ByteByteGo Newsletter
How LinkedIn Feed Uses LLMs to Serve 1.3 Billion Users
ByteByteGo
Apr 13, 2026
How LinkedIn Feed Uses LLMs to Serve 1.3 Billion Users
Source: ByteByteGo Newsletter · Author: ByteByteGo · Date: 2026-04-13 · Original article
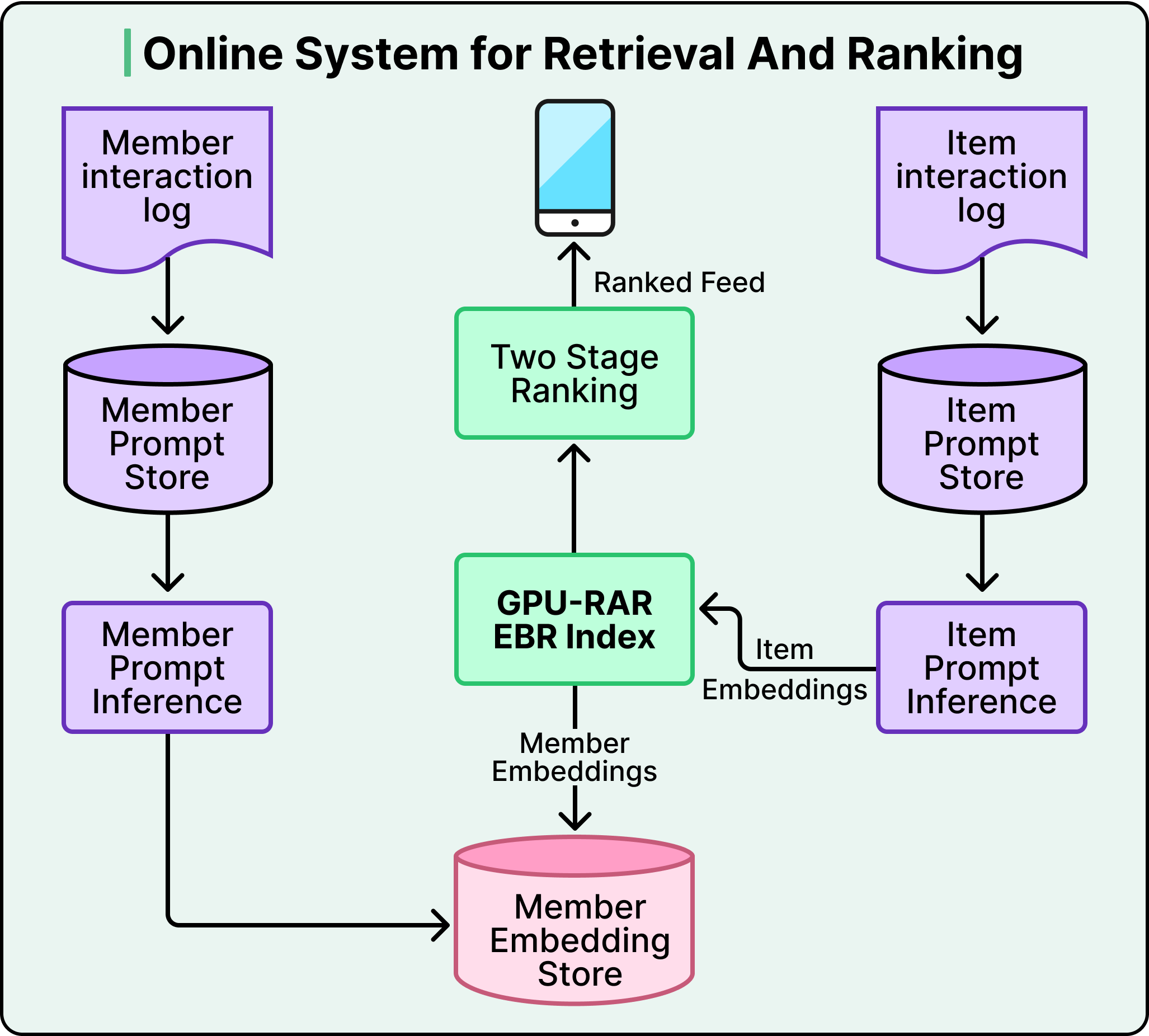
LinkedIn used to run five separate retrieval systems just to decide which posts to show you in the Feed — a chronological index of activity in your network, a trending-content service, a collaborative-filtering pipeline, several embedding-based retrievers, and industry-specific pipelines. Each had its own infrastructure, its own team, and its own optimization logic. The setup worked, but optimizing one source could degrade another, and no team could tune them all at once. So the Feed team made a radical bet: rip all five out and replace them with a single LLM-powered retrieval model. That solved the complexity problem but raised three new ones — how do you teach an LLM to understand structured profile data, how do you make a transformer answer in under 50 ms for 1.3 billion users, and how do you train it when most engagement data is noise?
This is a walk-through of how they did it.
Five librarians, one library
Picture the old setup as five different librarians, each with their own card-catalog system, each shouting recommendations at you when you walked into the library. You got variety, but no one librarian could see the whole shelf. If the trending-posts librarian got better at her job, the collaborative-filtering librarian's picks suddenly looked worse by comparison — and there was no shared dial to turn.
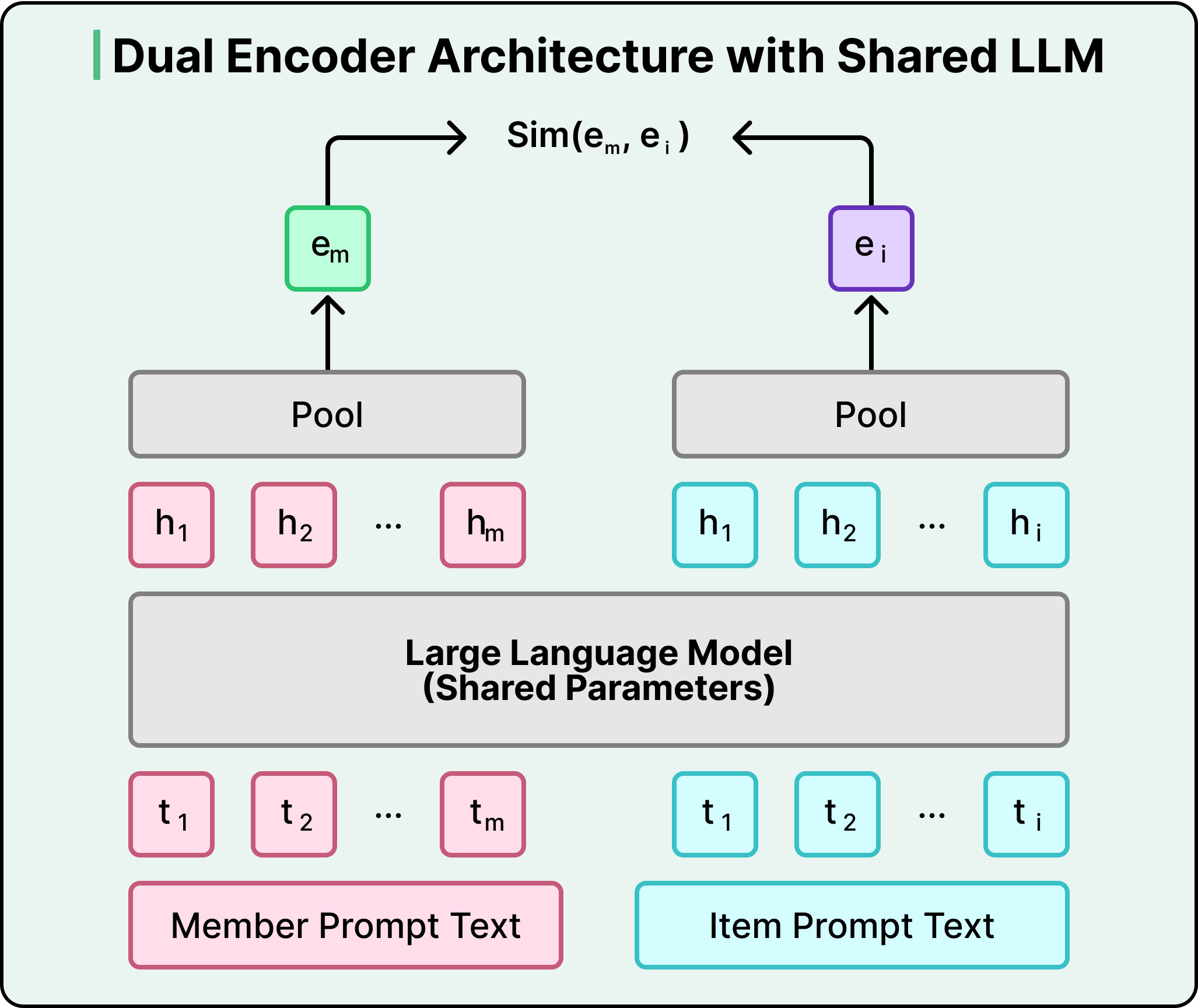
The replacement is a dual-encoder architecture built on a shared LLM. A dual encoder is just two copies of the same model: one converts a member into a vector, the other converts a post into a vector — both vectors live in the same mathematical space. Training pushes a member's vector and a post's vector closer together when there's real engagement, and farther apart when there isn't. At serve time the system grabs your member embedding and runs a nearest-neighbor search over the post-embedding index to pick candidates — all in under 50 ms.
The real win is what the LLM brings to those embeddings. A keyword-based system matches surface text overlap: if your profile says electrical engineering and a post is about small modular reactors, a keyword system misses the link. The LLM doesn't, because pretraining gave it world knowledge — it knows electrical engineers often work on power-grid optimization and nuclear infrastructure. This is especially valuable in cold-start situations, where a brand-new member only has a profile headline and no engagement history yet. The LLM can infer likely interests right away.
There's a second, subtler benefit downstream. Because every candidate now comes from the same semantic-similarity process instead of five biased sources, the ranking layer that comes next sees a coherent candidate set. Ranking becomes easier, and every improvement to the ranking model now actually compounds.
But the model takes text, and recommendation systems run on structured data and numbers. So how do you feed structured data to an LLM?
The model is only as good as its input
LinkedIn built a prompt library — essentially prompt engineering for recommender systems — that converts structured features into templated text. For posts, the template includes author info, engagement counts, and the post text. For members, it includes profile info, skills, work history, and a chronologically ordered sequence of posts they've engaged with.
The most striking lesson came from numerical features. At first they passed raw numbers straight in: a post with 12,345 views became views:12345 in the prompt. The model just treated those digits like ordinary text tokens. When the team measured the correlation between item popularity and embedding similarity, it was essentially zero (-0.004). Popularity is one of the strongest relevance signals in recommendation — and the model was completely ignoring it.
The reason is fundamental: LLMs don't understand magnitude. To them 12345 is just a sequence of digit tokens, not a quantity. The number 12346 looks no more similar to 12345 than the word "apple" does.
The fix was simple. Convert raw counts into percentile buckets wrapped in special tokens: views:12345 becomes <view_percentile>71</view_percentile>, meaning this post sits in the 71st percentile of view counts. Most values 1–100 get processed as a single token, which gives the model a stable, learnable vocabulary for "how big." It can now learn that "above 90 = very popular" without trying to parse arbitrary digit strings.
The result:
- Correlation between popularity and embedding similarity jumped 30×.
- Recall@10 (does the top-10 retrieved set actually contain relevant posts) improved 15%.
The same trick was applied to engagement rates, recency signals, and affinity scores.
Less data, better model
For training, the team's first instinct was to give the model the member's whole interaction history — every post that was shown, whether the member engaged or scrolled past. More data, better model, right?
Wrong. Including scrolled-past posts made performance worse and made training much more expensive. (Transformer compute scales quadratically with context length, so longer sequences cost a lot.) When they filtered the history down to only positively-engaged posts, everything got better:
- Memory per sequence dropped 37%.
- The system could process 40% more training sequences per batch.
- Training iterations ran 2.6× faster.
The reason is signal clarity. A scrolled-past post is ambiguous — maybe it was irrelevant, maybe the member was busy, maybe the headline was mildly interesting but not enough to stop. A post you actively engaged with is a clean, unambiguous signal of interest. And once training is faster, you can run more experiments, tune hyperparameters more aggressively, and improve quality further — the gains compound.
Training also used a clever negatives strategy — examples the model should learn not to match:
- Easy negatives: random posts the member was never shown. These teach broad contrast (this post is nothing like what you care about).
- Hard negatives: posts that were shown to the member but they didn't engage with. These are the almost-right cases that force the model to learn fine-grained distinctions between "relevant" and "actually valuable."
Adding just two hard negatives per member improved recall by 3.6%.
The Feed is a story, not a snapshot
With retrieval producing high-quality candidates, the next question was ranking. Traditional ranking models score each (member, post) pair independently. That works, but it misses how people actually consume content over time.
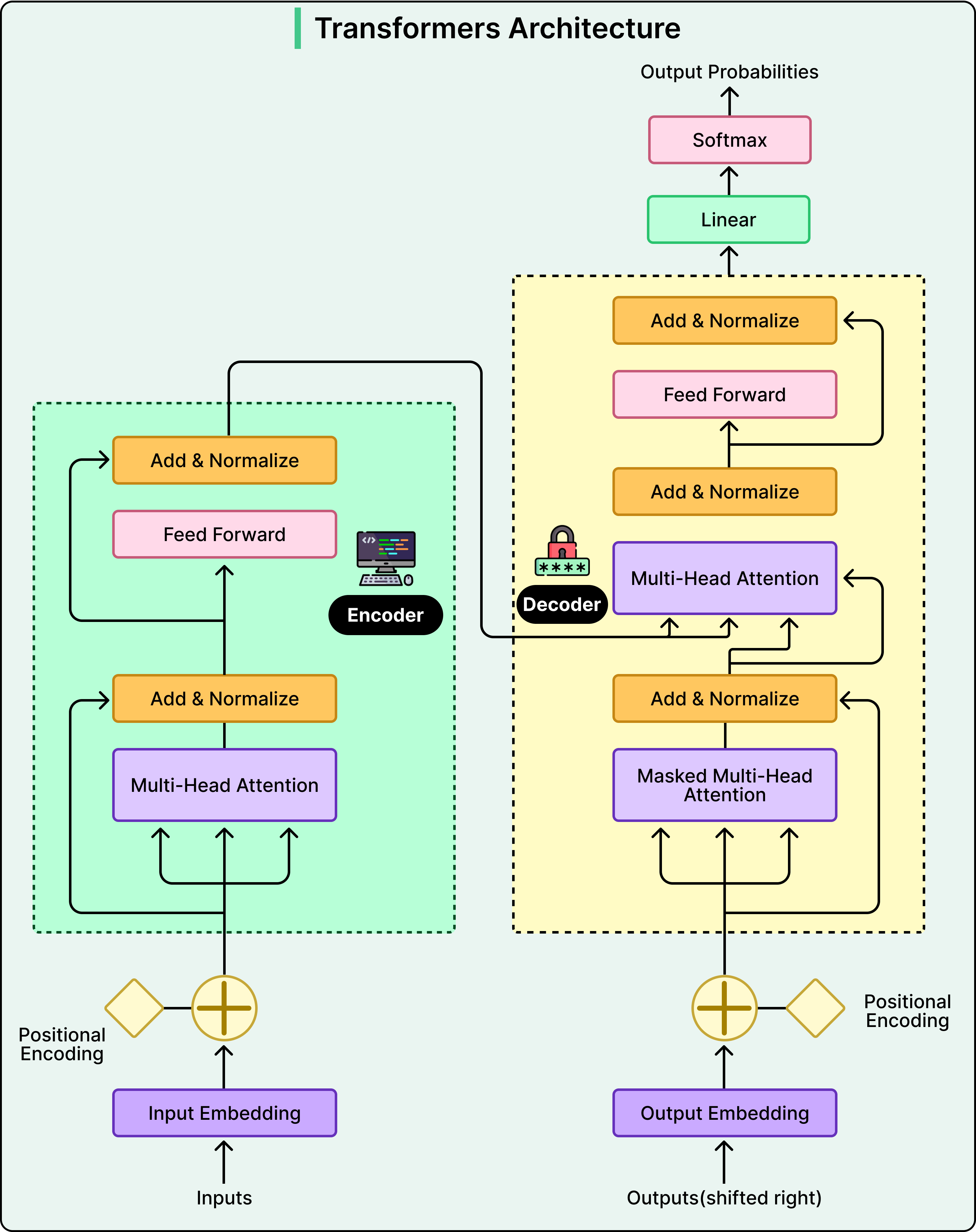
LinkedIn built a Generative Recommender (GR) model that treats your interaction history as a sequence and processes more than a thousand of your past interactions to understand temporal patterns. If you engage with machine-learning content on Monday, distributed-systems content on Tuesday, and open LinkedIn again on Wednesday, a sequential model sees these as the continuation of a learning trajectory, not three independent decisions.
The GR model is a transformer with causal attention — meaning each position in your history can only attend to previous positions, mirroring how you actually experienced the content over time. Recent posts often dominate the prediction, but a post from two weeks ago can suddenly become relevant if today's activity suggests renewed interest in that topic.
A key design decision is late fusion. Not every feature deserves expensive self-attention. Count features and affinity signals carry strong signal on their own, and pushing them through the transformer would inflate cost quadratically for little benefit. So those features are concatenated with the transformer's output after sequence processing — you get rich sequential understanding from the transformer plus extra context signals, without paying transformer cost on signals that don't need it.
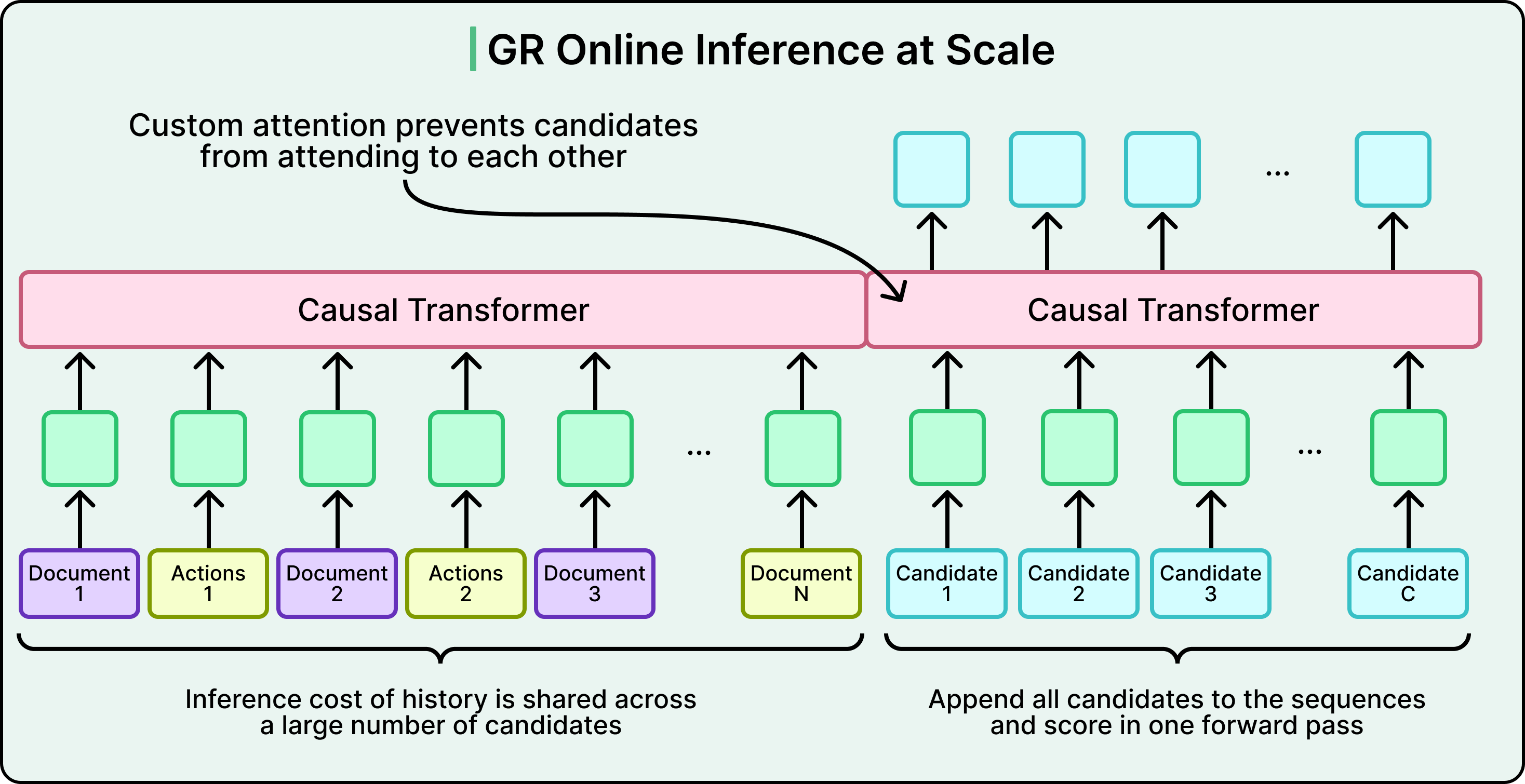
Even with that, running 1,000+ historical interactions through multiple transformer layers for every ranking request is brutal. The serving trick is shared context batching: compute the user's history representation once, then score all candidate posts in parallel using custom attention masks. You pay the expensive part once per request instead of per candidate.
On top of the transformer sits a Multi-gate Mixture-of-Experts (MMoE) prediction head. Mixture-of-Experts is the idea that you have several specialized sub-networks ("experts"), and a small "gate" network decides which experts to use for a given input. Here, MMoE routes the predictions for clicks, likes, comments, and shares through specialized gates — each engagement type gets its own expert mix — but they all share the same underlying sequential representation. So the model handles four prediction tasks without paying four times for the expensive transformer step.
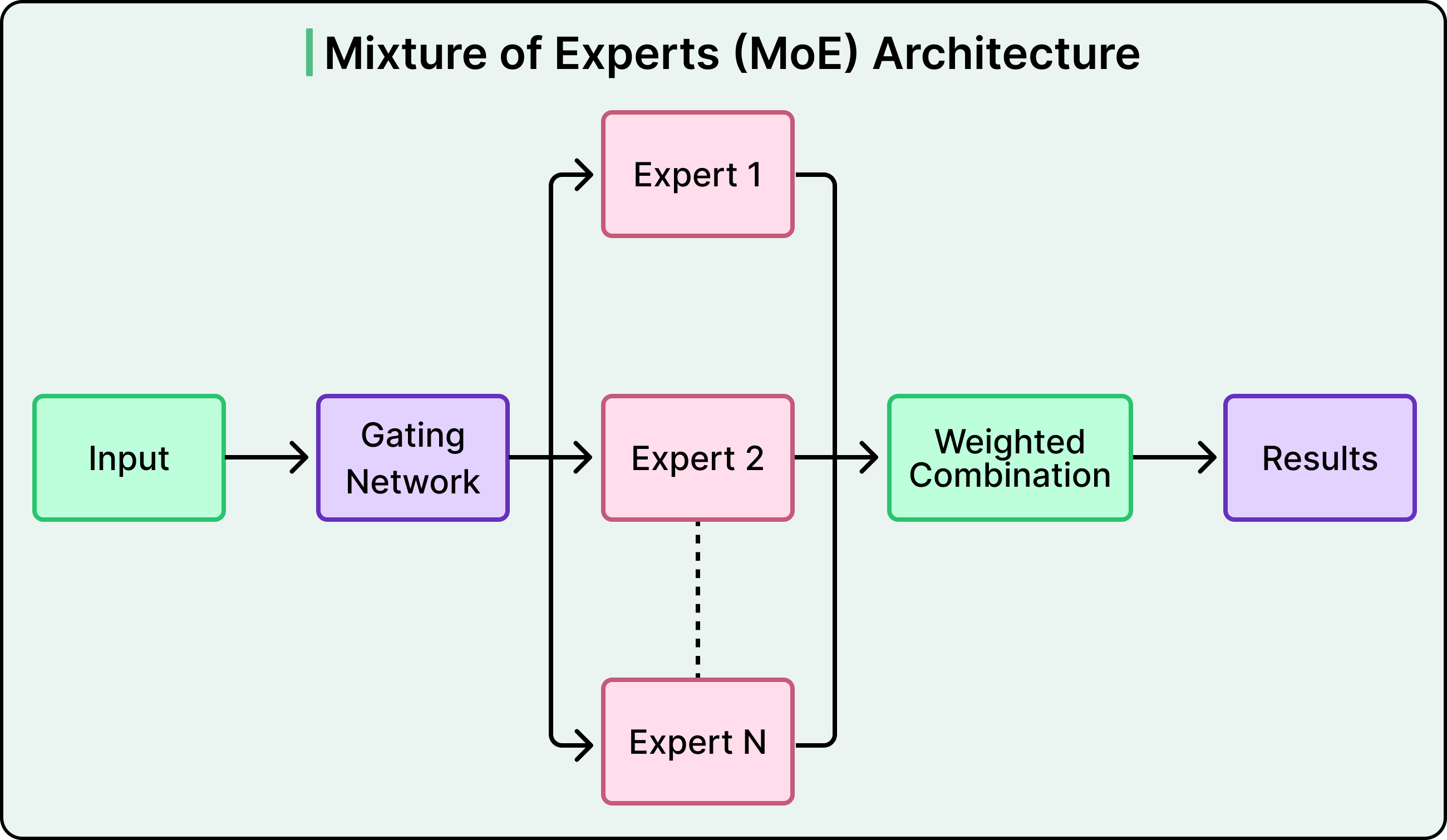
Together, shared context batching and the MMoE head are what make a sequential transformer model viable at production scale.
Making it all work at scale
Even the best model is useless without the infrastructure to serve it. LinkedIn's old ranking models ran on CPUs. Transformers are fundamentally different — self-attention scales quadratically with sequence length, and the parameter counts demand GPU memory. At 1.3 billion users, cost-per-inference is what determines whether sophisticated AI can serve everyone or only your most active members.
So the team built a lot of custom infrastructure on both training and serving sides:
- Training side: A custom C++ data loader eliminates Python's multiprocessing overhead. Custom GPU routines turned metric computation from a bottleneck into negligible overhead. Parallelized evaluation across all checkpoints cut pipeline time substantially.
- Serving side: A disaggregated architecture separates CPU-bound feature processing from GPU-heavy model inference (so the right hardware does the right work). A custom Flash Attention variant called GRMIS delivered an additional 2× speedup over PyTorch's standard implementation.
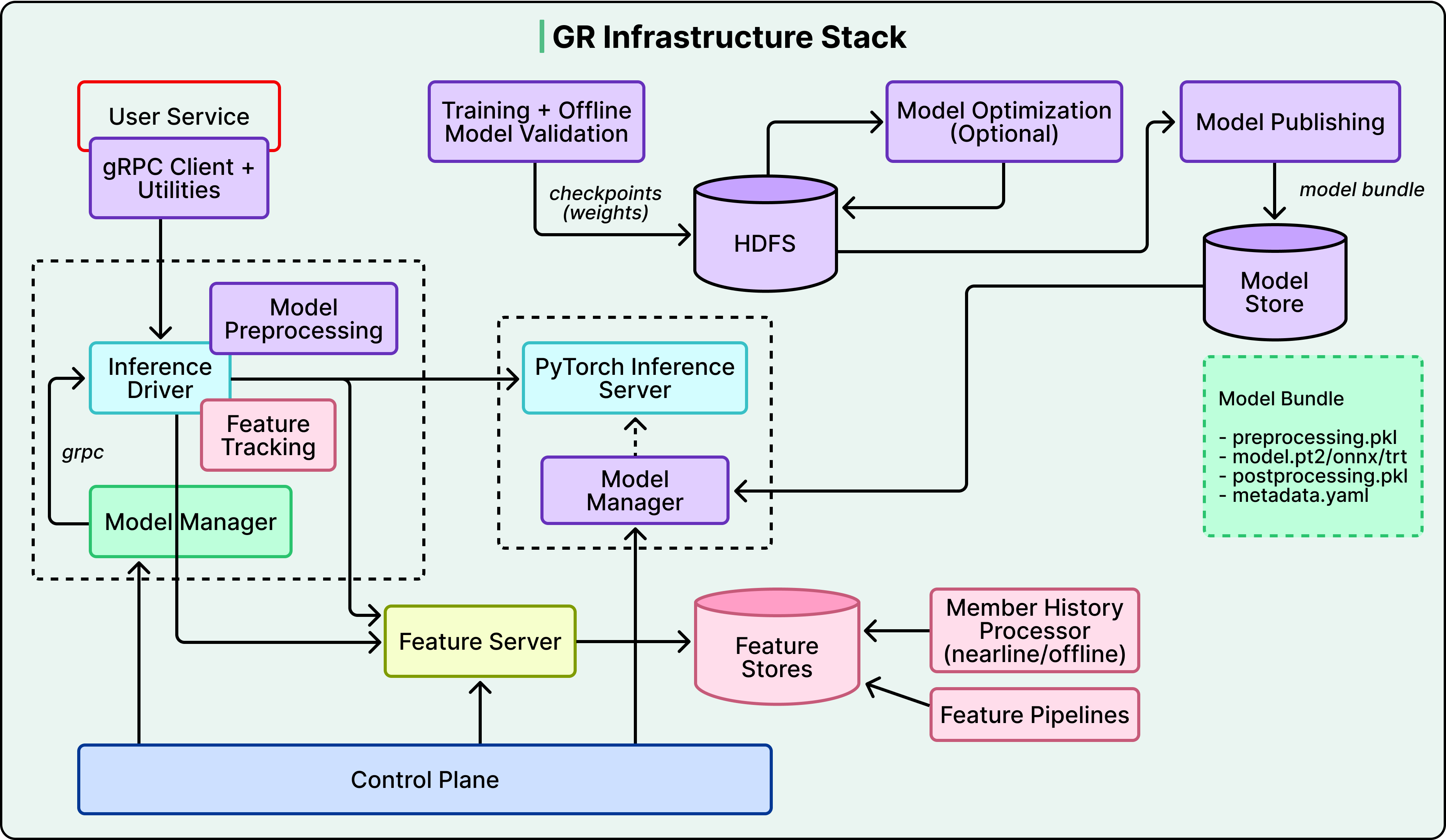
Freshness is its own problem — LinkedIn is real-time, and embeddings get stale. Three continuously running background pipelines keep the system current: one captures new platform activity, another generates updated embeddings via LLM inference servers, and a third ingests them into a GPU-accelerated index. Each pipeline tunes independently, but the end-to-end system stays fresh within minutes.
The models are also regularly audited so posts from different creators compete on equal footing, with ranking based on professional signals and engagement patterns — never demographic attributes.
Takeaways
- Consolidating five retrieval systems into one trades resilience for simplicity. The unified system is easier to optimize end-to-end, but you lose the natural redundancy and independent rollback paths the five-system setup gave you.
- LLM-based embeddings are richer but more expensive than lightweight alternatives — they pay off when your platform is text-heavy and world-knowledge actually helps.
- The bottleneck is rarely the model architecture. It's everything around it — prompt design, numerical encoding, training data filtering, serving infrastructure, freshness pipelines.
- The infrastructure investment is hard to replicate. Custom C++ loaders, custom Flash Attention kernels, disaggregated CPU/GPU serving, and GPU-accelerated indexes are not off-the-shelf.
- This approach leans on LinkedIn's rich text data. For a primarily visual platform, the calculus would be different.
The next time you open LinkedIn and see a post from someone you don't follow, on a topic you didn't search for, but it's exactly what you needed to read — that's all of the above working together under the hood.
Reference: Engineering the next generation of LinkedIn's Feed
Author
ByteByteGo
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m