ByteByteGo Newsletter
The Security Architecture of GitHub Agentic Workflow
ByteByteGo
Apr 20, 2026
The Security Architecture of GitHub Agentic Workflow
Source: ByteByteGo Newsletter · Author: ByteByteGo · Date: 2026-04-20 · Original: blog.bytebytego.com
GitHub built an AI agent that can fix docs, write tests, and refactor code while you sleep — and then designed its entire security architecture around the assumption that this agent might try to steal your API keys, spam your repository with garbage, and leak your secrets to the internet. That sounds paranoid, but it's the only responsible way to drop a non-deterministic system into a CI/CD pipeline.
GitHub Agentic Workflows let you plug AI agents into GitHub Actions so they can triage issues, generate pull requests, and handle routine maintenance without human supervision. The appeal is obvious; so is the risk. These agents consume untrusted inputs (issue comments, web pages, PR bodies), make decisions at runtime, and can be manipulated through prompt injection — carefully crafted text hidden in those inputs that tricks the agent into doing things it wasn't supposed to do. This summary walks through GitHub's architecture, which assumes the agent is already compromised, and explains why that assumption changes everything.
Why Agents Break the CI/CD Contract
Traditional CI/CD pipelines rest on one quiet assumption: developers define the steps, the system runs them, and every execution is predictable. All components in a pipeline live inside a single trust domain — they share secrets, see the same files, and hit the same network. For deterministic scripts, that shared environment is a feature: it makes things composable and fast. A traditional CI step either does exactly what you coded it to do, or it fails.
Agents shatter that contract. They don't follow a fixed script. They reason over repository state, consume inputs they weren't specifically designed for, and make decisions at runtime. An agent might do something you never anticipated — especially if the input was crafted to manipulate it.
GitHub's threat model is blunt: assume the agent will try to read and write state it shouldn't, communicate over unintended channels, and abuse legitimate channels for unwanted actions. A concrete scenario: a prompt-injected agent with shell access can read configuration files, SSH keys, and Linux /proc state to discover credentials, scan workflow logs for tokens, then encode those secrets into a public-facing GitHub object — say, an issue comment or a PR description — for an attacker to fish out later. The agent isn't actively malicious; it just can't tell legitimate instructions from malicious ones smuggled inside the data it's reading.
In a standard GitHub Actions setup, everything runs in the same trust domain on a runner VM. A rogue agent in that world could interfere with MCP servers (the tools that extend what an agent can do), read auth secrets from environment variables, and call out to arbitrary hosts. One compromised component gets access to everything. The point isn't that Actions are insecure — they aren't. The point is that agents invalidate the assumption that made a shared trust domain safe in the first place.
Three Layers of Distrust
GitHub's response is a layered architecture with three independent levels, where each layer contains the damage if the layer above it fails.
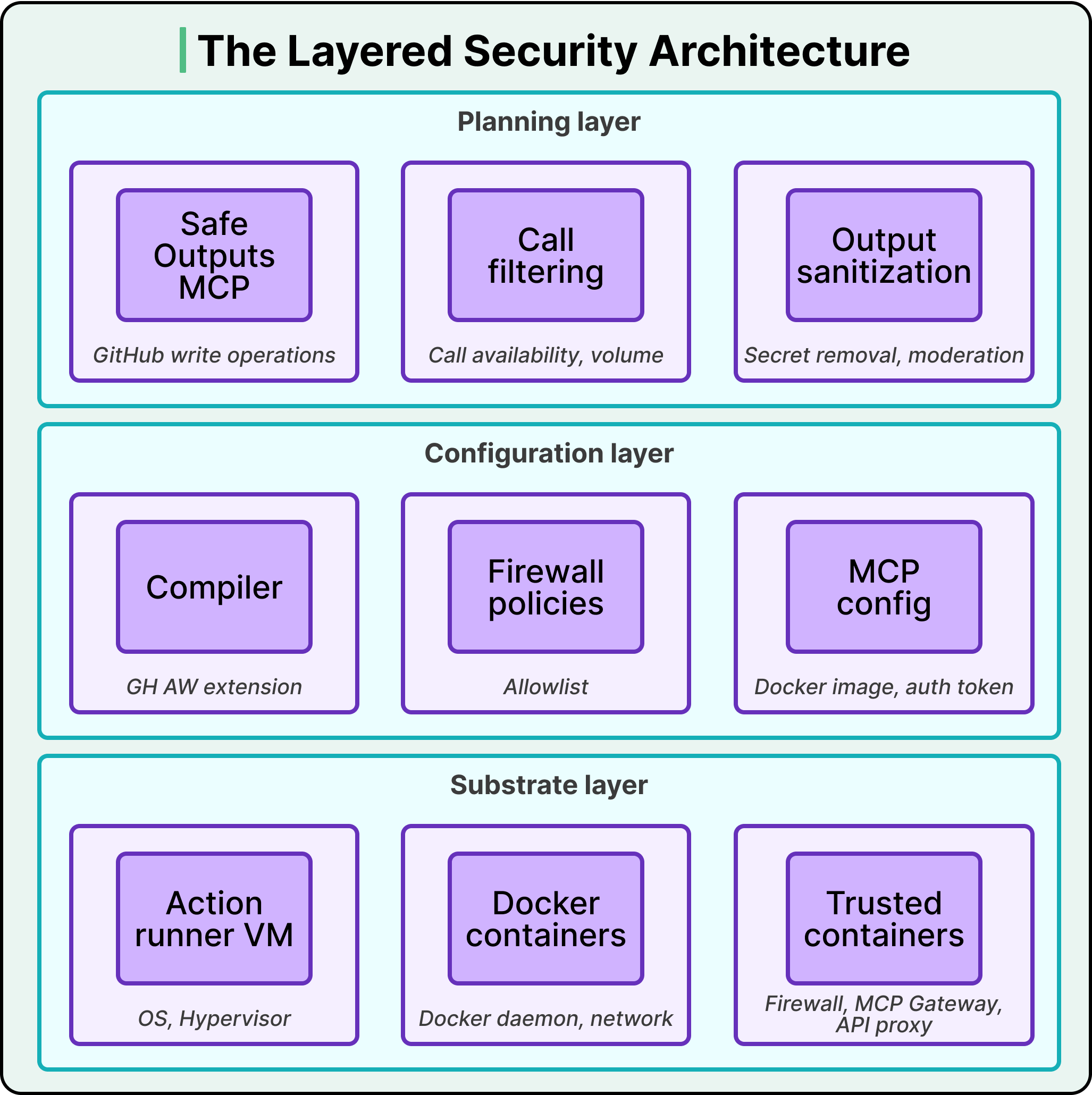
-
Substrate layer (bottom). Built on a GitHub Actions runner VM plus several Docker containers, including trusted containers that mediate privileged operations. This layer enforces isolation, controls system calls, and sets kernel-level communication boundaries. These protections hold even if an untrusted component is fully compromised and runs arbitrary code inside its container — the agent's code execution hits a wall here.
-
Configuration layer (middle). This is where structure is defined: declarative artifacts and toolchains that decide which components are loaded, how they're connected, what channels are permitted, and what privileges each gets. The key piece is the compiler: GitHub doesn't just run your workflow definition as-is — it compiles it into a GitHub Action with explicit constraints on permissions, outputs, auditability, and network access. The configuration layer also decides which secrets go into which containers. Externally minted tokens (agent API keys, GitHub access tokens) are loaded only into the specific containers that need them — never into the agent's container.
-
Planning layer (top). Where configuration says which components exist and how they communicate, planning says which components are active over time. It builds staged workflows with explicit data exchanges between stages. The safe outputs subsystem (covered below) is the most important instance — it ensures the agent's work gets reviewed before it affects anything real.
The layers are deliberately independent. If the planning layer fails, configuration still enforces its constraints. If configuration has a bug, the substrate still provides isolation. No single failure compromises the whole system.
Not Trusting Agents With Secrets
GitHub's first principle: the agent gets zero access to secrets, full stop.
In a stock GitHub Actions setup, sensitive material — agent auth tokens, MCP server API keys — sits in environment variables and config files visible to every process on the runner VM. Fine when everything is trusted. Catastrophic with agents, because an attacker can hide malicious instructions in a web page, an issue, or a PR comment, and trick the agent into extracting and leaking whatever it can find.
The solution is a specific container topology that makes secrets physically unreachable from the agent:
- The agent runs in its own Docker container on a private network.
- All internet access goes through a dedicated firewall container (
gh-aw-firewall). - MCP tools are accessed through a separate trusted MCP gateway (
gh-aw-mcpg), which launches MCP servers and holds exclusive access to MCP auth material like the GitHub Personal Access Token. - LLM API calls go through an isolated API proxy that holds the model's auth token (e.g., the Codex token).
- The agent talks to the firewall over HTTP, the firewall to the MCP gateway over HTTP, and the gateway to MCP servers over stdio.
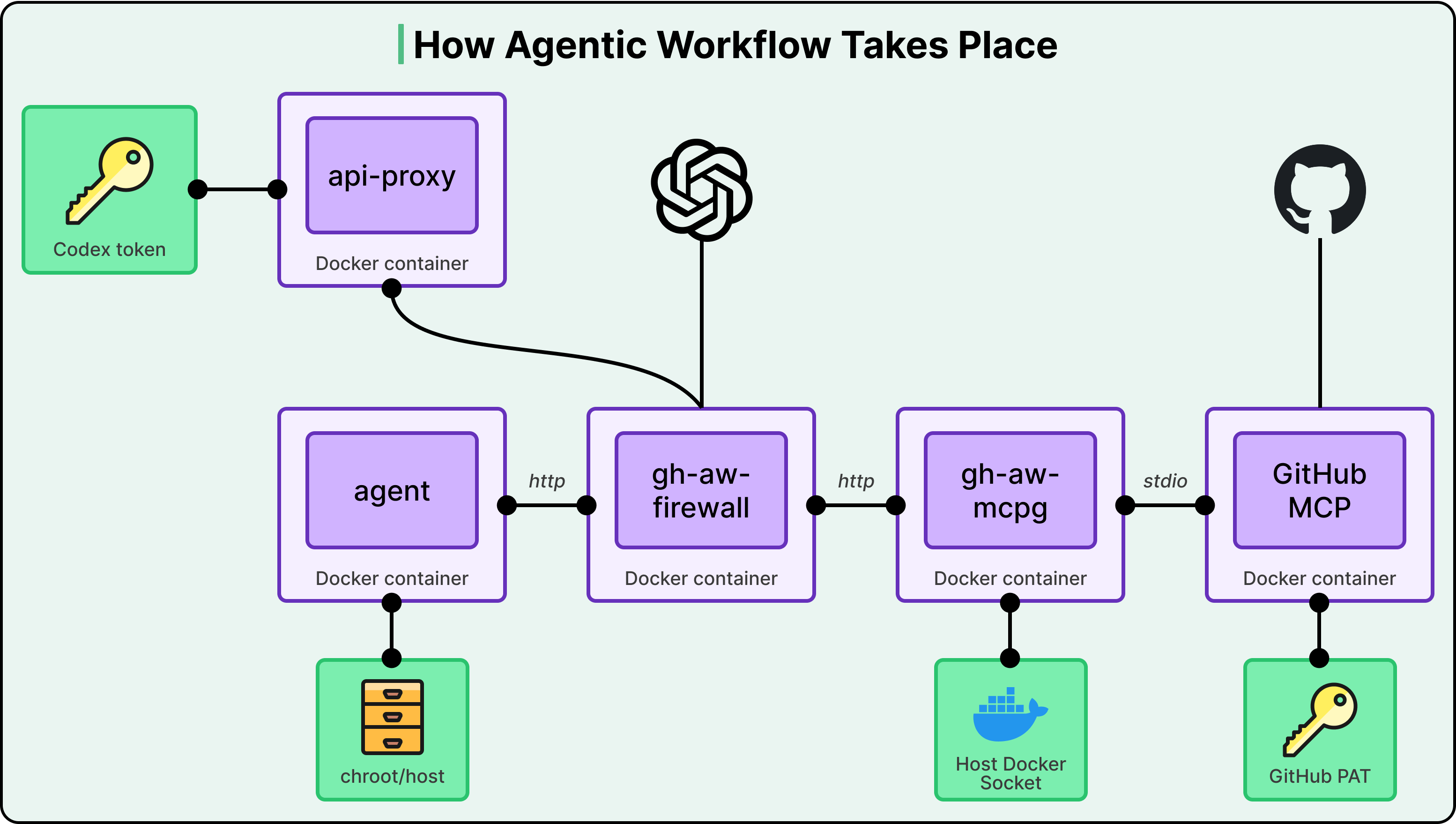
At no point in this chain does the agent touch a secret. It can make LLM calls because the proxy adds authentication on its behalf. It can use MCP tools because the gateway authenticates on its behalf. The agent itself is completely secretless.
There's a real tension here, and GitHub names it: coding workloads need broad access to compilers, interpreters, scripts, and repository state. You can't just install all of that inside the agent's container without expanding the firewall's allowed destinations and duplicating a ton of host setup. Their resolution is elegant:
- Mount the entire VM host filesystem read-only at
/hostinside the agent's container. - Overlay sensitive paths (the ones with secrets and config) with empty
tmpfslayers — temporary in-memory filesystems that effectively hide whatever was at those paths. - Launch the agent in a chroot jail rooted at
/host.
Net effect: the agent sees every compiler, interpreter, and tool on the host machine, but cannot discover any secret material. The host stays intact; the agent's writable and discoverable surface is exactly what it needs and no more. If you work with containers, the pattern of mount host read-only + mask sensitive paths with tmpfs generalizes well beyond agents.
GitHub isn't alone here. OpenAI's Codex arrives at the same place by a different road: in Codex cloud, secrets are available only during a setup phase and removed before the agent phase begins, with internet access disabled by default during execution. GitHub uses proxies and gateways; OpenAI uses a two-phase model. Two independent teams converging on "agents should never touch secrets" is itself a strong validation of the principle.
Every Output Gets Vetted
Stripping the agent of secrets doesn't eliminate harm. A prompt-injected agent can still spam a repo with pointless issues and PRs to drown maintainers, or inject objectionable URLs and content into repository objects. Absence of secrets ≠ absence of risk.
GitHub's answer is the safe outputs system — the most distinctive piece of the architecture.
- The agent reads GitHub state through the GitHub MCP server in read-only mode. It cannot write to GitHub directly.
- All write operations go through a separate safe output MCP server, which only buffers the agent's intended changes — it doesn't execute them.
- When the agent finishes and exits, everything it staged runs through a deterministic analysis pipeline, which does three things:
- Type allowlist check. The workflow author declared up front what kinds of operations are allowed (e.g., create issues and comments, but not pull requests). Anything off the list is dropped.
- Quantity limits. An agent might be capped at, say, three pull requests per run.
- Content sanitization. Scan for secrets that might have leaked into output text, strip URLs, and run content moderation checks.
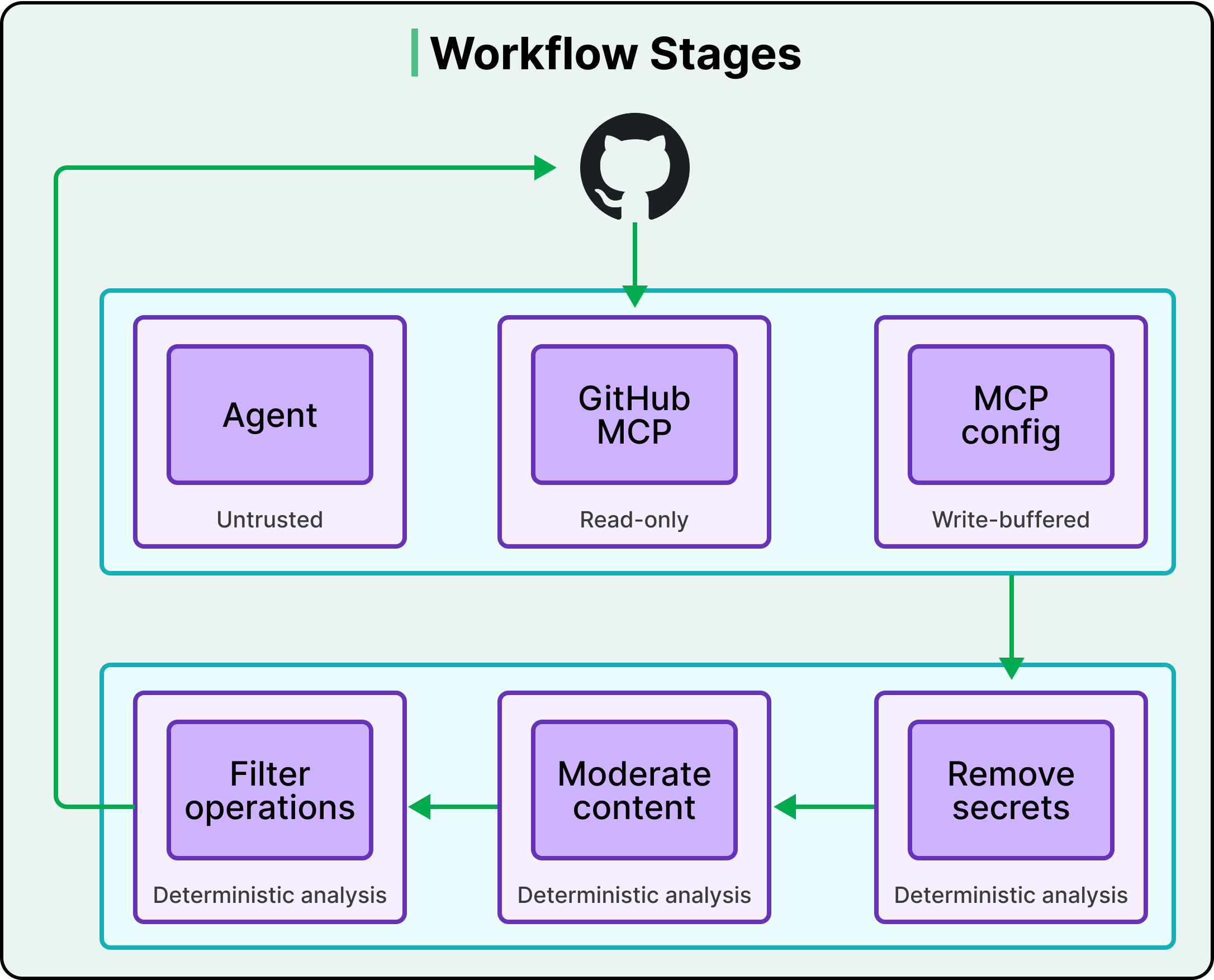
Only outputs that survive the entire pipeline get committed to GitHub. Every stage's side effects are explicit and vetted.
The compiler plays its part again here: when it decomposes a workflow into stages, it defines for each stage the active components and their permissions (read vs. write), the data artifacts that stage may emit, and which downstream consumers are allowed to read those artifacts. The author declares what the agent may produce, and the system enforces those declarations deterministically.
The honest catch: deterministic analysis can only catch patterns GitHub anticipated. A truly novel attack might slip through — which is exactly why the other layers exist. No single layer is the complete answer.
The Logging Strategy
Agents are determined to accomplish their tasks by any means available, and they have a surprisingly deep toolbox of tricks. When one behaves unexpectedly, you need full visibility into what happened. Agentic Workflows make observability a first-class architectural property by logging at every trust boundary:
- Firewall records network and destination-level activity.
- API proxy captures model request/response metadata and authenticated requests.
- MCP gateway and MCP servers log tool invocations.
- Internal instrumentation in the agent container audits potentially sensitive actions like environment variable accesses.
Together, these logs support full forensic reconstruction, policy validation, and anomaly detection.
The longer-term play is more important: every point where you can observe communication is also a point where you can mediate it. GitHub is building the observation infrastructure now with future control in mind. They already support a lockdown mode for the GitHub MCP server, and they plan to add controls that enforce policies across MCP servers based on whether repository objects are public or private, and based on who authored them. Today's logs are tomorrow's policy enforcement points.
The Trade-Offs
Every security decision has a cost, and the article doesn't dodge them.
- Security vs. utility. Agents inside GitHub's architecture are more constrained than a developer working locally. The chroot trick gives broad access to host tools, but the firewall still limits network access and the safe outputs pipeline still restricts what the agent can produce. More security, less flexibility.
- Strict-by-default is an opinion. Most other coding agents make sandboxing opt-in — Claude Code and Gemini CLI both require you to turn on sandbox features. GitHub Agentic Workflows run in strict security mode by default. That's a deliberate choice to prioritize safety over developer convenience, and it won't be the right tradeoff for every use case.
- Prompt injection is fundamentally unsolved. This architecture is a damage containment strategy, not a prevention strategy. It limits the blast radius when an agent gets tricked, but it can't stop the trickery itself. And deterministic vetting in safe outputs only catches anticipated patterns — a novel vector might require a new pipeline stage.
- Complexity. Multiple containers, proxies, gateways, a compilation step, a staged output pipeline. This is engineering overhead that makes sense at GitHub's scale; for simpler use cases, you may not need every piece.
Conclusion: Four Transferable Principles
As AI agents become standard in development tooling, the question shifts from whether to sandbox to how to build a complete security architecture. GitHub's four principles travel well beyond their specific implementation:
- Defend in depth with independent layers. Substrate, configuration, and planning each enforce their own properties so no single failure compromises everything.
- Keep agents away from secrets by architecture, not policy. Use proxies, gateways, chroot jails, and tmpfs masks so the agent literally cannot reach what it shouldn't have. Don't rely on the agent behaving well.
- Vet every output through deterministic analysis before it affects the real world. Buffer writes, then check type allowlists, quantity limits, and content sanitization before anything is committed.
- Log everything at every trust boundary — because today's observability is tomorrow's control plane.
Reference: Under the hood: Security Architecture of GitHub Agentic Workflows
Author
ByteByteGo
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m