The AI Corner
The 20-Agent Machine That's Minting Millionaires
Ruben Dominguez
Apr 20, 2026
The 20-Agent Machine That's Minting Millionaires
Source: The AI Corner • Author: Ruben Dominguez • Date: 2026-04-20 • Original article
How three young creatives built a Claude Code–powered script factory that drove $10M+ in client revenue, and what it really teaches us about where AI is headed.
We've all seen the generic, robotic AI content flooding the internet — the kind that sounds fine but never makes you stop scrolling. The story in this issue is about three creators (Mitchell Rusitzky, Matt Epstein, and Alejandro Tamayo, operating as Shown Media) who stopped treating Claude like a chatbot and started treating it like a strict production line. Inside a Claude Code terminal, they wired up roughly twenty specialized AI agents that quietly produced launch videos generating tens of millions of views and over $10M in client revenue.
The interesting part isn't a "magic prompt." It's that they took years of real video-production judgment and hard-coded their standards into an automated assembly line: every agent has one job, and nothing moves forward until it passes a ruthless quality check.
1. The Operators Behind the Machine
What these three share isn't an interest in AI — it's a shared standard for what high-performing content actually looks like, formed long before this system existed. They've worked in environments where output is judged by distribution, retention, and conversion, not whether something "sounds good."
Each brings a different layer of that discipline:
- Mitchell is the systems builder. He translates production logic into something structured enough to run inside a multi-agent environment.
- Matt went from Cornell into building performance-driven content that generated millions in revenue. He anchors the system in what actually converts, not just what gets attention.
- Alejandro comes from the YouTube ecosystem, working alongside major creators. That sharpens instinct around pacing, hooks, and audience retention in a way no prompt library can replicate.
 Mitchell Rusitzky. Emmy winner. Builder of the system.
Mitchell Rusitzky. Emmy winner. Builder of the system.
The Emmy wins matter here not as credentials, but as evidence of production judgment at a level where small quality differences compound. The system they built reflects that background: it doesn't invent taste, it encodes it. That distinction carries more weight than it first appears — the model isn't being asked to be creative, it's being asked to consistently apply rules made by people who already know what wins.
2. Why Single-Prompt AI Doesn't Work for Real Tasks
Most people use AI for creative work the simplest way possible: open a model, type a prompt, get a draft, edit a bit, ship it. For lightweight tasks, fine. But when the script has to hold attention, carry a sales argument, and stand up to real audience scrutiny, that workflow collapses.
One prompt, too many jobs
A single prompt smashes research, ideation, drafting, editing, and judgment into one blurred step. The model has to decide simultaneously:
- what to study,
- which patterns matter,
- how to structure the argument,
- where the hook should land,
- what to cut, and
- whether the result is good enough to publish.
In effect, it's generating and evaluating its own work at the same time — which no serious creative organization does, for good reason. (And on top of that, recent reports of Claude's fluctuating performance show you can't even trust the model's baseline intelligence on any given day.)

Structure is the problem, not the model
In a disciplined content team, those functions are separated:
- Research identifies what's already working in the market.
- Writing turns those inputs into a draft.
- Editing sharpens structure and pacing.
- Review checks whether the piece clears the actual standard.
Each role demands a different kind of judgment. Compress them into one AI call and the output reads fluently but feels generic — weak hooks, recycled framing, vague claims, borrowed rhythm, no internal resistance. That's why so much AI content feels finished without feeling convincing.
The fix isn't a better prompt. It's to stop asking one agent to do everything.
3. Inside the Machine: How the System Actually Works
Quality is enforced, not expected
The system assumes something blunt: the model will produce okay-but-average results unless it is forced to do better. Good quality doesn't just happen — it has to be demanded by the surrounding scaffolding. Reliability is built into the system, not left to chance.
That's what turns this from "AI content setup" into a real production system. Every layer carries a specific responsibility, and each one exists because removing it causes something to break.
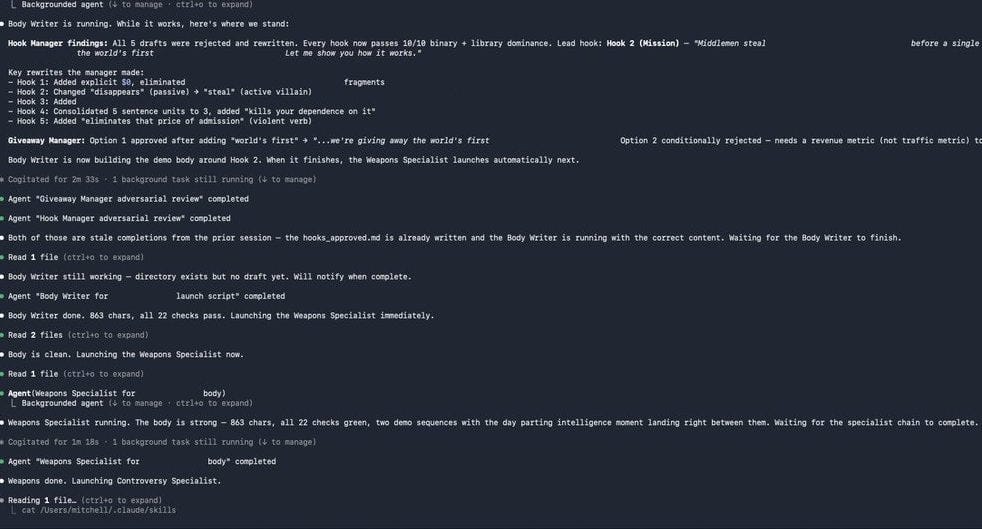 The system running in real time. Each agent completes, then the next launches automatically. (Image: Mitchell on X)
The system running in real time. Each agent completes, then the next launches automatically. (Image: Mitchell on X)
Every layer earns its place
The pipeline has four layers, each doing exactly one thing:
- The orchestrator manages the entire process, making sure things happen in the right order and only after approval.
- The research phase sets the ceiling — it defines what "good" looks like before a single word is written. Without it, the system has no reference point and the work becomes generic by default.
- Specialized agents (Hook Manager, Body Writer, Weapons Specialist, etc.) execute within tightly defined constraints. Narrow scope per agent prevents the scope creep that dilutes output.
- Manager agents evaluate what the specialists produce — applying judgment exactly where judgment is most needed (comparing options, picking the strongest direction).
- The final "weapons check" gate enforces the published standard. Without it, weak drafts slip through dressed as finished work.
Strip any layer out and the degradation is immediate and specific:
- No research → no ceiling, output drifts to average.
- No specialization → roles blur, accountability breaks down.
- No evaluation → weak drafts move forward unchecked.
- No final gate → the system has motion but no integrity.
What's left isn't a clever prompt. It's a clear process that treats generation as the start of quality control, not the end. The system does not trust the model to be good — it builds conditions where good output is the only viable outcome.
4. What the Results Actually Mean
The headline numbers — tens of millions of views, eight-figure revenue impact, consistent performance across launches — are easy to repeat. But the figures alone don't explain much.
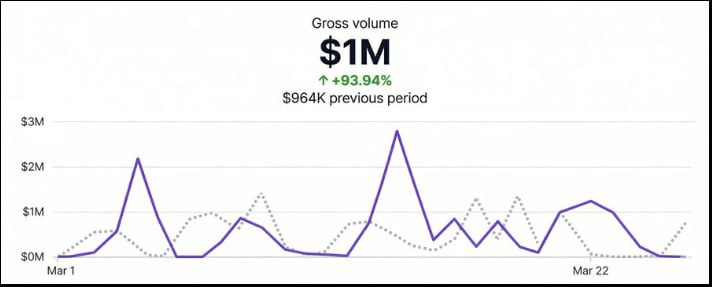 Client revenue. $1M gross volume. Up 93.94% on the previous period.
Client revenue. $1M gross volume. Up 93.94% on the previous period.
Some of the outcome clearly comes from things that existed before the system: a team that already understands distribution and audience behavior, clients with existing demand, prior production experience. Strong inputs and strong context shape outcomes in ways no architecture can fully account for.
What experience can't explain
But when you see the same level of output across more than a dozen launches, with different products, audiences, and contexts, it gets harder to attribute it to luck or one good creative call. That's not a streak — that's a pattern. And patterns come from systems, not instincts.
The architecture earns its keep through variance control:
- Research sets a clear competitive ceiling.
- Specialized agents generate multiple directions instead of one pass.
- The manager layer compares and selects rather than accepting the first viable draft.
- The final quality gate blocks anything that fails to meet the defined bar.
Each step adds friction in the right place — not to slow things down, but to stop weak work from slipping through. Seen this way, the system isn't producing better scripts so much as producing fewer bad ones. In a domain where distribution is highly sensitive to small structural differences, that consistency compounds.
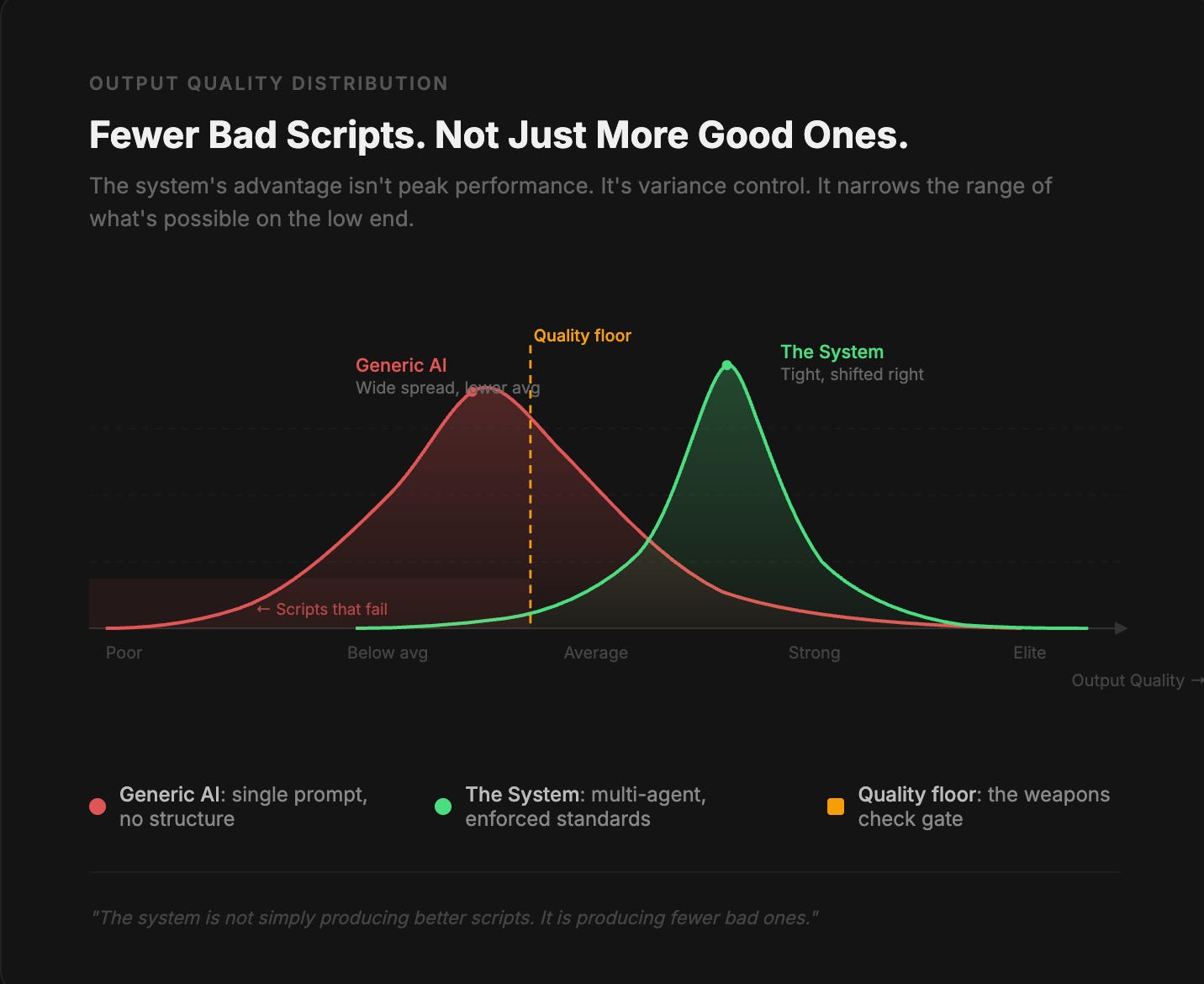 Generic AI spreads wide. The system stays tight. Fewer bad scripts is the whole point.
Generic AI spreads wide. The system stays tight. Fewer bad scripts is the whole point.
5. The Real Lesson Isn't About Agents
It's tempting to look at a coordinated swarm of Claude Code agents and assume the advantage lives at the model layer. The opposite is closer to the truth: the agents are doing relatively narrow tasks. The structure around them is what matters.
The code didn't build the standards
Every critical component reflects decisions that existed before any code was written:
- The research ceiling depends on knowing which patterns are worth studying and which are noise.
- The manager scoring logic depends on understanding what separates a strong hook from an average one.
- The final gate depends on recognizing when something feels derivative, underpowered, or structurally weak.
This aligns with Wharton's "Jagged Frontier" research on AI: models fail without deep human domain expertise guiding them. None of those judgments come from the model. They come from prior experience with content that has already performed in the real world.
The agents aren't discovering what works. They're doing exactly what experienced people told them to do. The system's job is to make those constraints consistent — applying the same standard every time, without fatigue, shortcuts, or attention drift.
The question most builders get wrong
Most people building with these tools are asking the wrong question. They're swapping models, tweaking prompts, chasing better outputs as if the tool is the problem. It usually isn't.
The problem is that nobody wrote down what "good" actually looks like.
If your standard lives only in your head — vague, intuitive, inconsistent — no system will reliably hit it. You'll get something that feels close. Sometimes great. Often just fine. And you won't know why.
What this system forces you to do is different. Before you touch the agents, you have to define your bar:
- What makes a hook work?
- What kills a script in the first ten seconds?
- What's the difference between strong and forgettable?
Write it down. Make it a rule. Make it something a machine can check. Once you do, the model stops being a slot machine and starts being a multiplier.
 Without a standard, you're just pulling the lever and hoping.
Without a standard, you're just pulling the lever and hoping.
 Most builders start at the top. The ones who win start at the bottom.
Most builders start at the top. The ones who win start at the bottom.
6. What Builders Should Take From This
One job. That's it.
Most people's first instinct is to build one agent that does everything. Wrong move. This system works because every agent has exactly one job:
- A hook is judged as a hook.
- An angle competes against other angles before it ever becomes a script.
- Each piece is evaluated on its own terms.
The moment you merge those roles, the pressure disappears — and so does the quality. What looks like efficiency turns into blurred judgment.
Research is where most people quietly cut corners. In normal workflows it's a warmup: gather a few references, get a feel for the space, start writing. In this system, it's the foundation. The ceiling and floor get defined before a single word is generated. A sophisticated setup built on a weak reference point is still a weak setup.
Evaluation is the other place most tools get soft. Most setups treat it as a suggestion — the model flags something, you decide whether to care. Here, it's a hard gate. If output doesn't clear the bar, it doesn't move forward. Full stop. Sounds simple, but compounded over time it's everything: systems that only flag problems slowly fill up with small compromises; systems that block them don't.
This isn't a chatbot you prompt and hope. Tasks run in order. Each one hands off to the next. If something fails, it loops back until it passes. No shortcuts, no skipping steps. That's what makes it actually scale — not a clever demo, a real production system.
 One orchestrator. Every agent knows its role.
One orchestrator. Every agent knows its role.
Complexity is not the point
The real takeaway underneath everything:
The advantage doesn't come from complexity. It comes from making shortcuts hard.
The teams that will get the most out of systems like this aren't the ones who learn to prompt better. They're the ones who already know what good looks like in their domain — and are willing to write it down, lock it in, and let the machine hold the line.

Bottom line for builders: Don't start by picking a model or designing prompts. Start by writing down — explicitly, as rules a machine can check — what "great" looks like in your work. Then assign one tiny job per agent, force every output through a hard quality gate, and refuse to let weak drafts move forward. The model becomes a multiplier of your taste, not a replacement for it.
Author
Ruben Dominguez
Continued reading
Keep your momentum

MKT1 Newsletter
100 B2B Startups, 100+ Stats, and 14 Graphs on Web, Social, and Content
This is Part 2 of MKT1's three-part State of B2B Marketing Report. Where Part 1 looked at teams and leadership , Part 2 turns to what marketing teams are actually doing — what their websites look like, how they use social, and what "content fuel" they're producing. Emily Kramer u
Apr 28 · 10m
Lenny's Newsletter (Lenny's Podcast)
Why Half of Product Managers Are in Trouble — Nikhyl Singhal on the AI Reinvention Threshold
Nikhyl Singhal is a serial founder and a former senior product executive at Meta, Google, and Credit Karma . Today he runs The Skip ( skip.show (https://skip.show)), a community for senior product leaders, plus offshoots like Skip Community , Skip Coach , and Skip.help . Lenny de
Apr 27 · 7m

The AI Corner
The AI Agent That Thinks Like Jensen Huang, Elon Musk, and Dario Amodei
Dominguez opens with a claim that is easy to skim past but worth stopping on: the difference between elite founders and everyone else is not raw IQ or speed — it is that each of them has internalized a repeatable mental procedure they run on every important decision. The procedur
Apr 27 · 6m