ByteByteGo Newsletter
A Guide to Relational Database Design — The Thinking Before the SQL
ByteByteGo (Alex Xu)
Apr 27, 2026
A Guide to Relational Database Design — The Thinking Before the SQL
Source: ByteByteGo Newsletter · Author: ByteByteGo (Alex Xu) · Published: April 16, 2026 · Original: blog.bytebytego.com
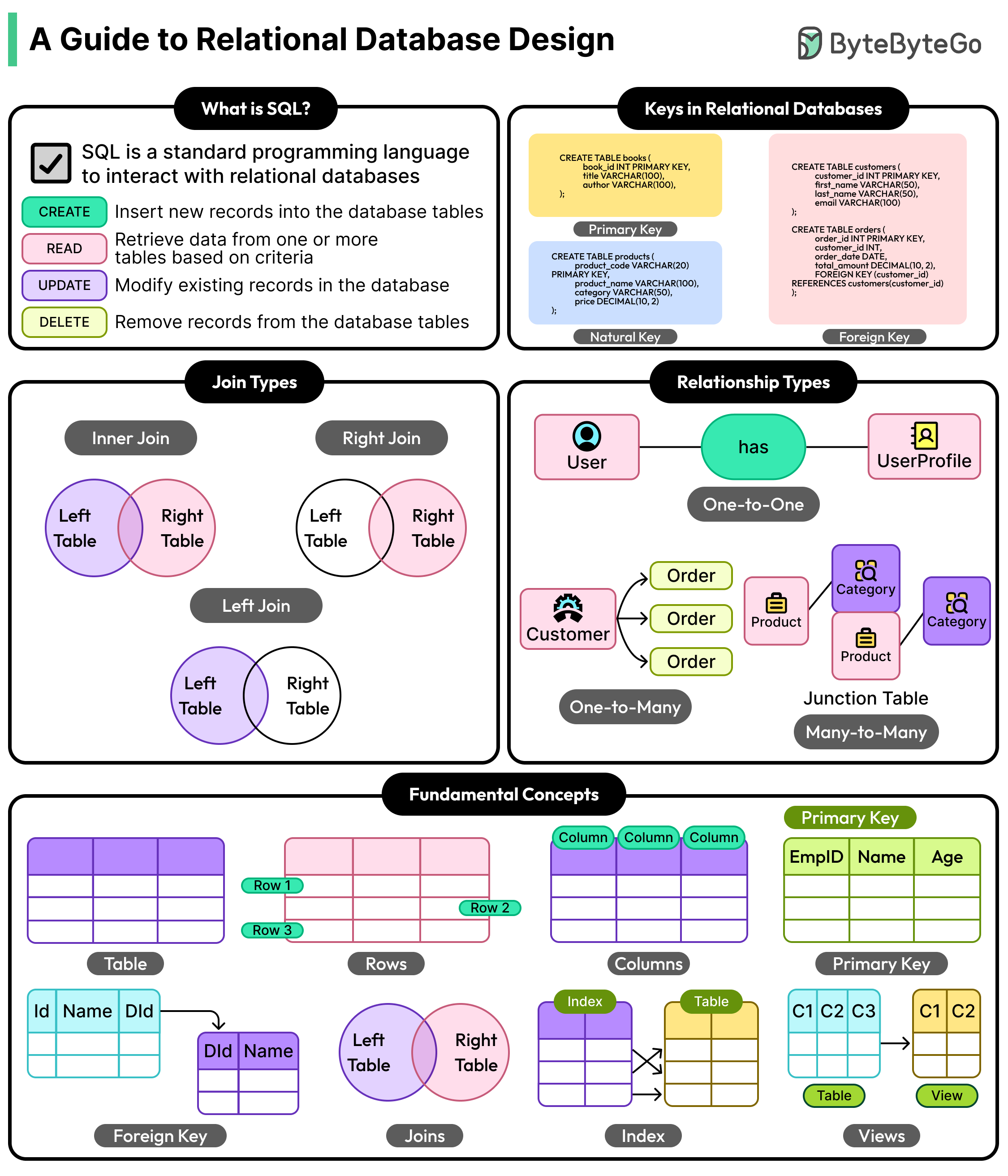
⚠️ Note on scope: The full body of this ByteByteGo post is behind a paywall. Only the introduction and the article's outline were accessible at fetch time. The summary below faithfully captures the framing and promised structure of the piece. The deep dives into each concept (tables, keys, relationships, normalization, joins) are not summarized here because the source text was not available.
The core idea: the hard part of database design isn't SQL
The author opens with a claim that's worth sitting with for a moment, because it reframes how most engineers approach databases.
When you start working with a relational database, it feels like the difficulty lives in the syntax — CREATE TABLE, PRIMARY KEY, JOIN ... ON ..., foreign key constraints, indexes. That syntax is real, and it does take time to learn, but it's a learnable skill: you read the docs, you write a few queries, you make mistakes, you improve. Eventually it becomes muscle memory.
The genuinely hard part — the part that separates a database that ages well from one that becomes a liability — happens before any SQL is written. It's the thinking that produces the schema in the first place. The author frames this as a small set of deceptively simple questions:
- Which pieces of information deserve their own table?
Should a customer's shipping address live as columns on the
customerstable, or as its ownaddressestable? Shouldorder_statusbe a string column or a separate lookup table? These look like style choices, but they cascade. - How should tables reference each other? Foreign keys, junction tables for many-to-many relationships, optional vs. required references — every choice here encodes assumptions about the real world ("a user has exactly one profile" vs. "a user can have many profiles over time").
- How much redundancy is too much? A pure normalized design eliminates duplication, but at the cost of more joins and sometimes slower reads. A denormalized design is fast to query but can drift into inconsistency (the same fact stored in two places, only one of which gets updated). There's no universal right answer — only the right answer for your workload.
Why it matters: design decisions are sticky
The author's central warning is about the cost of getting these decisions wrong. Schema is one of the most expensive things to change in a running system: data has already been written into the existing shape, application code already assumes it, reports already query it, and migrations on large tables can take hours and require downtime or careful online-migration tooling.
So the framing is:
- Right design → data stays consistent (no contradictory copies of the same fact), queries stay fast (the indexes and joins you need are natural), and future changes are painless (adding a feature means adding a column or a table, not reshaping everything).
- Wrong design → months of patching problems that were "baked into the structure from day one." The bugs aren't really bugs — they're the structure leaking through.
The mental model worth taking away: schema is a contract with your future self. SQL is just how you write the contract down.
What the full article promises to cover
The introduction lays out the curriculum the rest of the post walks through, with each concept building on the previous one:
- Tables and the language that drives them — the basic unit (a table = a set of rows with the same shape) and the SQL surface that manipulates it.
- Keys — primary keys (the unique identifier for a row), foreign keys (a row's reference to a row in another table), and the difference between natural keys (something already meaningful, like an email) and surrogate keys (an opaque ID like a
BIGSERIALor UUID). - Relationships — one-to-one, one-to-many, and many-to-many, and how each is physically modeled (a foreign key column vs. a junction/join table).
- Normalization — the discipline of removing redundancy by splitting tables so each fact lives in exactly one place (the classic 1NF / 2NF / 3NF progression), and the trade-offs of denormalizing for performance.
- Joins — how queries reassemble the data the schema split apart, and why normalization and join performance are two sides of the same coin.
The author's promise is that by the end, the reader has the thinking framework — not just syntax — to answer the three opening questions for their own system.
Summary ends here because the remainder of the article is paywalled. To read the full deep dives on tables, keys, relationships, normalization, and joins, see the original post.
Author
ByteByteGo (Alex Xu)
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m