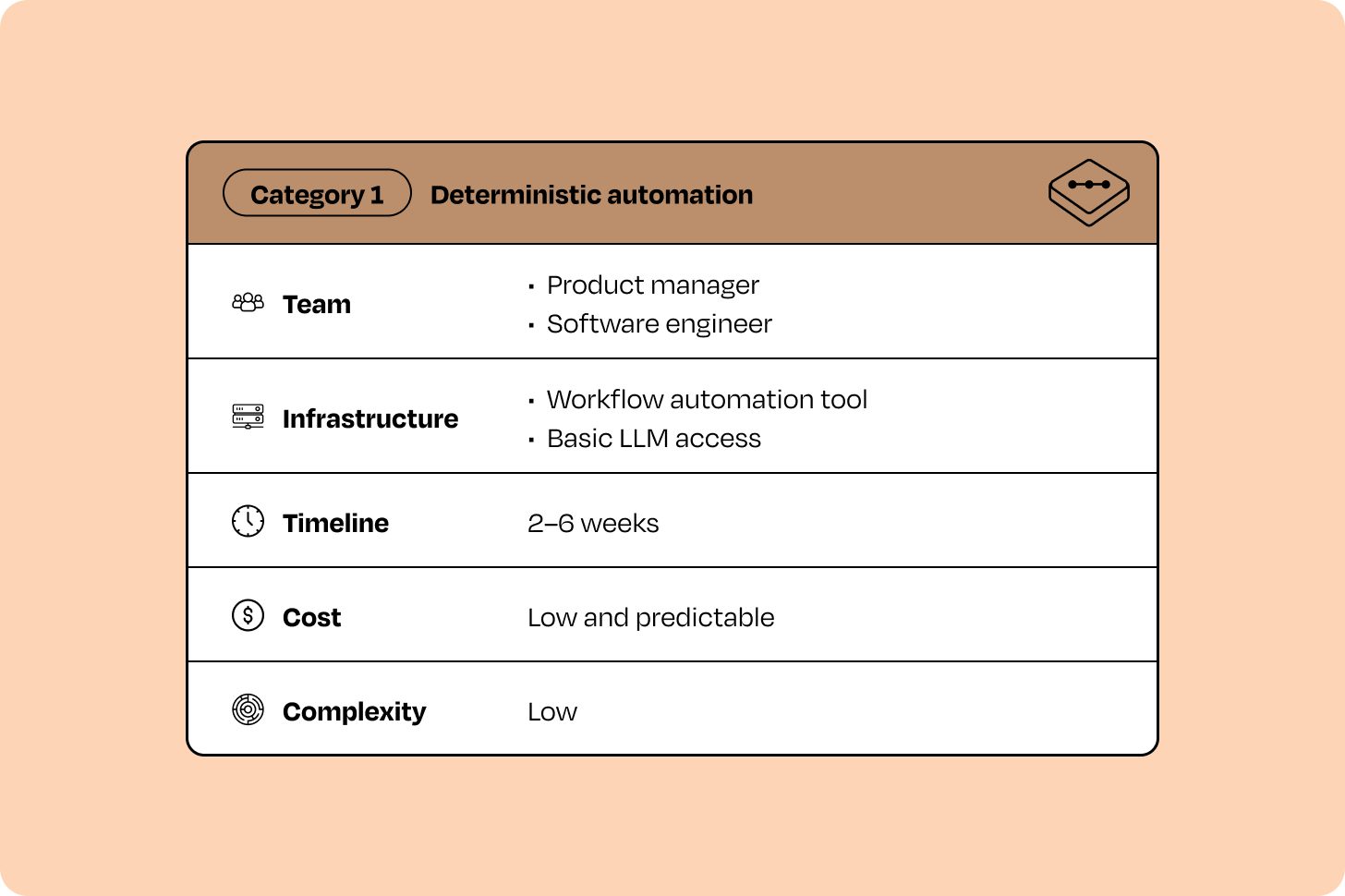
Category 1 — Deterministic automation (the workhorse)
What it is
An "intelligent flowchart." You design every step, every branch, every decision point. The LLM only handles natural-language understanding/generation at specific nodes (classify this email, extract these fields, draft this reply). You control the flow; the LLM controls the content.
Tools: n8n, Zapier, Make.com, OpenAI AgentKit, Lindy, Gumloop. They're built around explicit triggers and predefined branching.
When to start here
Almost always, if you have a backlog. Category 1 projects are simplest to plan, lowest risk to execute, and produce ROI in weeks, not months. They're ideal when:
- The process is already well-defined.
- The work is repetitive and high-volume.
- You have limited AI engineering capacity.
- You're under pressure to ship in weeks.
How to recognize a Category 1 problem
If you can draw the whole process as a flowchart with clear decision points, it's Category 1. Other tells:
- Execution paths are finite and predictable (fewer than ~15–20 branches).
- Tasks complete in seconds to minutes.
- The value is automating a known process, not discovering new approaches.
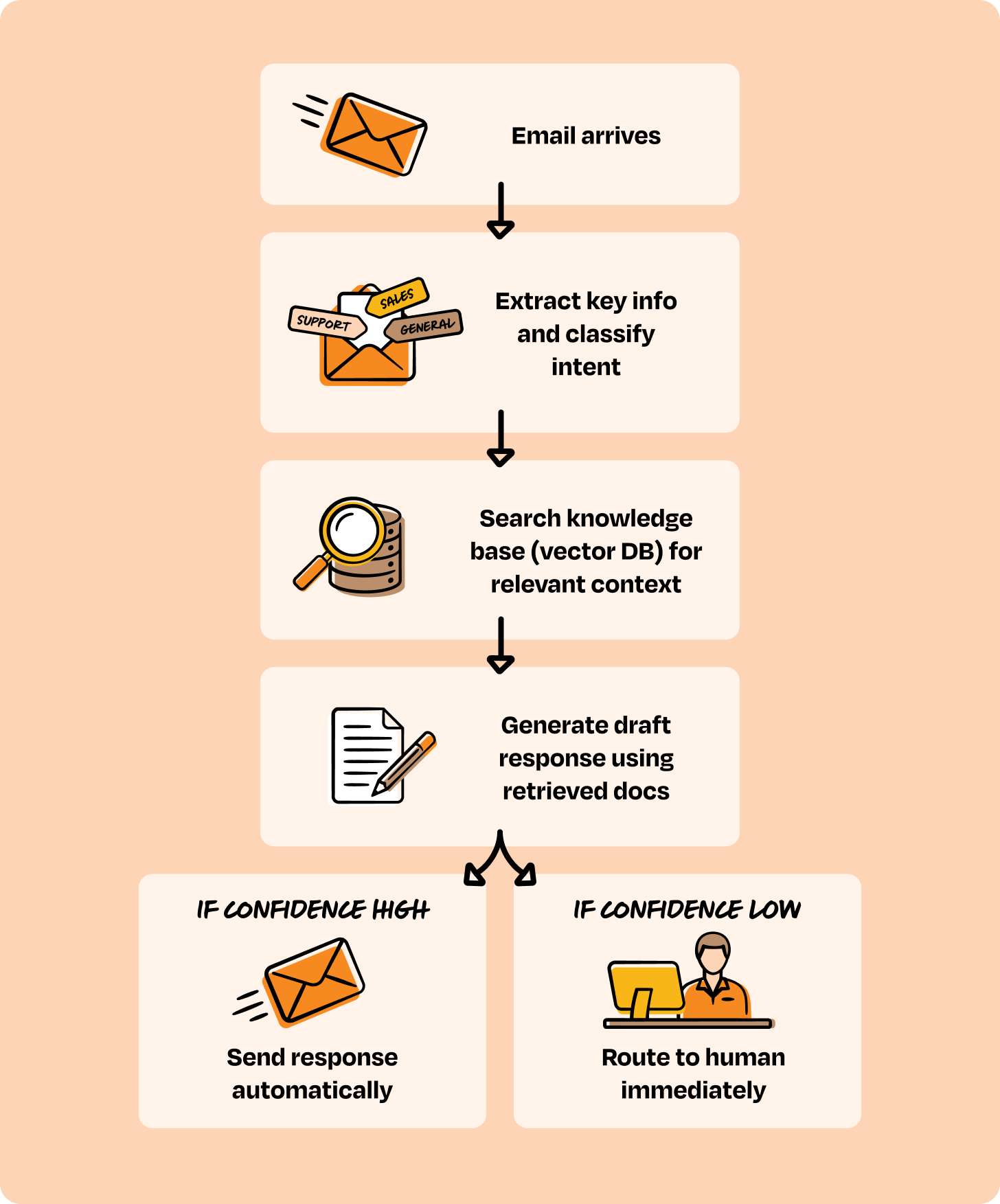
Worked example — customer-email triage. "An AI agent reads incoming customer emails, understands the ask, pulls relevant info from our docs, drafts a reply, and routes to a human for approval." This sounds like sophisticated reasoning. But map it out and every step is predictable: classify → retrieve → draft → route. The intelligence sits inside each step (understanding the email, generating a good reply), not in figuring out what step comes next. Category 1.
Other Category 1 examples:
- A travel-planning agent (the author built one for Airbnb search, used by 10,000+ people).
- A voice-enabled book companion.
- Content automation (e.g., YouTube → LinkedIn).
- A "Perplexity-clone" knowledge base over your org's docs + the web.
- A blog-research-and-draft agent.
- A calorie counter that takes meal photos and recommends dietary changes.
How to evaluate it
The metrics answer one question: did this agent actually automate the right process?
- Workflow completion rate — % of executions that finish successfully
- Automation rate — % of requests handled with zero human touch
- Accuracy — correctness of intent classification, extraction, routing
- Latency — trigger-to-output time (P50/P95)
- Cost per workflow — total LLM + API spend per run
- Error rate — failures from tools/integrations
- Human review rate — % needing manual approval
Real example — SaaS email-support agent:
- Week 1: 52% completion (edge cases everywhere)
- Week 4: 78% (refined classification logic)
- Week 8: 87% (production-stable)
- Result: 3,000 emails/month automated, 2.5 FTE-hours/day freed, ~$18K/month saved.
If completion stays low or human-review rate stays high, the problem may not actually be deterministic enough — that's your signal to look at Category 2.
When you've outgrown Category 1
Watch for:
- The flowchart has 30+ nodes and you're adding branches weekly.
- Customers phrase things in ways you can't anticipate; mapping every variation is impossible.
- The agent needs to choose which API or knowledge source to use based on context, not a predefined path.
- Ambiguous requests need exploration and adaptation, not predefined decomposition.
- The remaining high-value opportunities can't be expressed as predictable workflows.
- You've already automated the obvious quick wins.
Several of these together = move to Category 2.
Category 2 — Reasoning and acting agents (ReAct)
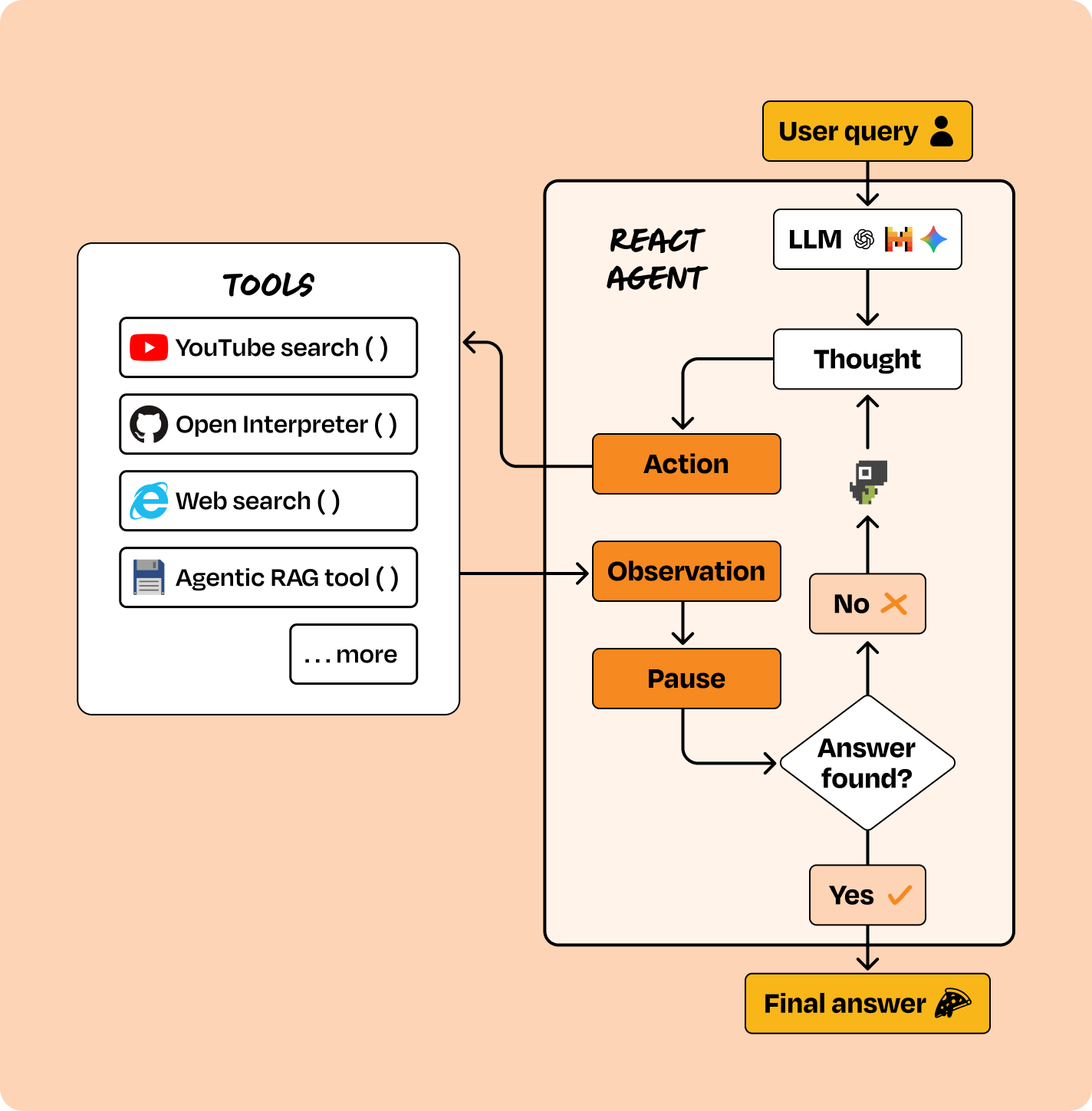
What it is
Instead of defining the flow, you define the available tools (functions the agent can call) and let an LLM decide what to do next. The agent runs a loop:
observe → reason → act → observe result → repeat
Key inversion vs. Category 1: you control the tools; the LLM controls the reasoning.
Tools: LangGraph, CrewAI, AutoGen and other orchestration libraries that support tool use, memory, and dynamic planning.
When to use it
When user requests are ambiguous, workflows can't be mapped in advance, and the value is in flexible contextual decision-making. Category 2 carries higher cost and execution risk than Category 1, but unlocks use cases deterministic automation can't touch.
How to recognize a Category 2 problem
The defining test: the same user request can trigger different action sequences each time. Other tells:
- 5–15+ distinct capabilities, and the right one depends on context.
- User intent is ambiguous and may need a clarifying back-and-forth.
- Multiple input modalities (voice, image, text) need to be interpreted contextually.
- Decomposing complex requests into sub-tasks is itself part of the value.
This fits 25–30% of agent opportunities.
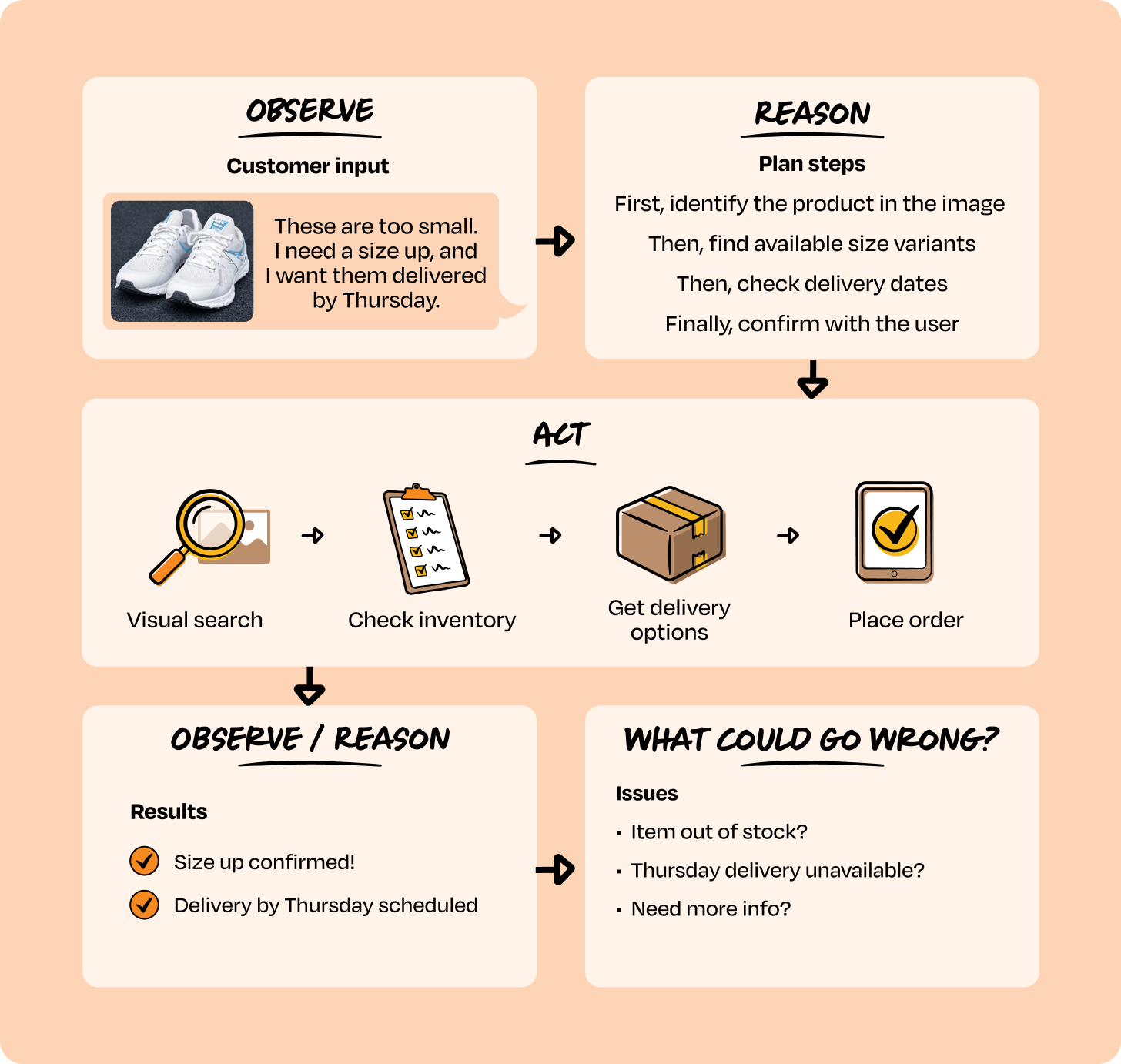
Worked example — voice-enabled shopping assistant. A customer uploads a photo of shoes and says: "These are too small. I need a size up, and I want them delivered by Thursday."
Under the hood:
- Observe — mixed input: image + voice.
- Reason — plan: identify the product → find size variants → check delivery → confirm.
- Act — dynamically picks tools:
visual_search()→check_inventory()→get_delivery_options()→place_order(). - Observe & re-reason — each tool result feeds back into the next decision.
Crucially, this sequence cannot be pre-defined:
- Out of stock? Suggest alternatives.
- No Thursday delivery? Propose pickup.
- Image unrecognizable? Ask a clarifying question.
Same request → different action sequences depending on world state. That's why Category 1 mapping fails here.
Other Category 2 examples:
- Conversational customer support.
- A code assistant that modifies repos (e.g., Claude Code).
- An intelligent personal shopping assistant.
- IT troubleshooting agent.
- A sales copilot that researches accounts and drafts outreach.
- A multimodal assistant combining voice, image, and text.
How to evaluate it
Question to answer: was dynamic reasoning actually necessary, or could this have been a simpler workflow?
- Task completion rate — % of sessions where the user's goal is achieved
- Reasoning accuracy — correctness of decomposition, tool choice, ordering
- Conversation length — average turns to resolution
- Multimodal accuracy — image/voice/structured-input interpretation
- Tool-call efficiency — average tool calls per successful session
- Latency — per turn and end-to-end
- Cost per session — LLM + API spend per interaction
- User satisfaction — CSAT or equivalent
- Business impact — lift in conversion, retention, or task success vs. baseline
Real example — voice + image shopping assistant for a home-goods retailer:
- Month 1: 71% task completion, longer chats, higher tool usage, $0.12/session
- Month 4: 86% task completion, shorter chats, fewer tool calls, $0.08/session
- Image-recognition accuracy: 76% → 91%; conversion lift: +8% → +22%; CSAT: 4.0 → 4.5.
The healthy pattern: completion rate goes up while conversation length, tool calls, and cost per session go down. If completion stalls while costs stay high, the problem is over-scoped and probably belongs in Category 1.
When you've outgrown Category 2
- A single agent is juggling too many domains (support + inventory + logistics + finance) and quality is degrading.
- You need agents to delegate to other agents, not just call stateless APIs (e.g. shopping agent asks an inventory agent: "Check all warehouses and suggest alternatives.").
- Tasks take hours or days (e.g., an eval agent processing 10,000 conversations overnight).
- You need hundreds of agent instances running in parallel and coordinating.
- Different teams want to own their own specialized agents but those agents must work together.
Two or three of these at once → time for Category 3.
Category 3 — Multi-agent networks (intro only — rest paywalled)
What it is
Instead of one agent calling tools, you have multiple specialized agents that coordinate with each other. Each agent is owned by a different team, handles its own domain, and can request help from peer agents. Think enterprise systems built on Google ADK or AutoGen.
These are typically reserved for late-stage roadmaps where multiple teams must coordinate across domains. They should almost never be where a roadmap starts.
The remainder of the Category 3 deep-dive — when to prioritize, recognition criteria, evaluation metrics, real-world examples, and the full tool-selection guide — is behind Lenny's paywall.
The big takeaways
- "Agent" is an umbrella term, not a category. Stop ranking deterministic workflows, ReAct agents, and multi-agent networks on the same effort/impact matrix.
- Categorize first, then prioritize. The category dictates timeline, team, infrastructure, cost, and metrics.
- Most opportunities (60–70%) are Category 1. Start with deterministic workflows in n8n/Zapier/AgentKit-style tools. They ship fast, prove ROI, and build org confidence.
- Reach for Category 2 only when the same input can legitimately produce different action sequences. Otherwise you're paying ReAct prices for Zapier-level work.
- Multi-agent networks are an end-state, not a starting point. Use them when delegation, parallelism, or cross-team ownership genuinely demands it.
- Watch the metric trend, not the snapshot. A healthy agent shows rising completion with falling cost, latency, and human-review rate. If those move the wrong way together, you've probably picked the wrong category.
Author
Unknown Author
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m